

At Slack, we’ve gone through an evolution of our AWS infrastructure from the early days of running a few hand-built EC2 instances, all the way to provisioning thousands of EC2s instances across multiple AWS regions, using the latest AWS services to build reliable and scalable infrastructure. One of the pain points inherited from the early days caused us to spin up a brand-new network architecture redesign project, called Whitecastle. In this post, we’ll discuss our design decisions and our technological choices made along the way.
Down Memory Lane

In recent times, Slack has become somewhat of a household name, though its origin is more humble: the messaging service began as the internal communication tool when Slack was Tiny Speck, a game company building Glitch. Once they realised the potential of this tool, it was officially launched as Slack in 2014. It was simpler back then and there were only a few customers using it. As time went by, Slack started to evolve, and so did its infrastructure, allowing us to scale from tens of users to millions.
If you ever wondered what the infrastructure behind the original Slack looked like, it was all in a single AWS account. There were very few AWS instances in it and they were all built manually. Eventually the manual processes were replaced by scripting, and then by a Chef configuration management system. Terraform was also introduced to manage our AWS infrastructure.
As our customer base grew and the tool evolved, we developed more services and built more infrastructure as needed. However, everything we built still lived in one big AWS account. This is when our troubles started. Having all our infrastructure in a single AWS account led to AWS rate-limiting issues, cost-separation issues, and general confusion for our internal engineering service teams. To overcome this hurdle, we introduced the concept of child accounts. Now the service teams could request their own AWS accounts and could even peer their VPCs with each other when services needed to talk to other services that lived in a different AWS account. This was great for a while, but as a company we continued to grow. Having hundreds of AWS accounts became a nightmare to manage when it came to CIDR ranges and IP spaces, because the mis-management of CIDR ranges meant that we couldn’t peer VPCs with overlapping CIDR ranges. This led to a lot of administrative overhead.
Looking for a Way Out of the Pit

The Slack Cloud Engineering team had to devise ways to simplify this problem and make our lives easier. We looked at AWS shared VPCs. This was a feature AWS introduced at the end of 2018, allowing one AWS account to create VPCs and subnets, and then share those VPC and subnets to other AWS accounts.
With this concept we could create VPCs in one AWS account and share them across multiple accounts. Other accounts are able to build resources on these shared VPCs, but these resources are not visible outside that specific child account. The rate limit of their host AWS account applies to these resources as well. This solved our earlier issue of constantly hitting AWS rate limits due to having all our resources in one AWS account. This approach seemed really attractive to our Cloud Engineering team, as we could manage the IP space, build VPCs, and share them with our child account owners. Then, without having to worry about managing any of the overhead of setting up VPCs, route tables, or network access lists, teams were able to utilize these VPCs and build their resources on top of them.
Great New Build

With all these benefits in mind, we kicked off a project to build this out. We decided to call this project Whitecastle, because the lead engineer of the project conceived the idea while visiting the White Castle burger chain.
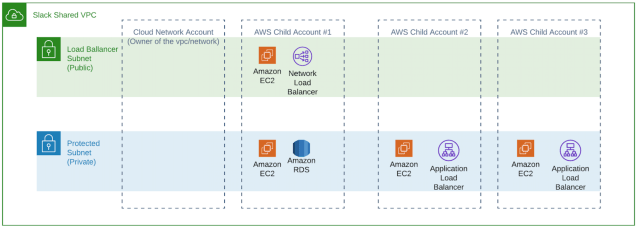
So what does this all look like? We created three separate accounts, one for each development environment here at Slack (sandbox, dev and prod). Service teams use the sandbox environment mostly for experimentation purposes while they use the dev environment for all pre-production testing. The prod environment is used for all customer facing workloads. Therefore, the Cloud Engineering team must treat the three environments as production since we are bound by SLOs to our internal customers. We also built a separate sandbox network called Bellwether just for those of us in the Cloud Engineering team to use for experimentation. This environment is not accessible to Slack’s service teams so we can test our changes, experiment, or break things without affecting anyone outside the Cloud Engineering team.
In each of these networking accounts in the us-east-1 region, we created a VPC with two /16 CIDR ranges (the biggest CIDR range AWS allows) and shared these VPCs with all our child accounts. Two /16 CIDR ranges provide over 130,000 IP addresses per region – more than enough to serve our current capacity and projected capacity for the foreseeable future. As we approach capacity, we are easily able to add more /16 CIDRs to these VPCs.
Once the build-out was completed for the us-east-1 region, we repeated the build-out for all other regions that our current AWS infrastructure operates in.
Our next challenge was to get all these remote regions to communicate with each other successfully, since we run customer facing workloads such as image caching for fast response times in several regions. However, the regions need connectivity between each other and our main region us-east-1 for various operations such as service discovery. For this we looked into another AWS feature that was introduced in late 2019 called Transit Gateway Inter-Region Peering. As a start, we created a Transit Gateway in each region and attached it to the region’s local VPC. Then a given Transit Gateway was peered with another Transit Gateway to build inter-region connectivity.
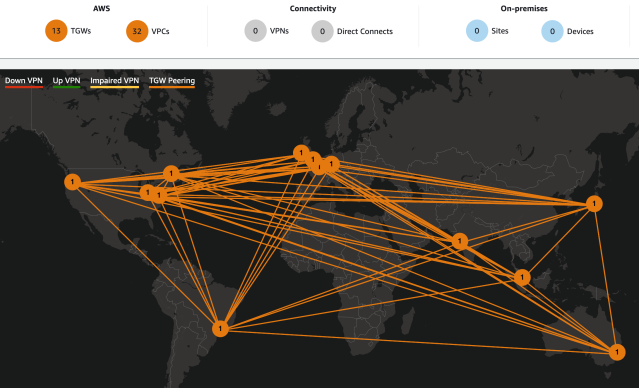
With AWS Transit Gateway Inter-Region Peering, one Transit Gateway must request the peering connection and the other Transit Gateway must accept it. Then routes must be added to each Transit Gateway’s route tables to be able to route traffic between each other.
The tricky part was figuring out how to choose which Transit Gateway to request the peering connection from, and which Transit Gateway to accept it, because we had to automate all this using Terraform. We decided to use the md5sum of the Transit Gateway ID given they are unique. During the Terraform run, we calculate the md5sum of all Transit Gateways. Then we take the last 16 characters of the md5sum and convert it into an integer. We called this number the Transit Gateway priority. If a given Transit Gateway has a greater priority number to another Transit Gateway, we choose that to be the requester and the other to be the accepter.
At the same time, Terraform updates the route tables of each Transit Gateway to be able to route traffic between each other. When we allocated CIDR ranges to our regions, we ensured all CIDRs fall inside the summary route of 10.0.0.0/8. To make sure each VPC sends any non-local traffic to the Transit Gateway that matches this summary route, we created a default route 10.0.0.0/8 in each VPC’s route table pointing at its local Transit Gateway so as to keep the VPC route tables relatively simple.
Not Getting Lost in the Mesh

There are many routes and many VPCs that need to talk to each other. A single bad route will render a service unable to talk to another service, and things can go bad very, very quickly. To remedy this, we decided to include real-time network testing. We built a very simple Go application called Whitecastle Network Tester, and then built an autoscaling group with a single instance running this application in each of our VPCs. This application registers its VPC ID, environment, and the IP of the instance in a DynamoDB table. We call this our Whitecastle Network Tester service discovery table.
The Whitecastle Network Tester application does two things:
- It starts a simple web server on a new thread and responds to HTTP requests on the /health endpoint with a HTTP 200.
- It also performs the following tasks automatically:
- Read a configuration file and find out what environments it needs to connect to
- Looks up the service discovery DynamoDB table for the IPs in that environment
- Tests connectivity to each of them
- Writes the results to CloudWatch in a designated account by assuming a role
We display this CloudWatch data source on a Grafana dashboard to monitor and alert based on any failing network test results.

Our Whitecastle Network Tester also validates the build-out of new regions by adding test cases pre-build-out and then creates connectivity between the new/old regions and the legacy VPCs. With this approach, we can see any tests failing to start, but then moving to a pass state as the build-out completes.
The current process of applying any changes to the Whitecastle network is to initially make changes and test them in the sandbox environment, then deploy the same changes to the dev environment. Once we are confident with our changes, we follow through to the prod environment. Having real-time network testing allows us to catch any issues with our configuration before these changes make it to the production environments. The Whitecastle Network Tester helped tremendously in developing a network mesh Terraform module, as we could validate the changes deployed by each Terraform apply command to network routes and resources.
How Do We Migrate to the Great New World?
Once we had this all built, the next step was to get our internal customer teams to migrate their services onto the Whitecastle network and into child AWS accounts. However, big-bang migrations are cumbersome and risky and it was difficult to convince Cloud Engineering’s internal customer service teams to take the leap initially.
If we offered incremental migration to the new network architecture, then there would be much more buy-in from service teams, so we engineered a simple solution for that, by sharing the new Transit Gateway to child accounts and attaching them to the region’s legacy VPC. With this approach, if a portion of the services moved onto the new VPCs, they’d still be able to communicate with parts of the system located in the legacy VPCs.
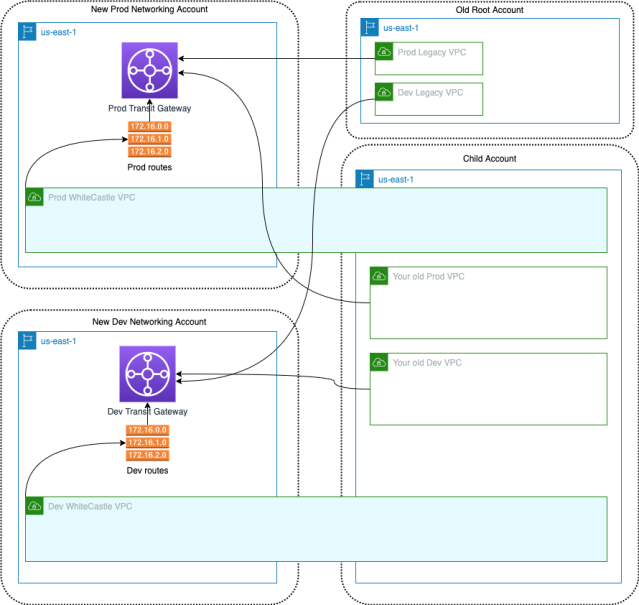
Although the sandbox environment is not shown in the above diagram, it works in a similar way to the dev environment.
All in all, we found a lot of success in building this new network architecture. There were many challenges along the way, but we managed to work through them and learn a great deal. Once we started running production workloads in Whitecastle, we stopped making ad hoc changes to all three environments that could impact our internal customers. It also meant we adopted a reliable and safe process to rollout changes. Having a sandbox environment dedicated to the Cloud Engineering team to test concepts and experiment helped catch any issues before pushing changes out to customer-facing environments. Tools like Whitecastle Network Tester give us confidence in rolling out our changes and also alerts us promptly if any problems slip through our testing. All these safety measures give us the ability to provide extremely satisfying SLAs such as high reliability and availability to the Cloud Engineering team’s internal customers. Having said all that, we are still looking for ways to improve our platform by adopting the latest technologies available to us. As an example, we will be looking at replacing all our inter-region route propagation logic once AWS releases BGP route propagation support for Transit Gateway peerings.
We are certain there will be many more challenges to overcome and lessons to learn as we move more services onto the new network architecture. If this work seems interesting to you, Slack is always on the lookout for new engineers to help us build great new things, and you can join our ever growing team.





