

Every codebase starts off small and modern. While it’s still small, the team can easily keep it up-to-date with current standards, upgrade libraries, and handle any code hygiene issues that may arise. Updating the API of a framework you built is easy when it’s only called in a handful of places. However, as the codebase grows these problems only become tougher. Anyone who has ever refactored a large codebase knows the pain that comes with having to modify hundreds or even thousands of files.
Larger codebases also tend to have more dependencies that need to be updated more frequently, and more hygiene issues that slow down developers. When you take the cross product of these things, the effort of keeping a codebase well maintained at a reasonable size becomes untenable. First, you give up on hygiene, leaving unused or forgotten experimental code lying around. Eventually, libraries fail to get updated when they should. The rationale is usually that the cost of fixing these things is not worth the value they add, despite the fact that forgotten experimental code is the source of numerous hard-to-track bugs, copying unused code perpetuates legacy patterns into the future, and out-of-date libraries present security or performance risks.
In addition to cost, there is the issue of motivation. Very few people like doing this type of work. It’s often slow, tedious, and repetitive. It’s never flashy and doesn’t visibly move core company metrics on its own. It can be exceedingly thankless work and is therefore easy for developers to put off to the side while working on the more visibly impactful features they want to develop. Because of this, all codebases tend to slowly degrade over time, making the experience of working in them less enjoyable and less efficient.
It’s with all of that in mind that Slack is working on addressing these issues by leveraging automation.
Identifying a solution
The first step towards a solution is to concretely define the problem we are trying to solve. At the core, this problem is one of cost. We want to reduce the cost of modifying large codebases, especially for tasks like library upgrades, code cleanliness, and refactors. With this in mind, we have a few core principles for any solution to follow.
- Value developer time: Shifting time from one activity to another isn’t good enough, and solutions that require huge boilerplate investments are not acceptable.
- Be language agnostic: We work in a variety of languages at Slack; anything we use should benefit as many of our codebases as possible.
- Maximize leverage: Any work done should have the maximum amount of impact for the minimum amount of effort.
Guided by these principles, we’ve been working on an open-source framework for large-scale codebase modification and we’re ready to share both the framework and our plans.
Before we talk about the framework, let’s answer the question of why we are open-sourcing it. Tools like this benefit greatly from scale. No matter whether we’re fixing a codebase with thousands or millions of files, most of the work stays the same. Our hope is that opening-sourcing this framework will enable all of us to work together on solutions that can ease the problem of codebase maintenance across the entire industry, benefiting from the massive scale that presents and reducing the individual cost to any organization or developer.
Introducing AutoTransform
AutoTransform is an open-source framework for large-scale code modification. It enables a schema-based system of defining codemods that can then be run using AutoTransform, with options for automatic scheduling as well as change management. AutoTransform leverages a component-based model that allows adopters to quickly and easily get whatever behavior they need through the creation of new, custom components. Additionally, custom components can readily be added to the component library of AutoTransform to be shared more widely with others using the framework. Now, let’s break down what each of these things means.
- Schema-based: AutoTransform packages a modification in the form of a schema. This schema defines everything that’s needed to execute a modification. These schemas can be shared across codebases and across organizations, allowing—for example—authors of libraries to release schemas that upgrade uses of previous versions of their library to the newest version.
- Component-based: A schema in AutoTransform consists of a set of components that define each step of the modification process, from gathering the set of items needing modification to performing the modification and validating the results. Through the use of components, AutoTransform becomes easier to customize to the needs of an organization while maintaining language agnosticism by treating each component as a black box.
- Automatic scheduling: AutoTransform can be hooked into your CI system to automatically run transformations on a predetermined schedule. This allows AutoTransform to continually keep a codebase up-to-date or to spread a run over a large number of days if desired.
- Change management: Keeping track of the changes produced by codemods can be a painful process, and rebasing a significant change is time-consuming. Because of that, AutoTransform also offers management functionality for handling outstanding changes.
To get a better understanding of how a schema works, you can check out this breakdown of the flow of running a schema.
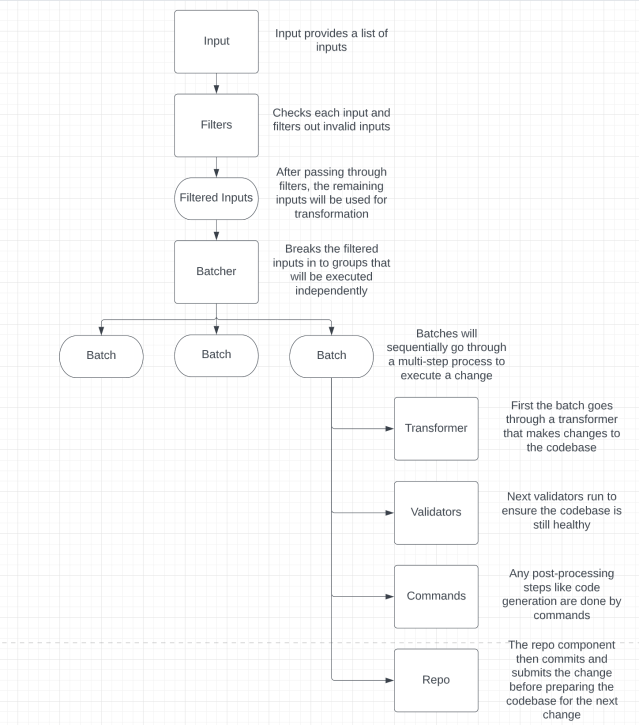
You can learn more about AutoTransform by reading the documentation or checking out the code at the Github repo. We also have a package on PyPI: pip install AutoTransform.
Our plans
While AutoTransform is already running in our codebase, it’s still early days. We’ve only just released version 1.0.0 and there is a ton of work to be done building out modifications for our codebases and developing the features needed to make them work.
Over the next six months, we plan to work on deploying a number of modifications across multiple repositories and open-sourcing as many of them as possible, including both any new components we make and the schemas themselves. We know that other organizations won’t benefit from all of the code that we’re writing—some of it will be Slack-specific—but we plan to release the code that could be valuable to other organizations. Our initial work will likely involve unused code in Hack, experiment clean-up in Hack, and automating fixes for lint issues.
In addition to working on specific modifications and components, we also plan to work on adding new functionality to AutoTransform, such as the ability to run against human-authored changes as part of a CI system. Feel free to submit your requested features as issues on the AutoTransform repo.
Conclusion
With the release of AutoTransform, we are beginning our journey towards a codebase that automatically maintains itself. We hope that through this process we are able to help every developer ensure their codebase is modern and delightful to work in. If you’re interested in following a similar journey yourself, feel free to reach out on Github for any issues you have in adopting AutoTransform. As with any journey, this one will be much better with company. Expect to hear more from us in the future as we continue down this path.
Interested in helping accelerate developers and building a world class developer environment? We’re hiring! 💼
Apply now




