

Artwork courtesy of the Jenkins project.
At Slack we manage a sophisticated Jenkins infrastructure to continuously build and test our mobile apps before release. We have hundreds of jobs running in a variety of different environments. One day something very odd happened — our Jenkins UI stopped working although the jobs continued to run. This post is a breakdown of how we ended up in this state and how we fixed the problem. From this experience, we’re also sharing some general-purpose tips on troubleshooting a Jenkins issue.
Sample Original UI:
Broken UI:
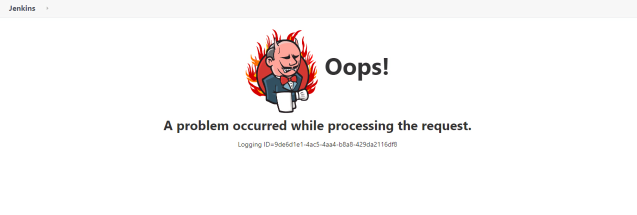
A little history
As part of our automation setup, we continuously run integrity jobs to inspect our Jenkins nodes. These jobs check system configurations and properties and look to see if any node is failing those checks. The checks automatically mark Jenkins nodes as offline when any of those checks fail and notifies our Mobile Build & Release team via a Slack message.

When our Jenkins UI stopped working, we noticed two things:
- We had recently upgraded Jenkins and all its plugins to a newer version
- The integrity job ran and failed on one of our Jenkins nodes
With this knowledge, and after restoring the Jenkins UI by rebooting the main instance so that our dev teams were unblocked, we started our investigation.
Going down the rabbit hole
We thought that there was some connection between the integrity job and the UI, but the error message from the UI didn’t reveal much. We then tried to reproduce the error. In a separate Jenkins staging environment, which was running the same Jenkins version and plugins as our Jenkins production environment, we manipulated one of the nodes on purpose and reran the integrity job. And again, the UI broke, so we could reproduce the issue.
We noticed the following error in the logs of the job:
expected to call
hudson.slaves.SlaveComputer.setTemporarilyOffline
but wound up catching OfflineMessage.toString; see:
https://jenkins.io/redirect/pipeline-cps-method-mismatches/
Note: “hudson.slaves” is part of the interface that Jenkins provides; in our own code at Slack, we’ve fully moved over to “controller” and “agent” as the preferred terminology.
We use a common pattern that calls the Jenkins Java API with an instance of the OfflineMessage class to provide the cause of a particular node getting marked as offline to provide context:
def markNodeOffline() {
def node = getCurrentNode(env.NODE_NAME)
node.toComputer().setTemporarilyOffline(
true, OfflineCause.create(new OfflineMessage())
)
}
class OfflineMessage extends org.jvnet.localizer.Localizable {
def message
OfflineMessage() {
super(null, null, [])
def timestr = new Date().format(
"HH:mm dd/MM/yy z", TimeZone.getDefault()
)
this.message = "The node was taken offline at ${timestr} due to corrupted host file"
}
String toString() {
this.message
}
String toString(java.util.Locale l) {
toString()
}
}We added the typical @NonCPS annotation to the affected methods (toString()) and retriggered the job. The error was gone from the job logs, but the Jenkins UI still broke. So while it might have been related to the missing annotation, this change did not resolve the issue. Reproducing the behavior once more, we started tailing the Jenkins logs while trying to load the UI. We noticed the following error:
2020-12-05 02:44:44.201+0000 [id=24] WARNING h.i.i.InstallUncaughtExceptionHandler#handleException: Caught unhandled exception with ID a4bf874a-5029-4f37-b6e6-217ca8bb76de org.apache.commons.jelly.JellyTagException: jar:file:/var/cache/jenkins/war/WEB-INF/lib/jenkins-core-2.235.5.jar!/hudson/model/Computer/index.jelly:63:66: Rejecting unsandboxed property get: OfflineMessage.message Clearly, something about the OfflineMessage class breaks the Jenkins UI. But what?
A quick GitHub search revealed the source of the error message:
@Override
public Object onGetProperty(
Invoker invoker, Object receiver, String property
) throws Throwable {
throw new SecurityException(
"Rejecting unsandboxed property get: " +
getClassName(receiver) + "." + property
);
}Tracing back the origin of this code change, we found out that a recent CVE (CVE-2020-2279) had been addressed by the Jenkins maintainers. As one of the security fixes, the groovy-sandbox restricted the access for certain interactions. The library was packaged in the Script Security Plugin, which had been updated with our latest Jenkins upgrade. A temporary downgrade of the plugin in our staging Jenkins environment and a rerun of the pipeline confirmed our theory. The UI didn’t break this time as we found the root cause. Now, let’s fix it!
A few lines and everything is fine again
Sandboxing in Jenkins is often the root cause of build pipeline issues, and so our goal was to replace the OfflineMessage class with something simpler to avoid similar issues. As it turns out, the Jenkins Java API provides a straightforward interface that takes a String as parameter to describe the cause of a node being offline (as compared to an instance of a class that implements Localizable): hudson.slaves.OfflineCause.ByCLI. Instead of implementing our own message class, which internally also used a String for the offline cause message, we now simply call the ByCLI constructor:
def createMessage() {
def timestr = new Date().format(
"HH:mm dd/MM/yy z", TimeZone.getDefault()
)
"The node was taken offline at ${timestr} due to corrupted host file".toString()
}
def markNodeOffline() {
def node = getCurrentNode(env.NODE_NAME)
node.toComputer().setTemporarilyOffline(
true, new OfflineCause.ByCLI(createMessage())
)
}With the fix rolled out, we enabled our Jenkins integrity check job again and were able to confirm it didn’t break the Jenkins UI anymore. Hurray!
Takeaways on Jenkins troubleshooting
There are few lessons learned here that universally apply to the management and troubleshooting of a Jenkins-powered CI/CD infrastructure.
- Maintain different Jenkins environments that mirror production.
It pays to have separate environments and to follow staged rollouts, especially in the cloud, to reduce the blast radius and detect potential issues early on as features and new capabilities get shipped to users as quickly as possible. Having a dedicated Jenkins staging environment that mirrors our production environment provided us the perfect experimentation ground to confirm our hypotheses on the root cause of issues. Maintaining the mirror requires effort to ensure parity between the environments (e.g. plugin versions) and customizations to Jenkins jobs to execute in “dry-run” mode in non-production environments. We account for this in our maintenance tasks and pipeline setups.
- Stay lean with Jenkins API integrations.
Jenkins is powerful and exposes many convenient functions to pipelines that run on it. For anything that goes beyond the standard capabilities, Jenkins allows customizations through its API that can be backed into Jenkins pipeline libraries and custom Groovy code. However, this tightly couples pipelines and jobs to the underlying Jenkins infrastructure. So, we recommend keeping custom integrations with the Jenkins API as lean and simple as possible to lower the risk of getting caught off guard when Jenkins releases or plugin updates introduce breaking changes.
- Keep an eye on the Groovy sandbox and plugin updates.
Groovy is typically the language of choice for extending Jenkins with custom code. It gets executed in a special Groovy sandbox to increase the security posture. The Jenkins maintainers do an amazing job keeping the sandbox’s security level high (e.g. addressing CVEs), which often leads to tightened defaults. This can catch teams by surprise, especially when updating the plugin as a regular maintenance task. Studying changelogs is always advised, but especially recommended for core plugins of the Jenkins ecosystem.
- Have a well-maintained runbook.
Continuously-updated and well-documented runbooks can save you from headaches and many hours spent reading Jenkins logs. This actually applies universally to the DevOps world. In our case, this means a thoroughly documented upgrade process for the Jenkins core and crucial plugins. It also means having all important pipelines and Jenkins jobs that interact with the Jenkins API included in our upgrade and validation processes.
Closing notes
Going down the rabbit hole of Jenkins internals showed us the advantages of our staging environment, but also revealed shortcomings in our upgrade processes. We hope this troubleshooting has been as insightful to you as it has been to us!
If you find this interesting and like using modern tools, come join us! https://slack.com/careers





