
We manage the build pipeline that delivers Quip and Slack Canvas’s backend. A year ago, we were chasing exciting ideas to help engineers ship better code, faster. But we had one huge problem: builds took 60 minutes. With a build that slow, the whole pipeline gets less agile, and feedback doesn’t come to engineers until far too late.
We fixed this problem by combining modern, high-performance build tooling (Bazel) with classic software engineering principles. Here’s how we did it.
Thinking About Build (and Code) Performance
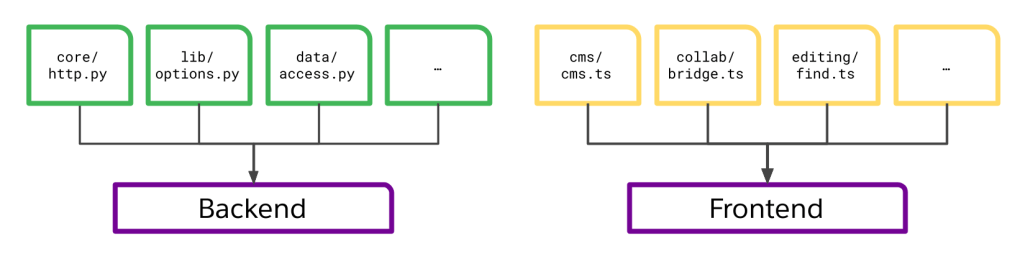
Imagine a simple application. It has a backend server that provides an API and data storage, and a frontend that presents the user interface. Like many modern applications, the frontend and backend are decoupled; they can be developed and delivered independently.
The graph of this build looks like this:
We represent the dependencies between the elements of the build, like source files and deployable artifacts, with arrows, forming a directed acyclic graph. Here, our backend depends on a collection of Python files, meaning that whenever a Python file changes, we need to rebuild the backend. Likewise, we need to rebuild our frontend whenever a TypeScript file changes — but not when a Python file does.
Modeling our build as a graph of clearly-defined units of work lets us apply the same kind of performance optimizations we might use to speed up application code:
- Do less work. Store the results of expensive work you do so that you only have to do it once, trading off memory for time.
- Share the load. Spread the work you’re doing across more compute resources in parallel, so that it completes more quickly, trading off compute for time.
Caching and Parallelization
These techniques will look familiar to most engineers, and thinking about them through a code lens helps solidify how they apply to a build system. Take this Python example:
def factorial(n):
return n * factorial(n-1) if n else 1
Calculating a factorial can be very expensive. If we need to do it often, we’re going to run quite slowly. But intuitively, we know that the factorial of a number doesn’t change. This means we can apply strategy 1 to cache the results of this function. Then it only needs to run once for any given input.
@functools.cache
def factorial(n):
return n * factorial(n-1) if n else 1
The cache stores our inputs (n) and maps them to the corresponding outputs (the return value of factorial()). n is the cache key: it functions like a source file in the build graph, with the output of the function corresponding to the built artifact.
Refining our intuition, we can say that this function needs to have a few specific attributes for caching to work. It needs to be hermetic: it only uses the inputs it is explicitly given to produce a specific output value. And it needs to be idempotent: the output for any given set of inputs is always the same. Otherwise, caching is unsound and will have rather surprising effects.
Once we have a cache in place, we want to maximize our hit rate: the fraction of times we call factorial() that are answered from the cache, rather than from doing the calculation. The way we define our units of work can help us keep the hit rate high.
To illustrate that idea, let’s look at a more complex piece of code:
@functools.cache
def process_images(
images: list[Image],
transforms: list[Transform]
) -> list[Image]: ..This function has a cache attached to it, but the cache isn’t very effective. The function takes two collections of inputs: a list of images and a list of transforms to apply to each image. If the caller changes any of those inputs, say by adding one more Image to the list, they also change the cache key. That means we won’t find a result in the cache, and will have to do all of the work from the beginning.
In other words, this cache is not very granular, and as a result has a poor hit rate. More effective code might look like this:
def process_images(
images: list[Image],
transforms: list[Transform]
) -> list[Image]:
new_images = []
for image in images:
new_image = image
for transform in transforms:
new_image = process_image(new_image, transform)
new_images.append(new_image)
return new_images
@functools.cache
def process_image(image: Image, transform: Transform) -> Image:
...
We move the caching to a smaller unit of work — the application of a single transform to a single image — and with a correspondingly smaller cache key. We can still retain the higher-level API; we just don’t cache there. When a caller invokes the higher-level API with a set of inputs, we can answer that request by only processing the combinations of Image and Transform that we haven’t seen before. Everything else comes from the cache. Our cache hit rate should both improve, along with our performance.
Caching helps us do less work. Now let’s look at sharing the load. What if we fanned out image processing across multiple CPU cores with threads?
def process_images_threaded(
images: list[Image],
transforms: list[Transform]
) -> list[Image]:
with ThreadPoolExecutor() as executor:
futures = []
for image in images:
futures.append(executor.submit(process_images, [image], transforms))
# Returns images in any order!
return [future.result() for future in futures.as_completed(futures)]Let’s suss out the qualities we need to be able to run our work in parallel, while also noting some key caveats.
- Like with caching, we need to rigorously and completely define the inputs and outputs for the work we want to parallelize.
- We need to be able to move those inputs and outputs across some type of boundary. Here, it’s a thread boundary, but it might as well be a process boundary or a network boundary to some other compute node.
- Units of work that we run in parallel might complete, or fail, in any order. Our code has to manage those outcomes, and clearly document what guarantees it offers. Here, we’re noting the caveat that images may not return in the same order. Whether or not that’s acceptable depends on the API.
The granularity of our units of work also plays a role in how effectively we can parallelize, although there’s a lot of nuance involved. If our units of work are few in number but large in size, we won’t be able to spread them over as many compute resources. The right trade-off between task size and count varies wildly between problems, but it’s something we need to consider as we design our APIs.
Transitioning to Build Performance
If you’re a software engineer, you’ve probably applied those techniques many times to improve your code’s performance. Let’s apply some of those principles and intuitions to build systems.
In a Bazel build, you define targets that form a directed acyclic graph. Each target has three critical elements:
- The files that are dependencies, or inputs, for this build step.
- The files that are outputs for this build step.
- The commands that transform the inputs into the outputs.
(It’s a little more complicated, but that’s enough to get the gist for now).
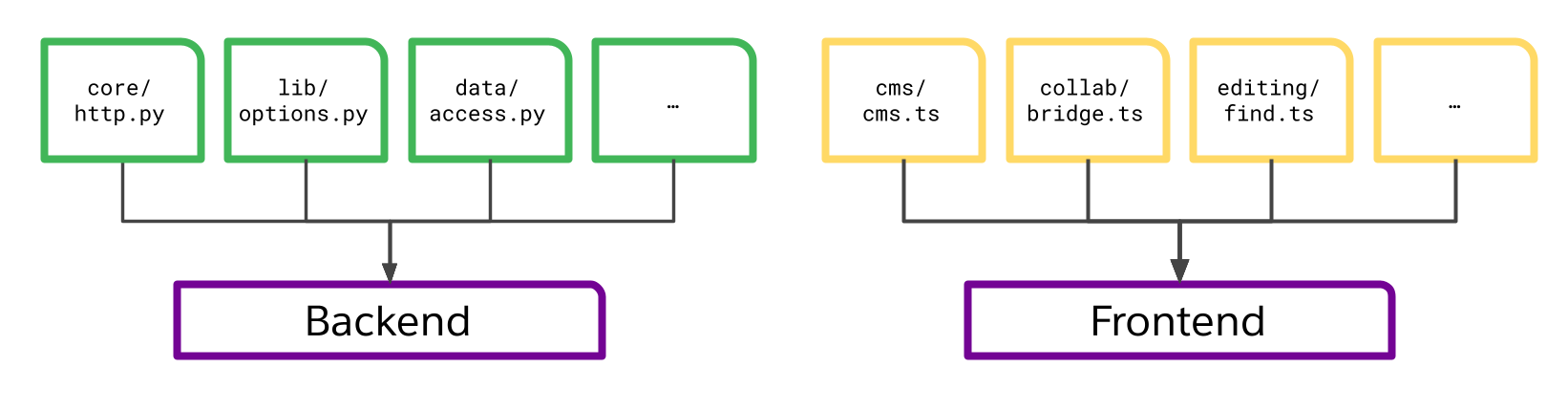
Let’s go back to that original sample application.
The Bazel target definitions might look something like this pseudocode:
python_build(
name = "backend",
srcs = ["core/http.py", "lib/options.py", "data/access.py"],
outs = ["backend.tgz"],
cmd = "python build.py",
)
ts_build(
name = "frontend",
srcs = ["cms/cms.ts", "collab/bridge.ts", "editing/find.ts"],
outs = ["frontend.tgz"],
cmd = "npm build"
)
You can think about a build target like defining (but not invoking!) a function. Notice some themes carrying over from the Python examples above? We exhaustively define the inputs (srcs) and outputs (outs) for each build step. We can think of the srcs of a target (and the transitive srcs of any targets that build them, which we’ll see more later) as the inputs to a function we wish to cache.
Because Bazel builds in a sandbox, the cmds that transform inputs to outputs only get to touch the input files we declare. And because our inputs and outputs are simply on-disk files, we solve the problem of moving them across a boundary: they just get copied! Lastly, we have to make Bazel a promise: our build steps’ cmds are in fact idempotent and hermetic.
When we do those things, we get some extraordinary capabilities for free.
- Bazel automatically caches the outcomes of our build actions. When the inputs to a target don’t change, the cached output is used — no build cost!
- Bazel distributes build actions across as many CPU cores as we allow, or even across multiple machines in a build cluster.
- Bazel only executes those actions we need for the output artifacts we want. To put it another way, we always run the least amount of work needed for the output we want.
Just like in our code examples, we’ll get the most out of Bazel’s magic when we have a well-defined dependency graph, composed of build units that are idempotent, hermetic, and granular. Those qualities allow Bazel’s native caching and parallelization to deliver great speed boosts.
That’s plenty of theory. Let’s drill down on the actual problem.
Why Quip and Canvas are Harder
Here’s the trick: Quip and Canvas are much, much more complex than the simple example we looked at before. Here’s a real diagram we drew to understand how our build worked. Don’t worry about reading all the details — we’ll use a schematic version as we dig into the problem and our solutions.
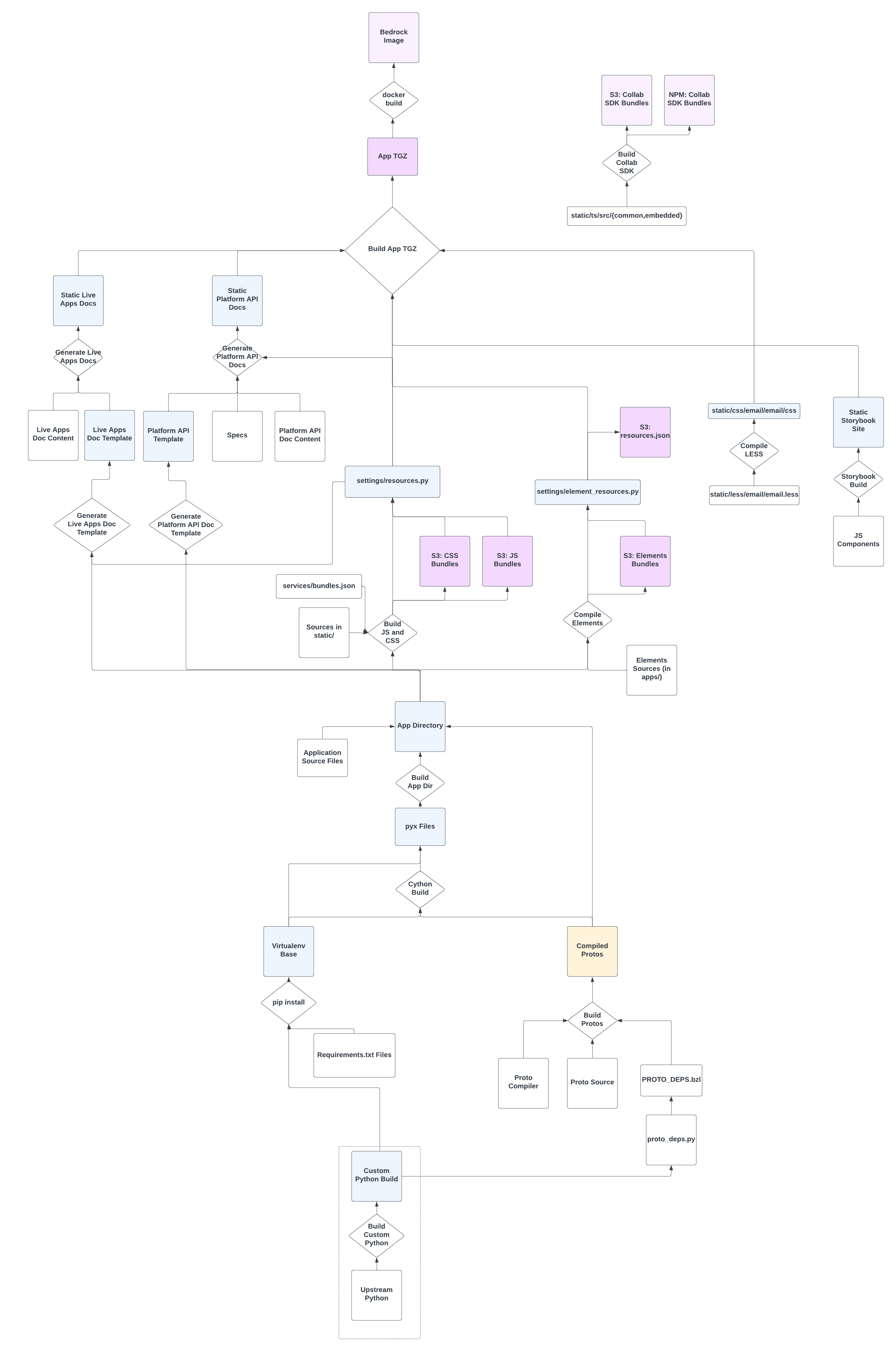
When we analyzed the graph, we discovered some critical flaws that meant we did not have the characteristics we needed to get a speed boost from Bazel:
- A directed acyclic dependency graph
→The graph wasn’t well defined, and in fact contained cycles! - Idempotent, hermetic, well-sized units of work.
→ Build execution units were huge, not all were idempotent, and hermeticity was a challenge because many build steps mutated the working directory. - Granular cache keys to keep cache hit rate high.
→ Our build was so interconnected that our cache hit rate was zero. Imagine that every cached “function” we tried to call had 100 parameters, 2-3 of which always changed.
If we had started by throwing Bazel at the build, it would have been ineffective. With a cache hit rate of zero, Bazel’s advanced cache management wouldn’t have helped, and Bazel parallelization would have added little to nothing over the ad-hoc parallelization already present in the build code. To get the Bazel magic, we needed to do some engineering work first.
Separating Concerns
Our backend code and our build code were deeply intertwined. Without a Bazel-like build system, we’d defaulted to using in-application frameworks to orchestrate the various steps within our build graph. We managed parallelization using Python’s multiprocessing strategy and the async routines built into our core codebase. Python business logic pulled together the Protobuf compilation and built Python and Cython artifacts. Lastly, tools like tsc and webpack, orchestrated by more Python scripts, transformed TypeScript and Less into the unique frontend bundle format used across Slack Canvas and Quip’s desktop and web applications.
As we began to unpick that Gordian knot, we zeroed in on how the union of backend and build code distorted the graph of our frontend build. Here’s an easier-to-digest representation of that graph.
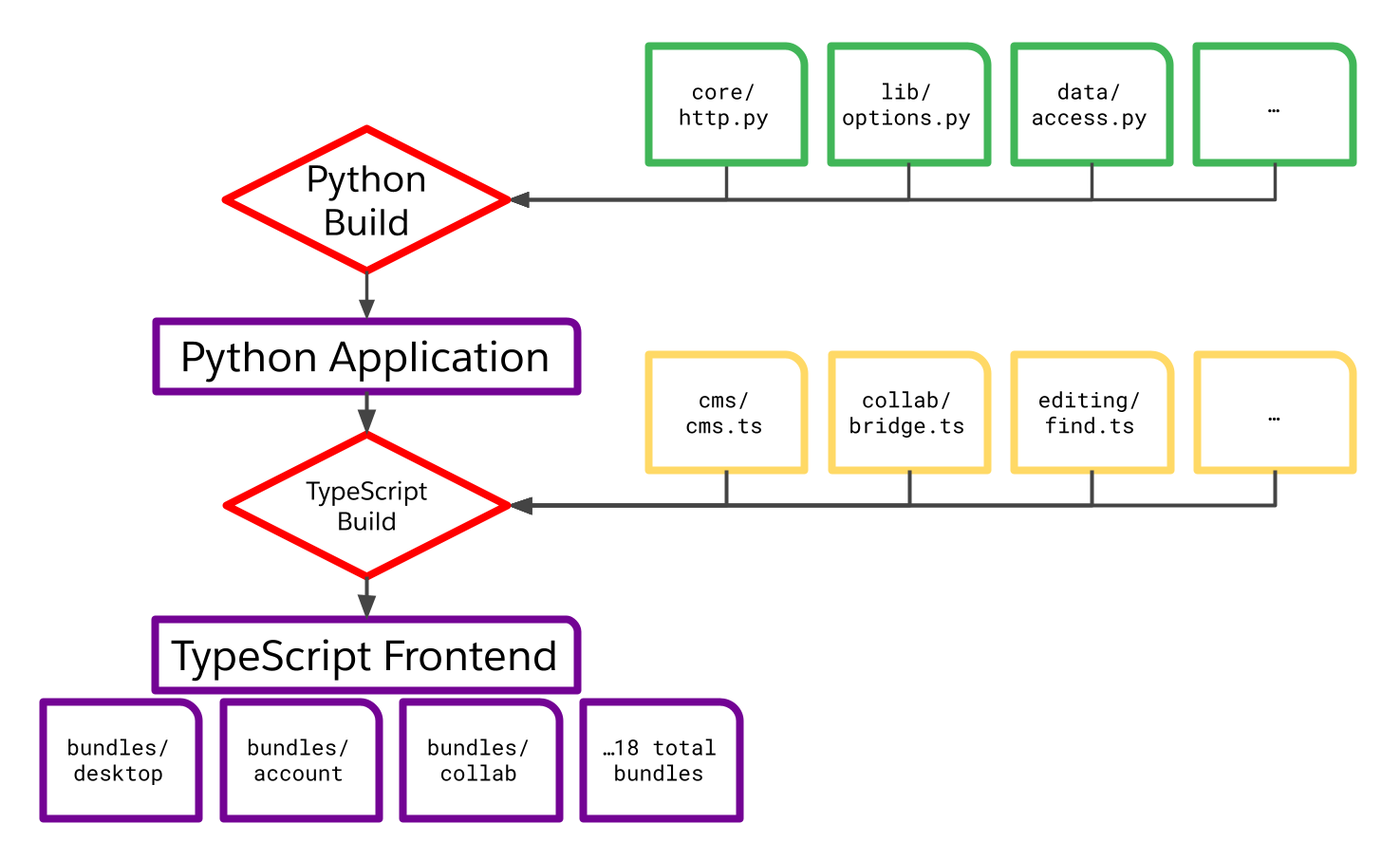
Notice how large the dependency tree is “above” our frontend bundles. It includes not just their TypeScript source and build process, but also the entire built Python backend! Those Python sources and artifacts are transitive sources for each and every frontend bundle. That means that not just a TypeScript change, but also every single Python change, alters the cache key for the frontend (one of those hundred parameters we alluded to earlier), requiring an expensive full rebuild.
The key to this build problem is that dependency edge between the Python application and the TypeScript build.
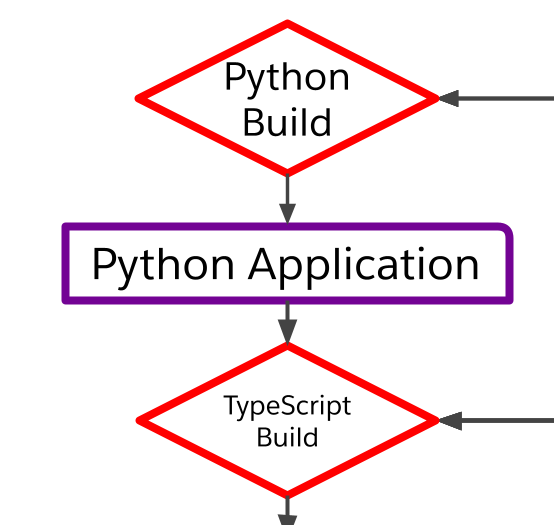
That edge was costing us an average of 35 minutes per build — more than half the total cost! — because every change was causing a full backend and frontend rebuild, and the frontend rebuild was especially expensive.
As we worked through this problem, we realized that the performance cost was not solely a build issue. It was a symptom of our pervasive failure to separate our concerns across the whole application: backend, frontend, and build code. We had couplings:
- between our backend and our frontend
- between our Python and TypeScript infrastructures and toolchains
- between our build system and our application code
Beyond making the build performance quantitatively worse, those couplings had qualitative impacts across our software development lifecycle. Engineers couldn’t reason about the blast radius of changes they made to the backend, because it might break the frontend too. Or the build system. Or both. And because our build took an hour, we couldn’t give them early warnings by running builds at the Pull Request level. The lack of health signals, and the difficulty of reasoning through potential consequences, meant that we’d break our build and our main branch far too often, and through no fault of our engineers.
Once we understood the problem through the lens of separation of concerns, it became clear we couldn’t succeed with changes to the build system alone. We had to cleanly sever the dependencies between our frontend and backend, our Python and TypeScript, our application and our build. And that meant we had to invest a lot more time than we’d originally planned.
Over several months, we painstakingly unraveled the actual requirements of each of our build steps. We rewrote Python build orchestration code in Starlark, the language Bazel uses for build definitions. Starlark is a deliberately constrained language whose limitations aim at ensuring builds meet all the requirements for Bazel to be effective. Building in Starlark helped us enforce a full separation from application code. Where we needed to retain Python scripts, we rewrote them to remove all dependencies save the Python standard library: no links to our backend code, and no additional build dependencies. We left out all of the parallelization code, because Bazel handles that for us. We’ll revisit that paradigm below in thinking about layering.
The complexity of the original build code made it challenging to define “correct” behavior. Our build code mostly did not have tests. The only criterion for what was correct was what the existing build system produced under a specific configuration. To reassure ourselves, and to instill confidence in our engineers, we built a tool in Rust to compare an artifact produced by the existing process with one produced by our new code. We used the differences to guide us to points where our new logic wasn’t quite right, and iterated, and iterated more.
That work paid off when we could finally draw a new build graph:
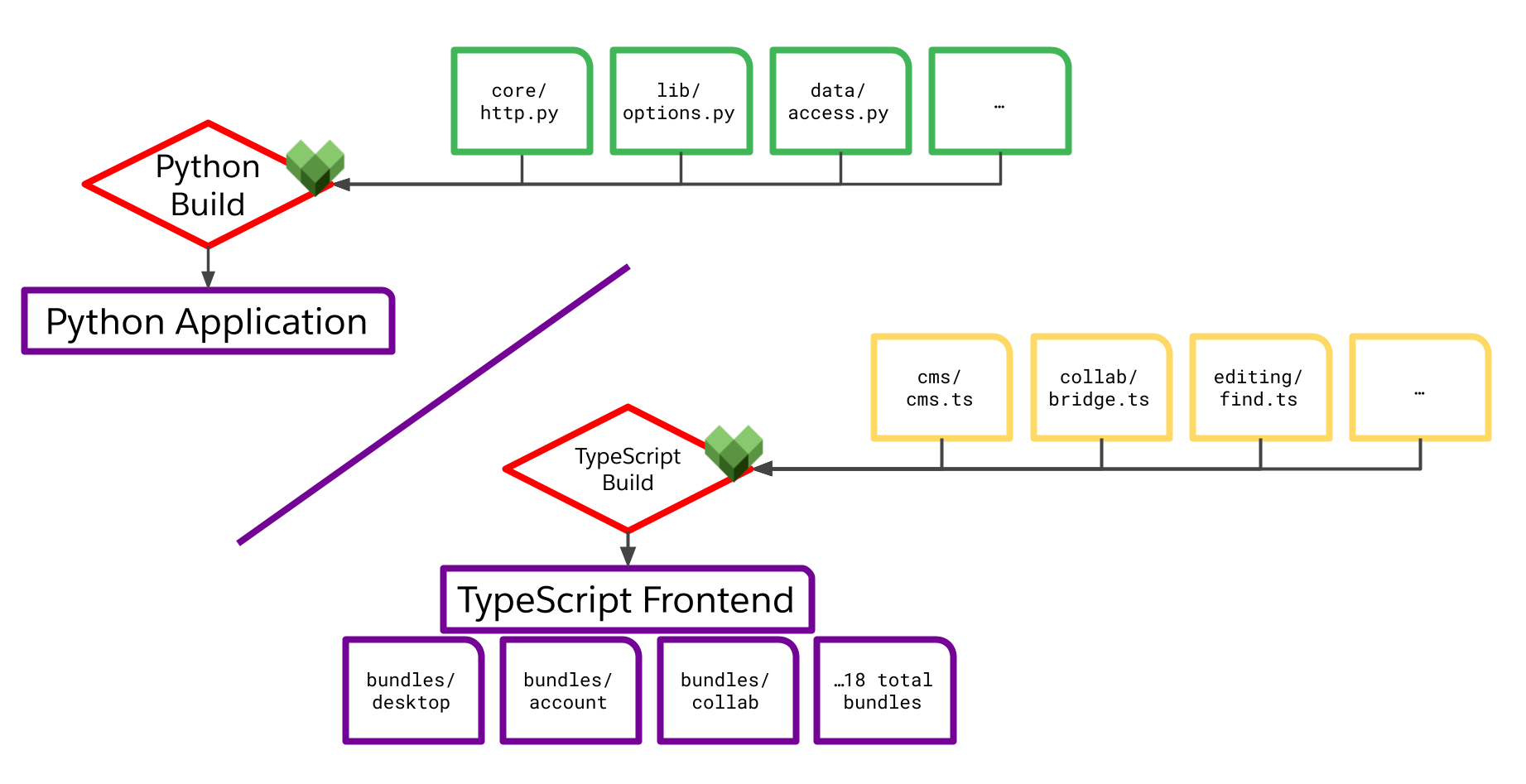
We’d severed all three of those key couplings, and taken off the table any concern that a Python change might break the build or alter the frontend output. Our build logic was colocated with the units it built in BUILD.bazel files, with well-defined Starlark APIs and a clean separation between build code and application code. Our cache hit rate went way up, because Python changes no longer formed part of the cache key for TypeScript builds.
The outcome of this work was a substantial reduction in build time: if the frontend was cached, we could build the whole application in as little as 25 minutes. That’s a big improvement, but still not enough!
Designing for Composition with Layering
Once we severed the backend ←→ frontend coupling, we took a closer look at the frontend build. Why did it take 35 minutes, anyway? As we unraveled the build scripts, we found more separation-of-concerns challenges.
Our frontend builder was trying hard to be performant. It took in a big set of inputs (TypeScript source, LESS and CSS source, and a variety of knobs and switches controlled by environment variables and command-line options), calculated the build activity it needed to do, parallelized that activity across a collection of worker processes, and marshalled the output into deployable JavaScript bundles and CSS resources. Here’s a sketch of this part of the build graph.
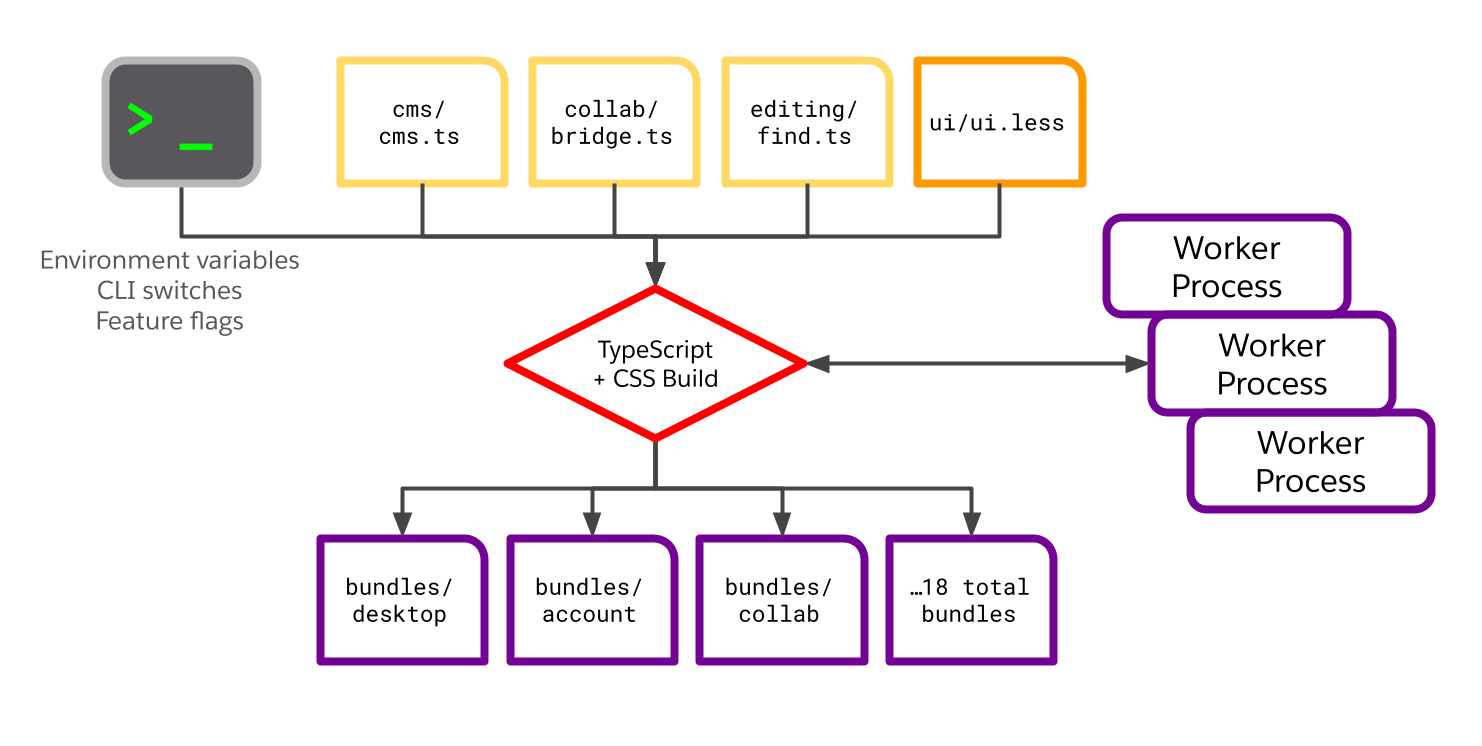
Like much of what we discovered during this project, this strategy represented a set of reasonable trade-offs when it was written: it was a pragmatic attempt to speed up one piece of the build in the absence of a larger build framework. And it was faster than not parallelizing the same work!
There are two key challenges with this implementation.
Like our process_image() example above, our cacheable units were too large. We took in all the sources and produced all the bundles. What if just one input file changed? That altered the cache key, and we had to rebuild everything. Or what if we wanted to build exactly one bundle, to satisfy a requirement elsewhere in our build process? We were out of luck; we had to depend on the whole shebang.
We’re parallelizing the work across processes, which is good — unless we could be parallelizing across machines, machines with lots more CPU cores. If we have those resources available, we cannot use them here. And we’re actually making Bazel less effective at its core function of parallelizing independent build steps: Bazel and the script’s worker processes are contending for the same set of resources. The script might even be parallelizing work that Bazel already knows it does not need!
In both these respects, it was tough for us to compose the build functionality in new ways: either a different form of orchestrating multiple bundle builds, or a different parallelization strategy. This was a layering violation.
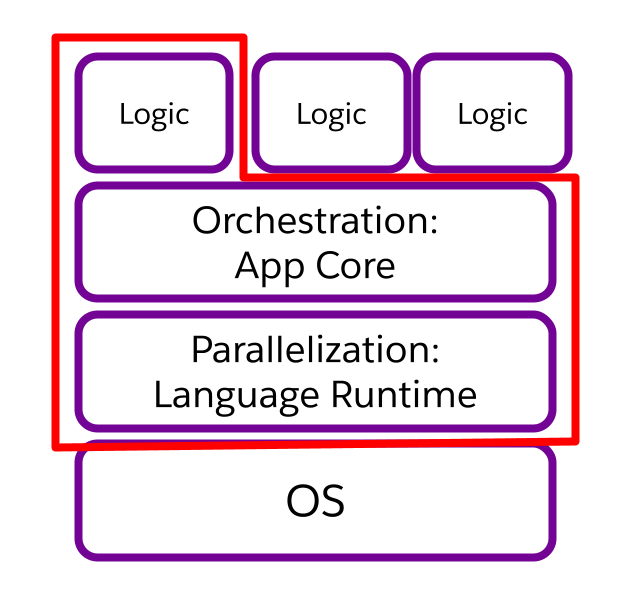
If we draw, as here, layers of capability from the operating system up to the application layer, we can see that the boundary of our builder is cutting across layers. It combines business logic, significant parts of a task orchestration framework, and parallelization. We really just wanted the top layer — the logic — so that we could re-compose it in a new orchestration context. We ended up with a work orchestrator (the builder) inside a work orchestrator (Bazel), and the two layers contending for slices of the same resource pool.
To be more effective, we really just needed to do less. We deleted a lot of code. The new version of the frontend builder was much, much simpler. It didn’t parallelize. It had a much smaller “API” interface. It took in one set of source files, and built one output bundle, with TypeScript and CSS processed independently.
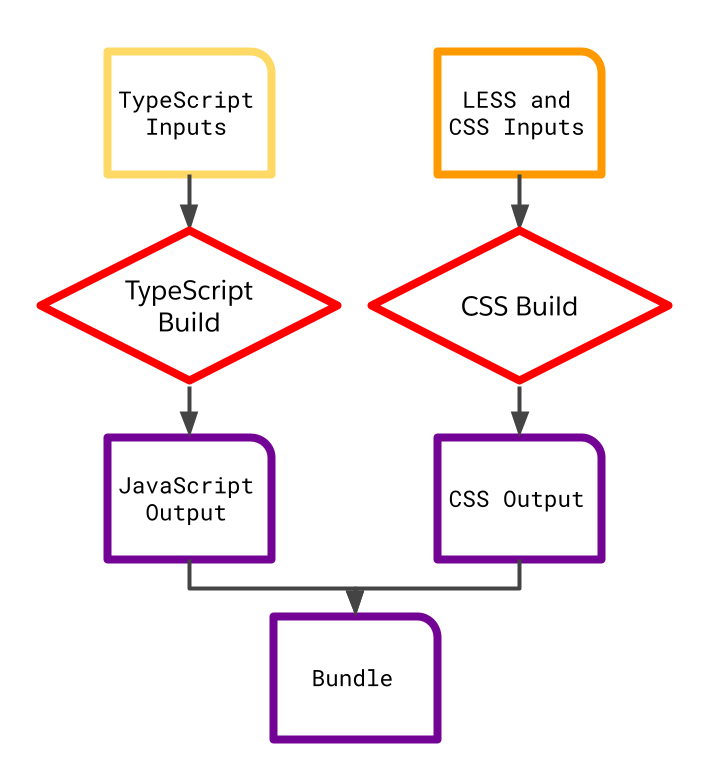
This new builder is highly cacheable and highly parallelizable. Each output artifact can be cached independently, keyed only on its direct inputs. A bundle’s TypeScript build and CSS build can run in parallel, both against one another and against the builds of other bundles. And our Bazel logic can make decisions about scope (one bundle? two? all?), rather than trying to manage a build of all of the bundles.
See the resonance, again, with our example process_images() API? We’ve created granular, composable units of work, and that’s dramatically improved our ability to parallelize and cache. We’ve also separated the concerns of our business logic and its orchestration, making it possible for us to re-compose the logic within our new Bazel build.
This change gave us some really nice outcomes:
- Because bundle builds and TypeScript and CSS builds can be cached independently of one another, our cache hit rate went up.
- Given enough resources, Bazel could parallelize all of the bundle builds and CSS compilation steps simultaneously. That bought us a nice reduction in full-rebuild time.
As an added benefit, we’re no longer running our own parallelization code. We’ve delegated that responsibility to Bazel. Our build script has a single concern: the business logic around compiling a frontend bundle. That’s a win for maintainability.
Outcomes and Takeaways
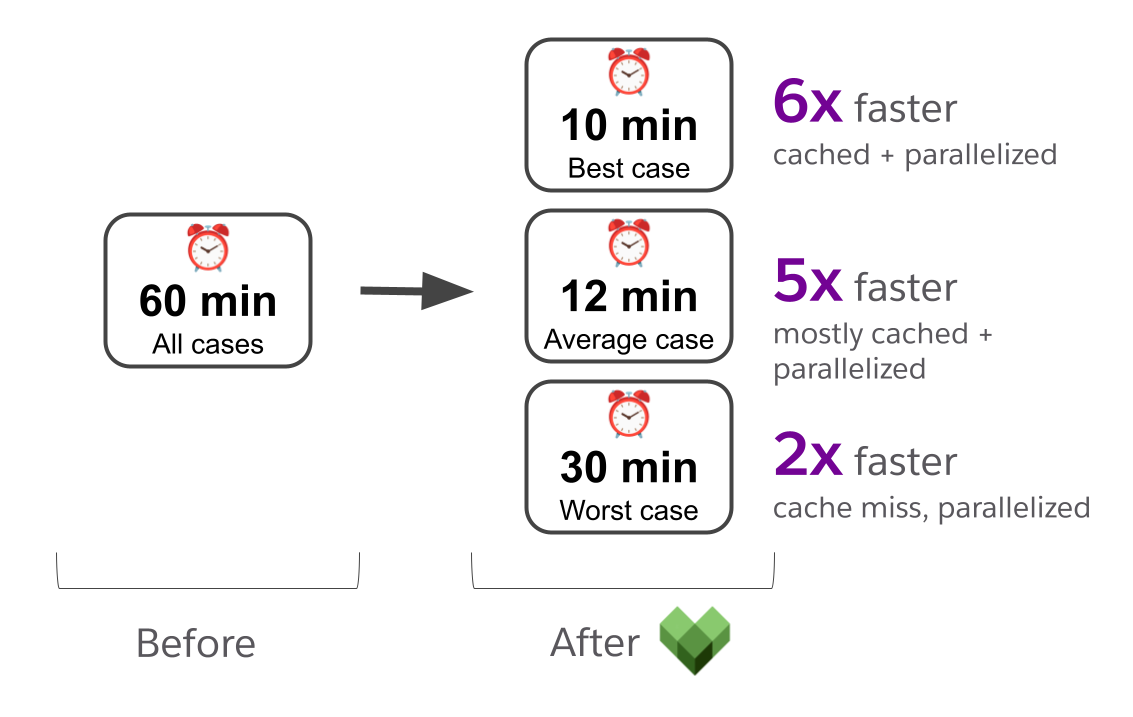
We made our build a lot faster. Faster builds lead to tighter cycle times for engineers, quicker incident resolutions, and more frequent releases. After applying these principles across our whole build graph, we came away with a build that’s as much as six times faster than when we started.
From a qualitative angle, we took away the key principle that software engineering principles apply to the whole system. And the whole system is more than our application code. It’s also our build code, our release pipeline, the setup strategies for our developer and production environments, and the interrelations between those components.
So here’s our pitch to you, whether you’re writing application code, build code, release code, or all of the above: separate concerns. Think about the whole system. Design for composability. When you do, every facet of your application gets stronger — and, as a happy side effect, your build will run a lot faster too.





