

Reinventing how the world does work inevitably creates a lot of data. Each year, Slack’s scale has increased and the volume of data ingested and stored has kept pace. To make it possible to understand relationships within our data, we’ve invested heavily in an automated data lineage framework. This facilitates producer/consumer coordination, improves risk mitigation, impact analysis, and better execution of data programs here at Slack.
Why invest in data lineage?
Data lineage refers to the ability to trace how and where data sources are used. In the first years of a company, data lineage is easy to fully understand: a company with only a handful of data pipelines doesn’t need to worry much about data lineage since they can count the number of tables with their fingers. However, as datasets become more complex and the number of contributors grow, it becomes more and more difficult to understand the relationships between different data sources.
Having a solid understanding of data lineage makes operational maintenance much easier. A common request of data engineering teams is to backfill a table after a bug is fixed in its source data. For tables that are never consumed by other data pipelines, this is a trivial task: just rerun all the affected dates for the requested table. For tables that are consumed by other jobs, the complexity of backfill balloons: all downstream tables might need to be rerun, depending on if the columns impacted by the bug fix were consumed by that table. Fortunately, it isn’t every day that massive backfills need to run, meaning good data lineage was historically a “nice to have” feature at many companies. This is, at least, until the advent of the General Data Protection Regulation (GDPR).
On May 25, 2018, GDPR went into effect, changing data lineage into a critical feature for most global companies. Good data lineage isn’t required for GDPR compliance, but it makes it much easier to achieve. GDPR provides a series of data privacy guarantees for citizens of European Union member states and backs up the law with large fines. As relevant here, GDPR provides for:
- The Right to Know (get all the information a company has about yourself)
- The Right to be Forgotten (tell a company to anonymize/delete all information about yourself)
To avoid serious fines, companies around the world scrambled to identify data containing Personally Identifiable Information (PII). For many companies, thousands of ad hoc tables had been spun up, with no easy way to catalog all the data inside or where it came from. With GDPR, the argument for good data lineage had become much more compelling, changing “reduces time needed to identify what needs to be backfilled” to “assisting with GPDR compliance”.
Lineage ingestion
Lineage service
To make it easier to collect lineage data, we decided to build a central Data Lineage Service. Today, there are a number of solutions available for collecting data lineage, but when development began at Slack, it made more sense to try and build a solution. In particular, the need for column-level lineage and ease of integration were major points towards building our own system.
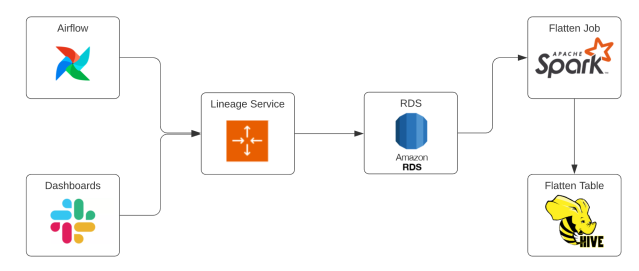
The Lineage Service exposes endpoints for lineage ingestion and handles the parsing and persistence of lineage data. When persisting lineage, we store raw data into RDS MySQL tables, then flatten out the data and store it in Hive.
Airflow callbacks
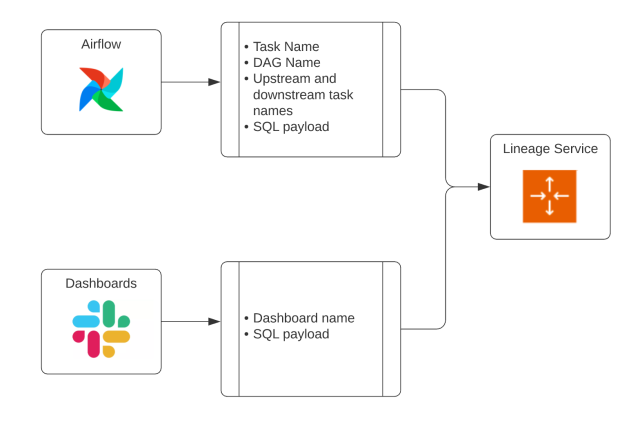
The overwhelming majority of Slack’s data pipelines are scheduled via Airflow. For folks who are unfamiliar, Airflow is an open-source tool that is often used to schedule workflows, called DAGs (Directed Acyclic Graphs). To take advantage of this, we’ve built most of our lineage ingestion into our DAGs. We use Airflow callbacks to send metadata about tasks to Slack’s lineage service, which automates lineage ingestion. To make sure that failing and retrying tasks don’t spam the service, we’ve wired up lineage ingestion to only fire requests after a successful run. This way, we’re able to automatically collect lineage metadata for nearly every data pipeline at Slack.
Dashboard lineage
While our Airflow integration collects lineage for almost everything, some use cases exist outside of Airflow. Many internal consumers of Slack data use dashboards when looking at data. Slack’s dashboards are powered by Presto and are able to run SQL queries against most of our data warehouse. Decision makers rely heavily on dashboards, so it’s important to make sure that dashboard lineage is collected and correct. Since this data usage wouldn’t be captured by our Airflow ingestion, we needed to create a separate method for ingestion.
To ensure that lineage is ingested for dashboards, we leverage audit tables that track dashboard usage. If a dashboard pulled data in the last 24 hours, we consider it “active” and send a request to the lineage service. While our Dashboard lineage won’t include Airflow metadata, it does have a SQL payload, so we’re able to parse it using nearly the same logic as the Airflow lineage.
Typical requests to the lineage service look like:
SQL parsing
The most complex (and coolest!) part of Slack’s data lineage system is how lineage metadata is parsed after being sent to the lineage service. Using the metadata, we are able to build up a variety of relationships. Since the DAG/task name is sent and our DAGs extensively use sensors, we’re able to create a graph of relationships between various DAGs. While understanding the connections between various DAGs is valuable in its own right, we’re also able to parse and extract lineage from SQL.
To parse SQL, we use ANTLR to break up the statements into consumable chunks. While SQL can be very complex, we’ve built up a large number of unit tests over time, helping to build confidence that we’re extracting the correct data and preventing regressions. Since the vast majority of our data pipelines rely on SQL, we’re able to automatically capture lineage for almost every table in our data warehouse. The biggest advantage to extracting lineage from the actual SQL used to populate tables is scalability. Anyone who’s worked in a large repo can attest that documentation grows stale over time and eventually becomes more harmful than helpful. Since parsing SQL happens automatically, we’re able to remove the need to manually update lineage definitions.
Lineage consumption
After ingesting and parsing lineage data, the service stores the data in AWS RDS tables. Those tables can be directly queried to get lineage, but a few joins would be needed to ensure that the full picture is captured by the query. Additionally, to answer a question like “show all the downstream dependencies of a table”, we’d need to run multiple queries. This is because the data stored in the RDS tables only shows direct dependencies.

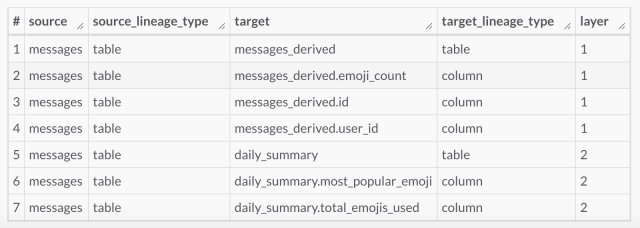
From the image above, we can see that the messages table is read by messages_derived, which in turn is used to create daily_summary. Using just the RDS tables, we’d need to run one query to find all of the dependencies of messages, then another to find the dependencies of messages_derived. This works, but runs into issues at scale.
Flattened table
To make it easier for folks to use our lineage data, we produce a flattened version of our tables and store it in Hive. The flattened table allows folks to query lineage data in our data warehouse and also makes queries easier to write/run for typical use cases. The table gets updated on a daily cadence and adds the idea of “layer” into the table, making it possible to answer questions like “get all the tables that are two steps removed from this DAG”.
For the most part, the flatten job looks like a standard Spark job, joining together a number of tables and producing a large dataset for lineage. The job gets interesting when we build the final lineage graph using Pregel. To do this, we visit each node and collect lineage data, then recurse for each of its connections until we’ve traversed the entire graph. At the end, we condense the graph back into a normal dataset with the source, target, and layer (specifying the number of steps from the source to the target).
Returning to our previous example, we can now run a single query to find all tables/columns that are downstream of messages.
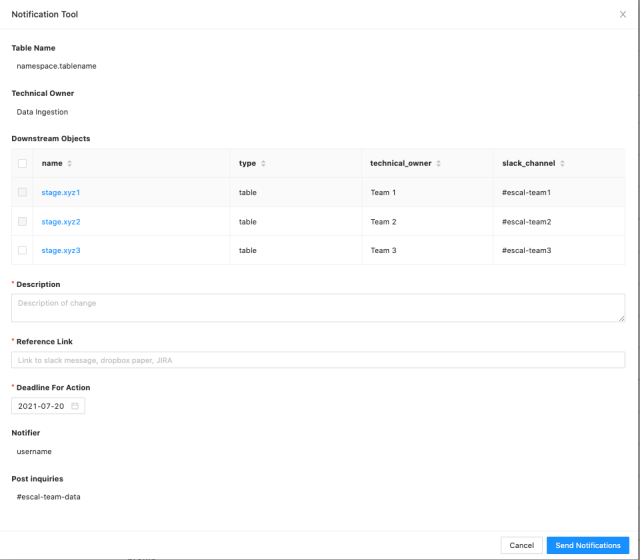
Notifications
To allow our data consumers to make use of lineage information and to notify downstream consumers, we have built notification tooling on our internal Data Portal. Owners of datasets can use a “notify” button which presents them with information about their downstream consumers, along with a call-to-action and other fields. Users use this functionality to inform their downstream owners (which includes dashboard creators, dataset owners) of upcoming changes in our data warehouse via Slack, thereby allowing consumers of downstream datasets to keep themselves well informed of upcoming changes. This functionality is extensively used in Data Retention program execution, planned dataset deprecation, and many other use-cases.
Example Notification configuration:
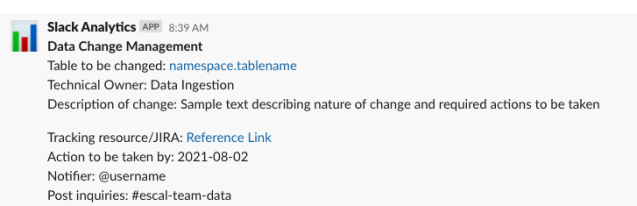
Example Notification sent on Slack
Future work
With any project, there’s always more work to be done. Some of the work we plan on doing in the future includes:
- Automated data lineage for Spark jobs that don’t use Spark SQL: While the majority of the jobs at Slack are driven by SQL, some of them use the Spark Datasets/Dataframes API. For those jobs, we’ve occasionally resorted to manually adding lineage, but this doesn’t scale well and can lead to a loss of trust. Since SQL isn’t involved, we’ll need to add a totally new endpoint and parser to handle this case and get non-SQL Spark jobs into our flattened lineage table.
- Throw our lineage data into a Graph DB: Right now, folks can use SQL queries or dashboards to look at our lineage data, but it would be amazing to hop into a Graph DB and visually explore connections. Outside of being the coolest thing under the sun, being able to visually explore our lineage would also make gaps more obvious, accommodate less technical users, and would provide awesome visuals for blog posts like this.
- Better automation tooling: We would like to automatically detect schema changes and notify downstream customers of an upcoming schema change thereby allowing better coordination between data producers and consumers.
Credits
Last, thank you (in alphabetical order) to all the folks who have put into work on Slack’s Data Lineage systems: Ajay Bhonsule, Atl Arredondo, Bing Wu, Brianne Murphy, Cheick Keita, Diana Pojar, Ekua Awotwi, Evan Raines, Johnny Cao, and Vipul Singh.
Can you help Slack solve tough problems and join our growing team? Check out all our engineering jobs and apply today: https://slack.com/careers/dept/engineering





