Slack handles billions of inbound network requests per day, all of which traverse through our edge network and ingress load balancing tiers. In this blog post, we’ll talk about how a request flows — from a Slack’s user perspective — across the vast ether of the network to reach AWS and then Slack’s internal services. Let’s dive in!
How packets flow
Our edge network consists of a set of globally-distributed edge regions or AWS datacenters that we call edge PoPs. These edge PoPs sit closer to our users to reduce latency, improve performance, and connect them back to Slack’s main region in the AWS us-east-1. This is the region where our storage and core services live, and we heavily invested in availability zone (AZ) resilience to overcome any issues on a given datacenter/AZ. See Slack Cellular Architecture for more information on how we configure our AWS instances.
Requests to Slack can be broadly classified into two categories: websocket and non-websocket. The services running in the edge regions are called Edge Services and are responsible for handling incoming requests. We will look at both these types in detail in later sections but first let’s look at how packets flow to our edge PoPs from a client’s perspective (without going into too much detail on how DNS resolution works).
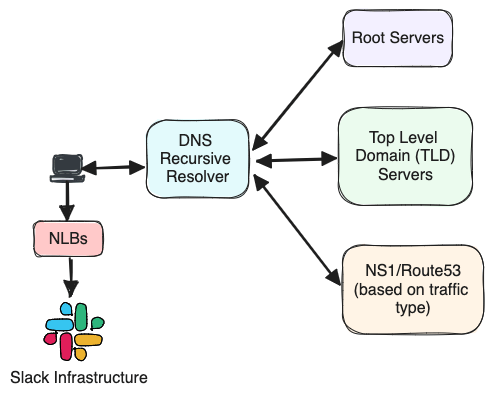
When a user launches the Slack client, it will make many DNS requests in the background to resolve slack.com, wss-primary.slack.com, slack-edge.com, and any other domains we use. If the DNS request is not resolved from the local cache, it will get resolved through the configured DNS recursive resolver, and ultimately gets answered by the authoritative name server. All this is done even before the client finishes loading.
Slack uses Amazon Route53 (R53) as the authoritative name server for most of our domains. Additionally, all websocket records are sub delegated to NS1 for websocket traffic. We use NS1 because of its highly configurable Filter Chain and capability to perform load-shedding. Both NS1 and Route 53 provide us the ability to route requests to the region closest to the user. This is possible thanks to the edns-client-subnet extension (ECS); it’s a DNS extension that provides an EDNS0 option to allow Recursive Resolvers to forward details about the origin network from where the query is coming from when talking to other nameservers. See RFC 7871 for more information.
The DNS lookup response is formed by a list of IP addresses for the region closest to the user. The client will then pick a random IP address from the list to talk to. These IP addresses are public facing Network Load Balancers (NLB) which front both the websocket and non-websocket stacks and are configured to be used in pass-through mode (Layer 4 load balancer); they just forward the network packets to either websocket or non-websocket load balancing stacks (Layer 7) at the edge.
The client then opens up an HTTPS connection with Slack servers, which upgrades the connection stream to a websocket connection. At this point the user is ready to send a message on Slack.
When a packet leaves a regional PoP towards our main region, encrypted traffic (thanks to Nebula) will traverse through the AWS backbone — which makes us less vulnerable to external fiber cuts or peering issues between our PoPs and main region.
WebSocket traffic
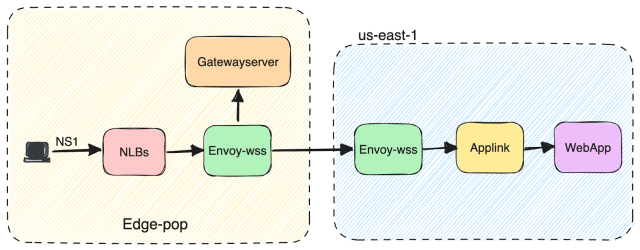
Slack uses websocket connections for sending and receiving messages. These websocket connections are ingested into a system called “envoy-wss” (websocket Service backed by Envoy Proxy) and accessible from the internet using wss-primary.slack.com and wss-backup.slack.com DNS domains. These DNS records are maintained by the third-party service NS1 as mentioned above.
When a DNS request for wss-primary.slack.com domain reaches NS1, it uses a set of Filter Chains to route that traffic to our NLBs within a specific region. The filters in the Filter Chain are applied in the order they are mentioned. NS1 will point the request to the NLB(s) in the region closest to the customer (based on the client subnet information) which is up/available and has capacity as shown in the diagram below. Details of each filter can be found here.

Once the request reaches the NLB in a specific region, it goes to envoy-wss which is a set of envoy servers dedicated to handling our websocket traffic. TLS termination happens there and based on request parameters, the request is routed to either Gatewayserver or Applink.
Gatewayserver is an internal service that maintains websocket connections at Slack. Refer to this blog post to learn more about how real-time messaging happens at Slack over websocket connections.
Applink is an internal service designed to lighten the burden of security for customers when building apps that need to receive data. It allows customer apps to connect to a websocket and receive their event subscriptions over the socket.
Flailover \o/
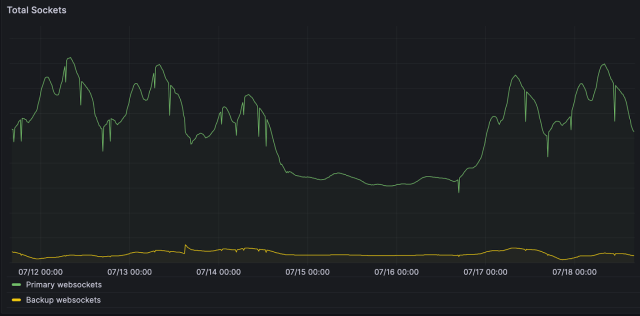
We talked about how clients send and receive messages over a websocket connection when things are doing okay but what happens if wss-primary.slack.com is inaccessible/unavailable?
Our Slack clients are configured to try wss-backup.slack.com when wss-primary.slack.com is unavailable with backoff/jitter and lots of client-side goodies to make this safe. The difference between these two DNS records is in terms of what NS1 Filter Chain is configured and in what order these filters are applied, as shown in the diagram below.

NS1 will still select the regions for a request based on their availability and capacity, but this time it selects the three closest regions instead of just one, and diverts traffic to alternate regions in case of a failure. This means if, for some reason, there is an issue with our Dublin PoP, NS1 will spread the new connections among Dublin, Frankfurt, and London. This also means that one-third of the backup connections might get routed to the same failed region, but that actually works better for us and helps prevent the thundering-herd issue. Slack clients will fairly quickly retry and connect to a good region again due to a short DNS Time To Live (TTL).
Degraded mode \o/ \o/

Murphy’s law says “Anything that can go wrong will go wrong.” So we had better plan for it. Imagine what happens if, for some reason, the Slack client can’t establish a successful websocket connection to both wss-primary.slack.com and wss-backup.slack.com.
Many years ago, a failure in establishing a websocket connection meant that customers were unable to use Slack’s basic features. Slack clients may load but they couldn’t send or receive messages, or browse channels and users. Slack was, dare I say, un-usable!
Degraded Mode is a limited-functionality state where a desktop or a supported internet browser client can communicate with the Slack API, but cannot maintain a websocket connection. Degraded mode appears as a gray banner on top of the Slack client. With Degraded Mode, customers can continue using most basic features of Slack, like sending messages and browsing channels. This is because many of these features rely on our Slack APIs, not websockets. When “Load more messages is clicked”, the client will load new messages in the channel, update the channel list, and then the gray bar disappears. This functionality is critical for keeping Slack clients usable and has helped us many times over the last few years in maintaining our high customer Service Level Agreement (SLA).
Edge API traffic
All non-websocket traffic—for example, Slack API, slackbot, webhooks, and third-party apps—flow through our edge API stack, or envoy-edge. These are the set of envoy servers dedicated to API traffic.
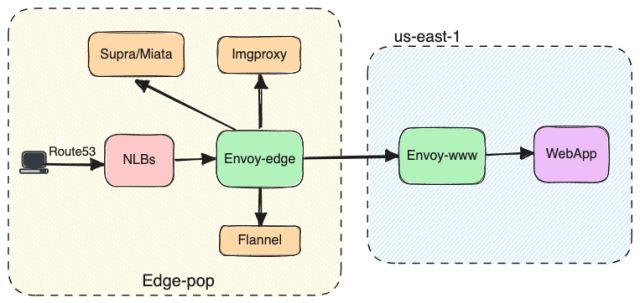
Traffic is ingested to this stack via various DNS domains, for example app.slack.com (API traffic destined for Webapp), edgeapi.slack.com (Slack’s user and channel information), files.slack.com (file upload and download), and slack-imgs.com (slack image unfurling). Based on the domains that the requests came from, Route53 or NS1 will point the request to the NLBs in a region closest to the user, in terms of latency. The NLBs will forward the request to envoy-edge, which will then route the requests to different internal services listed below.
Flannel is an internal service that acts as an edge cache, used by Slack’s first-party clients and maintains critical user and channel information.
Imgproxy is another internal service responsible for proxying image content to Slack.
Likewise, Supra and Miata are internal services that are responsible for file download and file upload respectively.
Envoy-www is our internal load-balancing tier that routes API traffic destined for Webapp.
Regional failovers
We talked about how failures are handled in the case of websocket traffic. Now, let’s say, we have an issue with our service or Infrastructure in a specific region/PoP (for example, eu-west-1/DUB). We have a tool called “Edge Pop Drain” (“edge PoP traffic drain”) that will detect the issue and automatically pull service(s) away—or sometimes the region itself—from taking traffic. This is a DNS change, so any new traffic will automatically be routed to the next closest edge PoP (eu-west-2/LHR), as shown in the figure below.
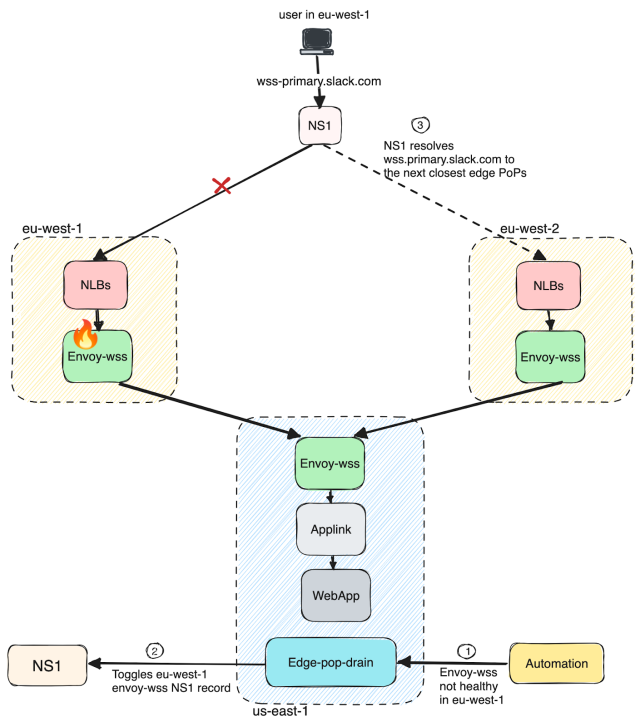
Once the region looks healthy, this tool automatically routes traffic back to the previously affected region. This is also available as a command-line tool that operators can use to manually route traffic from one region to another. It has reduced customer impact by ensuring faster regional/service failovers during incidents.
CDN
A content delivery network (CDN) is a group of distributed servers that caches content near end users providing improved performance and lower latency. Slack uses AWS Cloudfront as the primary CDN. Cloudfront has over 400 Points of Presence in 90 cities and across 47 different countries around the world.
All the static assets that are critical for booting the Slack client are served through our a.slack-edge.com domain via Cloudfront. We also have a backup CDN domain accessible via b.slack-edge.com. There is automated client-side failover logic in place that will automatically try the backup endpoint if the client does not get a response on a.slack-edge.com and back and forth with various amounts of backoff and jitter. Apart from serving static assets, we also use Cloudfront for serving images and files at the edge, as we need these resources to sit closer to the end user for a better user experience.
What’s next?
We talked about how packets flow from our user to Slack infrastructure, what are the important services that make Slack “Slack”, and how these interact with each other in both best and worst case scenarios. Hope y’all find it interesting. We’re also working on a future blog post about how regional failovers work and how we have automated renewing SSL certificates at Slack. Keep your eyes peeled because it’ll be posted here soon!
Want to help Slack solve tough problems and join our growing team? Check out all our open positions and apply today!