


Deploys require a careful balance of speed and reliability. At Slack, we value quick iteration, fast feedback loops, and responsiveness to customer feedback. We also have hundreds of engineers who are trying to be as productive as possible. Keeping to these values while growing as a company means continual refinement of our deployment system. We had to invest in greater visibility and reliability in order to accommodate the amount of work being done. This post will outline our process and a few of the major projects that got us to where we are.
How deploys work today
Every pull request at Slack requires a code review and all tests to pass. Once those conditions are met, an engineer can merge their code into master. However, merged code is only deployed during North America business hours to make sure we are fully staffed for any unexpected problems.
Every day, we do about 12 scheduled deploys. During each deploy, an engineer is designated as the deploy commander in charge of rolling out the new build to production. This is a multistep process that ensures builds are rolled out slowly so that we can detect errors before they affect everyone. These builds can be rolled back if there is a spike in errors and easily hotfixed if we detect a problem after release.
1. Create a release branch
Each release starts with a new release branch, a point in our Git history that allows us to tag the release and a place where we can cherry-pick in hotfixes for issues discovered during a rollout to production.
2. Deploy to staging
The next step is to deploy the build to the staging servers and run an automated smoke test. Staging is a production environment that does not accept public traffic. We perform additional manual testing in staging because it gives us a higher degree of confidence that the change will work correctly than if we only tested in our development environment.
3. Deploy to dogfood and canary
The rollout to production starts with the dogfood tier, a set of hosts that serves some of our internal Slack workspaces. As we’re very active Slack users ourselves, dogfooding has helped catch many problems early. Once we are confident that core functionality is unchanged, the build is deployed to canary, which has about 2% of production traffic routed to it.
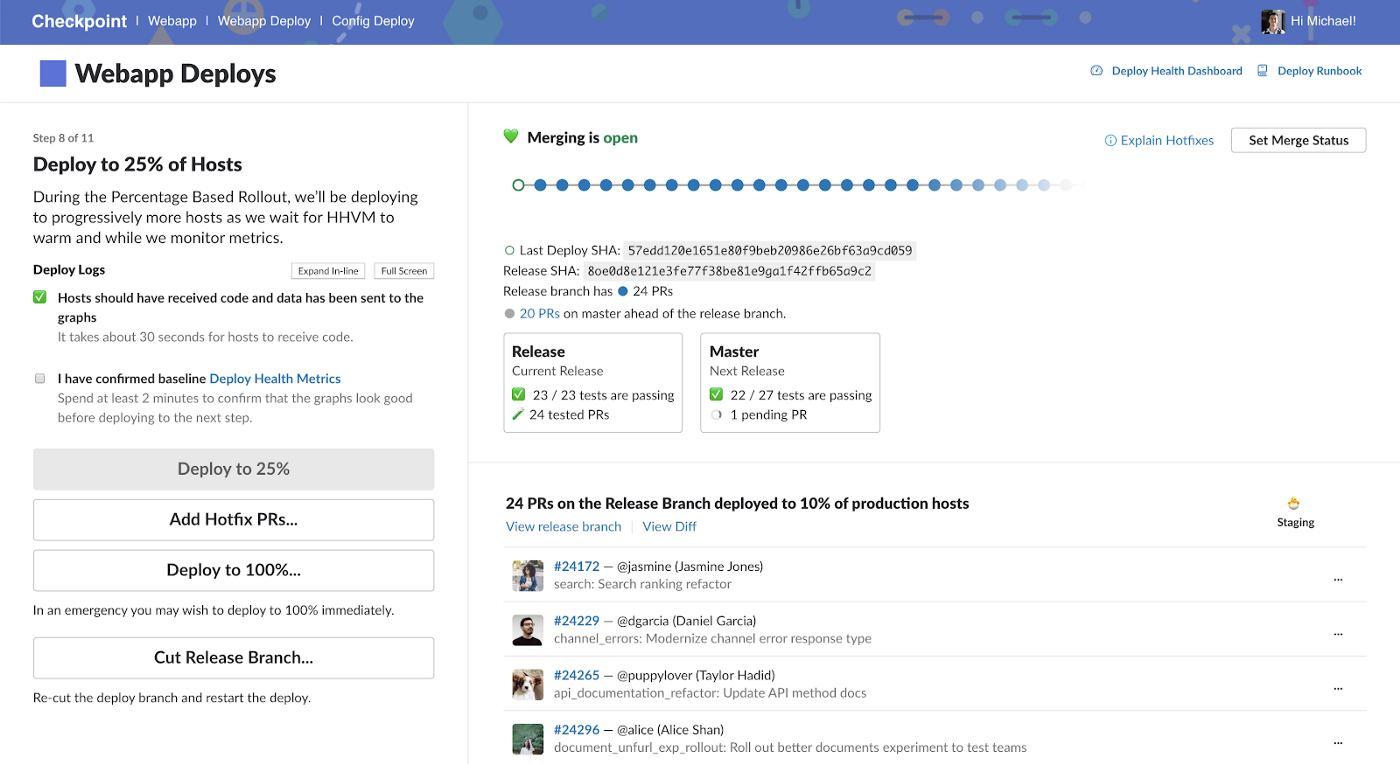
4. Percentage-based rollout to production
If the charts remain stable and if there are no outstanding alerts, we continue with a percentage-based rollout to production. We break up the rollout in 10, 25, 50, 75, and 100 percent increments in order to slowly expose production traffic to the new build while giving us time to investigate if there are any spikes or anomalies.
What if something goes wrong during a deploy?
Modifying code always presents risk, but we manage this by having trained deploy commanders at the helm of every new release, watching the charts and coordinating communication with the engineers pushing code out.
In the event that something does go wrong, we aim to catch it as early as possible. We investigate the issue, identify the PR that is causing problems, revert it, cherry-pick in that revert, and make a new build. However — sometimes we don’t catch a problem before it reaches production. In this scenario, it’s critical to restore service, so we immediately roll back to a previous working build before starting our investigation.
Building blocks
Fast deploys
The workflow described above may seem obvious in hindsight but our deploy system went through many iterations in order to get there.
When the company was much, much smaller, our entire application could run on 10 Amazon EC2 instances and a deploy just meant a quick rsync to all the servers. There used to be just one tier before production: staging. Builds would be made, verified on staging, and then go straight to all production servers. This system was simple to understand and allowed any engineer to deploy their own code at any time.
But as the number of customers grew, so did the amount of infrastructure it took to run our application. Soon, our push-based deploy model couldn’t cope with the number of servers we were adding. Each additional server increased deploy time. Even strategies like parallel rsyncs had their limits.
Eventually, we resolved this issue by switching to a fully parallel pull-based system. Instead of pushing the new build to our servers using a sync script, each server pulls the build concurrently when signaled by a Consul key change. This allows us to maintain a high velocity of deploys even as we continue to scale.

Atomic deploys
Another project that paved the way for tiered deploys was atomic deploys.
Before atomic deploys, each deploy would cause a burst of errors as the process of copying over new files onto the production servers wasn’t atomic. This resulted in small windows where call sites of new functions were available before the actual functions. When these call sites were invoked, they returned internal errors that manifested in failed API requests and broken web pages.
The team that rallied around this issue resolved this by using hot and cold directories. The hot directory would serve production traffic, while the cold directory was being prepared. During a deploy, the new code would be copied to the unused cold directory. Then, once the server was drained of active processes, we would switch directories instantaneously.

Refocusing on reliability
In 2018, we hit a point where deploying as fast as possible was hurting the stability of our product. We had a very capable deploy system that was being heavily invested in but the process around deployments had to evolve. Reliability took center stage as we became a bigger company that powered increasingly more mission-critical collaboration around the world.
The need for safer deploys led us to overhaul our deploy system, which resulted in the percentage-based deploy system described earlier. Under the hood, we continue to use fast deploys and atomic deploys, but we changed the way we carry out deploys. This system rolls out changes in tiers, which — coupled with much better monitoring and tooling — grants us the ability to catch and mitigate bugs before they have the chance to affect all users.
But we’re not done yet — we’re continually improving this system through better tooling and automation. Stay tuned for more posts along these lines in the future.
A special thanks
Deployments at Slack consist of a complex set of systems with contributions from many teams across the engineering org. The work discussed in this post summarizes work led by the following people and projects:
- Atomic Deploys: Saroj Yadav, Chase Jenkins, Jamie Scheinblum
- Deploy UI: Andrew Morrison, Zack Sultan, Jonathan Chang
- Fast Deploys: Paul Hammond, Joe Smith
- Percentage-based Rollouts: David Stern, Harrison Page, Travis Crawford, Tricia Bogen
- Dogfood Tier: Derek Smith, Jamie Scheinblum, Eve Killaby
- Workflow and Process: Pooja Rana, Karen Xu
Authors
Jonathan is a Staff Software Engineer, based out of our San Francisco Office. While at Slack, he works on internal tools and is currently with the release engineering team. His focus is on front end development but is known to do a little bit everything.
Michael is a Software Engineer on the Platform team at Slack. He has been working at Slack for almost 3 years, and in that time, he has worked on a wide-ranging feature set, including user-facing products, API infrastructure, and growth experiments.





