

At Slack, we manage tens of thousands of EC2 instances that host a variety of services, including our Vitess databases, Kubernetes workers, and various components of the Slack application. The majority of these instances run on some version of Ubuntu, while a portion operates on Amazon Linux. With such a vast infrastructure, the critical question arises: how do we efficiently provision these instances and deploy changes across them? The solution lies in a combination of internally-developed services, with Chef playing a central role. In this blog post, I’ll discuss the evolution of our Chef infrastructure over the years and the challenges we encountered along the way.
A journey down memory lane: our previous process
In the early days of Slack, we relied on a single Chef stack. Our Chef infrastructure included a set of EC2 instances, an AWS application load balancer, an RDS cluster, and an AWS OpenSearch cluster. As our fleet of instances started to grow, we scaled up and out this stack to match our increasing demand.
We had three environments on this Chef stack: Sandbox, Dev, and Prod. Nodes from each environment in our fleet were mapped to one of these environments. Slack has two types of cookbooks: cookbooks we download from the Chef Supermarket and the ones that are internally created. When these cookbooks are modified, we upload them using a process called DishPig. When a change is merged to our repo, we triggered a CI job to look for any changes to the cookbooks or roles and built an artifact with this. Then this artifact gets uploaded to a S3 bucket and then from this S3 bucket, we notify an SQS queue. We triggered the DishPig process on the top of each hour to look for any new messages in the queue. When DishPig detected a new event in the queue, it downloaded the artifact and uploaded the changed cookbooks to the Chef server. We upload the cookbooks we take from the supermarket with their own version, but we will always upload the cookbooks we create with a fixed version number. Therefore we did not have multiple versions of the cookbooks we created and only a single version of them were available on the Chef server.
Once the cookbooks were uploaded to the Chef server, all three environments were updated to include the latest versions of the Supermarket cookbooks. Since we are uploading our own cookbooks with the same version, their references in the environments did not need updating.
With this approach, all our environments got the changes on the hour.

We also provided tooling that allowed developers to create custom Chef environments with specific versions of cookbooks, enabling them to test their changes on a small set of nodes within a temporary environment. Once testing was complete, the tooling would automatically clean up the temporary environment and remove the custom cookbook versions.
This approach had a few significant drawbacks: all changes were deployed across all environments simultaneously. This meant that any faulty changes could potentially disrupt all existing Chef runs and new server provisions across our entire infrastructure.
Relying on a single Chef stack also meant that any issues with this stack could have widespread effects, potentially impacting our entire infrastructure.
Transitioning to a sharded Chef infrastructure
As our infrastructure grew rapidly, ensuring guaranteed reliability became a top priority. We recognized that relying on a single Chef stack posed a significant risk, as it was a major single point of failure. To address this, we began redesigning our Chef infrastructure, starting by eliminating our dependence on a single Chef stack.
We decided to create multiple Chef stacks to distribute the load more effectively and ensure resilience. This approach also gave us the flexibility to direct new provisions to the remaining operational Chef stacks if one were to fail. However, implementing this new strategy introduced several challenges. Let’s explore the most significant ones.
Challenge 1: Assigning a shard to a node
Our first step was to find a method for directing new provisions to specific shards. We achieved this using an AWS Route53 Weighted CNAME record. When an instance spins up, it queries the CNAME record and, based on the assigned weight, receives a record from the set. This record then determines which Chef stack the instance will be assigned to.
Additionally, as illustrated below, we separated the development and production Chef infrastructure into distinct stacks. This segregation helps strengthen the boundary between our development and production environments.

Challenge 2: Neighborhood discovery
Historically, Slack lacked a dedicated EC2 inventory management system, and our Chef stack was the closest alternative. As a result, teams began querying the Chef server whenever they needed information about specific instances in the fleet. They would use Chef search to locate nodes based on criteria, such as nodes with a particular Chef role in a specific AWS region.
This approach worked well until we moved to a sharded Chef infrastructure. With the new setup, running the same query would only return nodes from the specific Chef stack you queried. Since nodes are now distributed across multiple Chef stacks, this method no longer provides a complete view of all instances.
Let’s take a step back and look at how a Chef run operates. A Chef run consists of two phases: compile and converge. During the compile phase, Chef collects information about its run lists, reads all its cookbooks, assigns variables, creates attributes, and maps out the resources it needs to create. In the converge phase, Chef then creates those resources based on the information gathered in the compile phase.
Some of our cookbooks were designed to create attributes and variables based on the results from Chef searches. With the transition to sharded Chef stacks, we needed to find an alternative to these node discovery methods. After considering our options, we decided to leverage an existing service at Slack: Consul.
We began registering certain services in Consul for service discovery, taking advantage of Consul’s tagging capabilities. By creating and registering services, we could now query Consul for information about other nodes, replacing the need for Chef searches.
However, this introduced a new challenge. At Slack, we use an overlay network called Nebula, which transparently handles network encryption between endpoints. To query Consul, instances need to be connected through Nebula. Yet, Nebula is configured by Chef, creating a circular dependency problem. We couldn’t set up attributes or variables using Consul during Chef’s compile phase, leading to a classic chicken-and-egg situation.
After some consideration, we devised a solution using Chef’s ruby_block resources. We placed the logic for creating resources and assigning variables within these ruby_block resources. Since ruby_block resources are executed only during the converge phase of the Chef run, we can control the execution order to ensure that Nebula is installed and configured before these resources are processed.
However, for values calculated within Ruby blocks that need to be used elsewhere, we utilize the lazy keyword. This ensures that these values are loaded during the Chef converge phase.
We also developed a set of Chef library functions to facilitate node lookups based on various tags, service names, and other criteria. This allowed us to replicate the functionality we previously achieved with Chef search. We integrated these helper functions into our cookbooks, enabling us to retrieve the necessary values from Consul efficiently.
Example:
node.override['some_attribute'] = []
# In Chef, when a resource is defined all its variables are evaluated during
# compile time and the execution of the resource takes place in converge phase.
# So if the value of a particular attribute is changed in converge
# (and not in compile) the resource will be executed with the old value.
# Therefore we need to put the following call inside the ruby block because,
# We need to make sure Nebula is up so we can connect to Consul (Nebula gets stup during converge time)
ruby_block 'lets_set_some_attribute' do
block do
extend SomeHelper
node.override['some_attribute'] = consul_service_lookup_helper_func()
end
end
# Please note that we are not using `lazy` with the `only_if` below for the value that is calculated in the ruby block above
# It's because `only_if` is already lazy
# https://github.com/chef/chef/issues/10243#issuecomment-668187830
systemd_unit 'some_service' do
action [:enable, :start]
only_if { node.override['some_attribute'].empty?
endAlthough this approach required adding large Ruby blocks with complex logic to some cookbooks, it allowed us to efficiently roll out multiple Chef stacks. If you’re a Chef expert with suggestions for a better method, we’d love to hear from you. Please don’t hesitate to reach out!
Challenge 3: Searching Chef
As mentioned earlier, we initially relied on Chef as an inventory management system. This approach was useful for discovering information about nodes and their attributes within our fleet. For instance, we could track the progress of feature rollouts using these attributes. To facilitate Chef searches and reporting for developers, we created an interface called Gaz.
This approach worked well with a single Chef stack, but with multiple stacks in play, we needed a new solution. We developed a service called Shearch (Sharded Chef Search) which features an API that accepts Chef queries, runs them across multiple shards, and consolidates the results. This allows us to use Shearch behind Gaz, rather than having Gaz interact directly with a Chef stack.
Additionally, we replaced the Knife command on our development boxes with a new tool called Gnife (a nod to “Go Knife,” as it’s written in Go). Gnife offers the same functionality as the Chef Knife command but operates across multiple shards using the Shearch service.
We also had to update many of our internally developed tools and libraries to use the Shearch service instead of interacting directly with a Chef stack. As you can imagine, this required considerable effort.
Sharding our Chef infrastructure significantly enhanced its resilience. However, we still faced challenges with how we deploy our cookbooks. Currently, we update all our environments simultaneously and upload the same cookbook versions across the board. We needed a more efficient approach to improve this process.
Challenge 4: Cookbook uploads
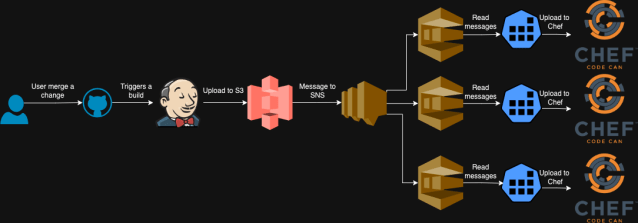
To implement this change quickly, we decided to retain our existing DishPig cookbook uploader application. However, since DishPig was designed to work with a single Chef stack, we had to deploy multiple instances of the application, each dedicated to a specific stack.
We modified our S3 bucket to send notifications to an SNS topic (instead of directly to SQS), which then fanned out these messages to multiple SQS queues, each corresponding to a different DishPig deployment. This setup allowed changes to be uploaded independently to each Chef stack without any consistency checks between them.
For example, we encountered issues where artifacts built close to the top of the hour (when DishPig is triggered) resulted in SQS messages reaching some queues on time but not others. This led to Chef stacks having different versions of cookbooks. While we did create a small monitoring system to check for and alert on consistency errors, it was far from an ideal solution.
Cookbook versioning and Chef Librarian
We needed a solution that would allow us to version our cookbooks and update environments independently, while also managing multiple Chef stacks and ensuring they remain in sync. Additionally, it was crucial for the application to track what changes are included in each version and where it has been deployed. To address these requirements, we designed a new service called Chef Librarian to replace our previous service, DishPig, as discussed earlier.
Our cookbooks are managed within a single Git repository. Internally developed cookbooks are stored in the site-cookbooks directory, while Supermarket cookbooks are kept in the cookbooks directory.
. ├── cookbooks │ ├── supermarket-cookbook-1 │ │ ├── files │ │ │ └── default │ │ │ └── file1.txt │ │ └── recipes │ │ └── default.rb │ └── supermarket-cookbook-2 │ ├── files │ │ └── default │ │ └── file1.txt │ └── recipes │ └── default.rb ├── site-cookbooks │ ├── our-cookbook-1 │ │ ├── files │ │ │ └── default │ │ │ └── file1.txt │ │ └── recipes │ │ └── default.rb │ └── our-cookbook-2 │ ├── files │ │ └── default │ │ └── file1.txt │ └── recipes │ └── default.rb └── roles ├── sample-role-1.json └── sample-role-2.json
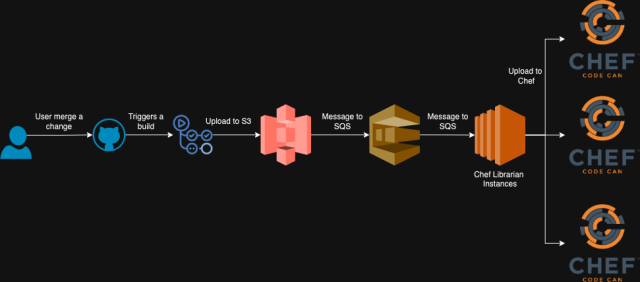
When changes to any of these items are merged, we use GitHub Actions to trigger a build job. This job creates a tarball that includes a complete copy of the repository. For internally developed cookbooks, we update the version number in the site-cookbooks directory to a new version using the standard Chef cookbook versioning format: YYYYMMDD.TIMESTAMP.0 (e.g., 20240809.1723164435.0). The version numbers for Supermarket cookbooks remain unchanged unless we fetch a new version from the upstream source.
Once the artifact is built, GitHub Actions uploads it to S3. S3 then generates a notification in an SQS queue, which the Chef Librarian application listens to. Chef Librarian promptly processes the new artifact and uploads the updated versions of cookbooks to all our Chef stacks. Although these new versions are now on the Chef stacks, they won’t be utilized until explicitly specified.
With this approach, we upload all cookbooks, regardless of whether they have changed or not, to the Chef stacks with the new version.
We have developed two API endpoints for the Chef Librarian application:
/update_environment_to_version– This endpoint updates an environment to a specified version. To use it, send a POST request with parameters including the target environment and the version to update to./update_environment_from_environment– This endpoint updates an environment to match the versions of another environment.
We now have the ability to update environments to specific versions independently of each other. This enables us to first update the sandbox and development environments, monitor metrics for any potential issues, and ensure stability before promoting the artifact to production.
In practice, this means that any problematic changes deployed to Chef do not impact all environments simultaneously. We can detect and address errors earlier, preventing them from propagating further.
Chef Librarian also stores artifact versions, the environments they’re deployed to, and other state-related information in DynamoDB. This makes it much easier for us to track changes and visualize our rollout process.
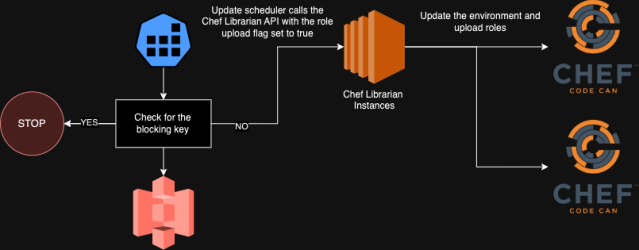
However, Chef roles are a different challenge since they aren’t versioned. When you upload them, they propagate across all environments, making role updates a risky operation. To address this, we’ve stripped most of the logic out of our Chef roles, leaving them with only basic information and a run list. Additionally, because we’ve split our Chef infrastructure into dev and prod environments, we only upload roles to the relevant Chef stacks when their corresponding environments are updated (e.g., roles are uploaded to prod shards only when the prod environment is updated).

Currently, we use a Kubernetes CronJob to call the API endpoints discussed earlier on a schedule, promoting versions across our environments. However, this process first checks for a key in a designated S3 bucket to ensure that promotions are not blocked before proceeding. This means that if we detect failures in the sandbox or dev environments, we can place this key in the bucket to prevent further promotion of artifact versions.
At present, this is a manual process triggered by a human when they receive alerts about Chef run failures or provisioning issues. Our goal, however, is to replace this Kubernetes CronJob with a more intelligent system that can automatically monitor metrics and impose these blocks without human intervention.
We’ve also developed an interface for Chef Librarian, allowing users to view which artifacts have been uploaded with specific commits, as well as when an environment was updated to a particular version in a specific Chef shard.

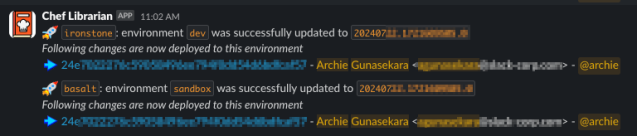
We developed a Slack app for the Chef Librarian application, allowing us to notify users when their changes are being promoted to an environment. The app identifies the user who made the change by examining the Git commit and then uses the Slack API to look up their Slack handle. This enables us to tag the user directly in the notification, ensuring they are promptly informed when the message is posted.
What’s next?
Although we’ve made significant strides in improving deployment safety, there’s still much more we can do. One avenue we’re exploring is further segmentation of our Chef environments. For example, we’re considering breaking down our production Chef environments by AWS availability zones, allowing us to promote changes independently within each zone and prevent bad changes from being deployed everywhere simultaneously.
Another long-term option we’re investigating is the adoption of Chef PolicyFiles and PolicyGroups. While this represents a significant departure from our current setup, it would offer much greater flexibility and safety when deploying changes to specific nodes.
Implementing these changes at our scale is a complex undertaking. We’re still conducting research and assessing the potential impacts and benefits. There’s a lot of exciting work happening in this space at Slack, so stay tuned to our blog for more updates on the cool projects we’re working on!





