

Update (October 2024): In response to numerous requests from external developers, we have open-sourced a version of our Enzyme to React Testing Library (RTL) conversion tool. You can now find it on npm, along with detailed instructions on how to integrate and use it in your projects.
In the world of frontend development, one thing remains certain: change is the only constant. New frameworks emerge, and libraries can become obsolete without warning. Keeping up with the ever-changing ecosystem involves handling code conversions, both big and small. One significant shift for us was the transition from Enzyme to React Testing Library (RTL), prompting many engineers to convert their test code to a more user-focused RTL approach. While both Enzyme and RTL have their own strengths and weaknesses, the absence of native support for React 18 by Enzyme presented a compelling rationale for transitioning to RTL. It’s so compelling that we at Slack decided to convert more than 15,000 of our frontend unit and integration Enzyme tests to RTL, as part of the update to React 18.
We started by exploring the most straightforward avenue of seeking out potential Enzyme adapters for React 18. Unfortunately, our search yielded no viable options. In his article titled “Enzyme is dead. Now what?“, Wojciech Maj, the author of the React 17 adapter, unequivocally suggested, “you should consider looking for Enzyme alternative right now.”

Considering our ultimate goal of updating to React 18, which Enzyme does not support, we started with a thorough analysis of the problem’s scope and ways to automate this process. Our initiative began with a monumental task of converting more than 15,000 Enzyme test cases, which translated to more than 10,000 potential engineering hours. At that scale with that many engineering hours required, it was almost obligatory to optimize and automate that process. Despite thorough reviews of existing tools and extensive Google searches, we found no suitable solutions for this very common problem. In this blog, I will walk you through our approach to automating the Enzyme-to-RTL conversion process. It includes analyzing and scoping the challenge, utilizing traditional Abstract Syntax Tree (AST) transformations and an AI Large Language Model (LLM) independently, followed by our custom hybrid approach of combining AST and LLM methodologies.
Abstract Syntax Tree (AST) transformations
Our initial approach centered around a more conventional way of performing automated code conversions — Abstract Syntax Tree (AST) transformations. These transformations enable us to represent code as a tree structure with nodes and create targeted queries with conversions from one code node to another. For example, wrapper.find('selector'); can can be represented as:

Naturally, we aimed to create rules to address the most common conversion patterns. Besides focusing on the rendering methods, such as mount and shallow, and various helpers utilizing them, we identified the most frequently used Enzyme methods to prioritize the conversion efforts. These are the top 10 methods in our codebase:
[
{ method: 'find', count: 13244 },
{ method: 'prop', count: 3050 },
{ method: 'simulate', count: 2755 },
{ method: 'text', count: 2181 },
{ method: 'update', count: 2147 },
{ method: 'instance', count: 1549 },
{ method: 'props', count: 1522 },
{ method: 'hostNodes', count: 1477 },
{ method: 'exists', count: 1174 },
{ method: 'first', count: 684 },
... and 55 more methods
]One important requirement for our conversion was achieving 100%-correct transformations, because any deviation would result in incorrect code generation. This challenge was particularly pronounced with AST conversions, where in order to create transformations with 100% accuracy we needed to painstakingly create highly specific rules for each scenario manually. Within our codebase, we found 65 Enzyme methods, each with its own quirks, leading to a rapidly expanding rule set and growing concerns about the feasibility of our efforts.
Take, for example, the Enzyme method find, which accepts a variety of arguments like selector strings, component types, constructors, and object properties. It also supports nested filtering methods like first or filter, offering powerful element targeting capabilities but adding complexity to AST manipulation.
In addition to the large number of manual rules needed for method conversions, certain logic was dependent on the rendered component Document Object Model (DOM) rather than the mere presence or absence of comparable methods in RTL. For instance, the choice between getByRole and getByTestId depended on the accessibility roles or test IDs present in the rendered component. However, AST lacks the capability to incorporate such contextual information. Its functionality is confined to processing the conversion logic based solely on the contents of the file being transformed, without consideration for external sources such as the actual DOM or React component code.
With each new transformation rule we tackled, the difficulty seemed to escalate. After establishing patterns for 10 Enzyme methods and addressing other obvious patterns related to our custom Jest matchers and query selectors, it became apparent that AST alone couldn’t handle the complexity of this conversion task. Consequently, we opted for a pragmatic approach: we achieved relatively satisfactory conversions for the most common cases while resorting to manual intervention for the more complex scenarios. For every line of code requiring manual adjustments, we added comments with suggestions and links to relevant documentation. This hybrid method yielded a modest success rate of 45% automatically converted code across the selected files used for evaluation. Eventually, we decided to provide this tool to our frontend developer teams, advising them to run our AST-based codemod first and then handle the remaining conversions manually.
Exploring the AST provided useful insights into the complexity of the problem. We faced the challenge of different testing methodologies in Enzyme and RTL with no straightforward mapping between them. Additionally, there were no suitable tools available to automate this process effectively. As a result, we had to seek out alternative approaches to address this challenge.
Large Language Models (LLMs) transformations

Amidst the widespread conversations on AI solutions and their potential applications across the industry, our team felt compelled to explore their applicability to our own challenges. Collaborating with the DevXP AI team at Slack, who specialize in integrating AI into the developer experience, we integrated the capabilities of Anthropic’s AI model, Claude 2.1, into our workflows. We created the prompts and sent the test code along with them to our recently-implemented API endpoint.
Despite our best efforts, we encountered significant variation and inconsistency. Conversion success rates fluctuated between 40-60%. The outcomes ranged from remarkably effective conversions to disappointingly inadequate ones, depending largely on the complexity of the task. While some conversions proved impressive, particularly in transforming highly Enzyme-specific methods into functional RTL equivalents, our attempts to refine prompts had limited success. Our efforts to fine-tune prompts may have complicated matters, possibly perplexing the AI model rather than aiding it. The scope of the task was too large and multifaceted, so the standalone application of AI failed to provide the consistent results we sought, highlighting the complexities inherent in our conversion task.
The realization that we had to resort to manual conversions with minimal automation was disheartening. It meant dedicating a substantial amount of our team’s and company’s time to test migration, time that could otherwise be invested in building new features for our customers or enhancing developer experience. However, at Slack, we highly value creativity and craftsmanship and we didn’t halt our efforts there. Instead, we remained determined to explore every possible avenue available to us.
AST + LLM transformations
We decided to observe how real humans perform test conversions and identify any aspects we might have overlooked. One notable advantage in the comparison between manual human conversion and automated processes was the wealth of information accessible to humans during conversion tasks. Humans benefit from valuable insights taken from various sources, including the rendered React component DOM, React component code (often authored by the same individuals), AST conversions, and extensive experience with frontend technologies. Recognizing the significance of this, we reviewed our workflows and integrated most of this relevant information into our conversion pipeline. This is our final pipeline flowchart:
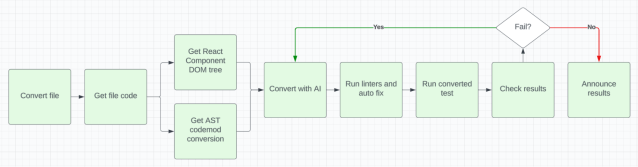
This strategic pivot, and the integration of both AST and AI technologies, helped us achieve the remarkable 80% conversion success rate, based on selected files, demonstrating the complementary nature of these approaches and their combined efficacy in addressing the challenges we faced.
In our pursuit of optimizing our conversion process, we implemented several strategic decisions that led to a notable 20-30% improvement beyond the capabilities of our LLM model out-of-the-box. Among these, two innovative approaches stood out that I will write about next:
- DOM tree collection
- LLM control with prompts and AST
DOM tree collection
One crucial aspect of our approach was the collection of the DOM tree of React components. This step proved critical because RTL testing relies heavily on the DOM structure of a component rather than its internal structure. By capturing the actual rendered DOM for each test case, we provided our AI model with essential contextual information that enabled more accurate and relevant conversions.
This collection step was essential because each test case might have different setups and properties passed to the component, resulting in varying DOM structures for each test case. As part of our pipeline, we ran Enzyme tests and extracted the rendered DOM. To streamline this process, we developed adaptors for Enzyme rendering methods and stored the rendered DOM for each test case in a format consumable by the LLM model. For instance:
// Import original methods
import enzyme, { mount as originalMount, shallow as originalShallow } from 'enzyme';
import fs from 'fs';
let currentTestCaseName: string | null = null;
beforeEach(() => {
// Set the current test case name before each test
const testName = expect.getState().currentTestName;
currentTestCaseName = testName ? testName.trim() : null;
});
afterEach(() => {
// Reset the current test case name after each test
currentTestCaseName = null;
});
// Override mount method
enzyme.mount = (node: React.ReactElement, options?: enzyme.MountRendererProps) => {
const wrapper = originalMount(node, options);
const htmlContent = wrapper.html();
if (process.env.DOM_TREE_FILE) {
fs.appendFileSync(
process.env.DOM_TREE_FILE,
`<test_case_title>${currentTestCaseName}</test_case_title> and <dom_tree>${htmlContent}</dom_tree>;\n`,
);
}
return wrapper;
};
...LLM control with prompts and AST
The second creative change we had to integrate was a more robust and strict controlling mechanism for hallucinations and erratic responses from our LLM. We achieved this by employing two key mechanisms: prompts and in-code instructions made with the AST codemod. Through a strategic combination of these approaches, we created a more coherent and reliable conversion process, ensuring greater accuracy and consistency in our AI-driven transformations.
We initially experimented with prompts as the primary means of instructing the LLM model. However, this proved to be a time-consuming task. Our attempts to create a universal prompt for all requests, including initial and feedback requests, were met with challenges. While we could have condensed our code by employing a single, comprehensive prompt, we found that this approach led to a significant increase in the complexity of requests made to the LLM. Instead, we opted to streamline the process by formulating a prompt with the most critical instructions that consisted of three parts: introduction and general context setting, main request (10 explicit required tasks and seven optional), followed by the instructions on how to evaluate and present the results:
Context setting:
`I need assistance converting an Enzyme test case to the React Testing Library framework.
I will provide you with the Enzyme test file code inside <code></code> xml tags.
I will also give you the partially converted test file code inside <codemod></codemod> xml tags.
The rendered component DOM tree for each test case will be provided in <component></component> tags with this structure for one or more test cases "<test_case_title></test_case_title> and <dom_tree></dom_tree>".`Main request:
`Please perform the following tasks:
1. Complete the conversion for the test file within <codemod></codemod> tags.
2. Convert all test cases and ensure the same number of tests in the file. ${numTestCasesString}
3. Replace Enzyme methods with the equivalent React Testing Library methods.
4. Update Enzyme imports to React Testing Library imports.
5. Adjust Jest matchers for React Testing Library.
6. Return the entire file with all converted test cases, enclosed in <code></code> tags.
7. Do not modify anything else, including imports for React components and helpers.
8. Preserve all abstracted functions as they are and use them in the converted file.
9. Maintain the original organization and naming of describe and it blocks.
10. Wrap component rendering into <Provider store={createTestStore()}><Component></Provider>. In order to do that you need to do two things
First, import these:
import { Provider } from '.../provider';
import createTestStore from '.../test-store';
Second, wrap component rendering in <Provider>, if it was not done before.
Example:
<Provider store={createTestStore()}>
<Component {...props} />
</Provider>
Ensure that all 10 conditions are met. The converted file should be runnable by Jest without any manual changes.
Other instructions section, use them when applicable:
1. "data-qa" attribute is configured to be used with "screen.getByTestId" queries.
2. Use these 4 augmented matchers that have "DOM" at the end to avoid conflicts with Enzyme
toBeCheckedDOM: toBeChecked,
toBeDisabledDOM: toBeDisabled,
toHaveStyleDOM: toHaveStyle,
toHaveValueDOM: toHaveValue
3. For user simulations use userEvent and import it with "import userEvent from '@testing-library/user-event';"
4. Prioritize queries in the following order getByRole, getByPlaceholderText, getByText, getByDisplayValue, getByAltText, getByTitle, then getByTestId.
5. Use query* variants only for non-existence checks: Example "expect(screen.query*('example')).not.toBeInTheDocument();"
6. Ensure all texts/strings are converted to lowercase regex expression. Example: screen.getByText(/your text here/i), screen.getByRole('button', {name: /your text here/i}).
7. When asserting that a DOM renders nothing, replace isEmptyRender()).toBe(true) with toBeEmptyDOMElement() by wrapping the component into a container. Example: expect(container).toBeEmptyDOMElement();`Instructions to evaluate and present results:
`Now, please evaluate your output and make sure your converted code is between <code></code> tags.
If there are any deviations from the specified conditions, list them explicitly.
If the output adheres to all conditions and uses instructions section, you can simply state "The output meets all specified conditions."`The second and arguably more effective approach we used to control the output of the LLM was the utilization of AST transformations. This method is rarely seen elsewhere in the industry. Instead of solely relying on prompt engineering, we integrated the partially converted code and suggestions generated by our initial AST-based codemod. The inclusion of AST-converted code in our requests yielded remarkable results. By automating the conversion of simpler cases and providing annotations for all other instances through comments in the converted file, we successfully minimized hallucinations and nonsensical conversions from the LLM. This technique played a pivotal role in our conversion process. We have now established a robust framework for managing complex and dynamic code conversions, leveraging a multitude of information sources including prompts, DOM, test file code, React code, test run logs, linter logs, and AST-converted code. It’s worth noting that only an LLM was capable of assimilating such disparate types of information; no other tool available to us possessed this capability.
Evaluation and impact
Evaluation and impact assessments were crucial components of our project, allowing us to measure the effectiveness of our methods, quantify the benefits of AI-powered solutions, and validate the time savings achieved through AI integration.
We streamlined the conversion process with on-demand runs, delivering results in just 2-5 minutes, as well as with CI nightly jobs that handled hundreds of files without overloading our infrastructure. The files converted in each nightly run were categorized based on their conversion status—fully converted, partially converted with 50-99% of test cases passed, partially converted with 20-49% of test cases passed, or partially converted with less than 20% of test cases passed—which allowed developers to easily identify and use the most effectively converted files. This setup not only saved time by freeing developers from running scripts but also enabled them to locally tweak and refine the original files for better performance of the LLM with the local on-demand runs.
Notably, our adoption rate, calculated as the number of files that our codemod ran on divided by the total number of files converted to RTL, reached approximately 64%. This adoption rate highlights the significant utilization of our codemod tool by the frontend developers who were the primary consumers, resulting in substantial time savings.
We assessed the effectiveness of our AI-powered codemod along two key dimensions: manual evaluation of code quality on specific test files and pass rate of test cases across a larger test files set. For the manual evaluation, we analyzed nine test files of varying complexities (three easy, three medium, and three complex) which were converted by both the LLM and frontend developers. Our benchmark for quality was set by the standards achieved by the frontend developers based on our quality rubric that covers imports, rendering methods, JavaScript/TypeScript logic, and Jest assertions. We aimed to match their level of quality. The evaluation revealed that 80% of the content within these files was accurately converted, while the remaining 20% required manual intervention.
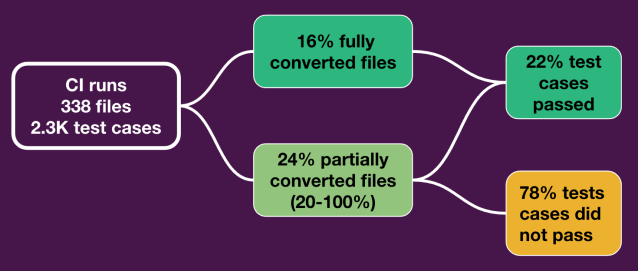
The second dimension of our analysis delved into the pass rate of test cases across a comprehensive set of files. We examined the conversion rates of approximately 2,300 individual test cases spread out within 338 files. Among these, approximately 500 test cases were successfully converted, executed, and passed. This highlights how effective AI can be, leading to a significant saving of 22% of developer time. It’s important to note that this 22% time saving represents only the documented cases where the test case passed. However, it’s conceivable that some test cases were converted properly, yet issues such as setup or importing syntax may have caused the test file not to run at all, and time savings were not accounted for in those instances. This data-centric approach provides clear evidence of tangible time savings, ultimately affirming the powerful impact of AI-driven solutions. It’s worth noting that the generated code was manually verified by humans before merging into our main repository, ensuring the quality and accuracy of the automated conversion process while keeping human expertise in the loop.
As our project nears its conclusion in May 2024, we’re still in the process of collecting data and evaluating our progress. Thus far it’s apparent that LLMs offer valuable support for the developers’ experience and have a positive effect on their productivity, adding another tool to our repertoire. However, the scarcity of information surrounding code generation, Enzyme-to-RTL conversion in particular, suggests that it’s a highly complex issue and AI might not be able to be an ultimate tool for this kind of conversion. While our experience has been somewhat fortunate in the respect that the model we used had out-of-the-box capabilities for JavaScript and TypeScript, and we didn’t have to do any extra training, it’s clear that custom implementations may be necessary to fully utilize any LLM potential.
Our custom Enzyme-to-RTL conversion tool has proven effective so far. It has demonstrated reliable performance for large-scale migrations, saved frontend developers noticeable time, and received positive feedback from our users. This success confirms the value of our investment into this automation. Looking ahead, we’re eager to explore automated frontend unit test generation, a topic that has generated excitement and optimism among our developers regarding the potential of AI.
Furthermore, as a member of the Frontend Test Frameworks team, I’d like to express my gratitude for the collaboration, support, and dedication of our team members. Together, we created this conversion pipeline, conducted rigorous testing, made prompt improvements, and contributed exceptional work on the AST codemod, significantly elevating the quality and efficiency of our AI-powered project. Additionally, we extend our thanks to the Slack DevXP AI team for providing an outstanding experience in utilizing our LLM and for patiently addressing all inquiries. Their support has been instrumental in streamlining our workflows and achieving our development goals. Together, these teams exemplify collaboration and innovation, embodying the spirit of excellence within our Slack engineering community.
Interested in building innovative projects and making developers’ work lives easier? We’re hiring 💼





