
At Slack, proactively securing our systems is a top priority. One way we achieve this is by automating the detection of security issues with static code analysis, which are tools that inspect programs without executing them. They’re often used with security-based rules to automate identification of vulnerabilities and insecure programming practices, which frees up more bandwidth for security engineers. For us, expanding our static code analysis program became critical as we looked to grow into the public sector, where there are rising demands to show our feature work is secure and to meet security certification requirements. We view static code analysis as guardrails; it prevents the worst kinds of security vulnerabilities from joining our codebases. As a result, static code analysis has been top of mind for the security team at Slack for the past three quarters and remains one of the major focuses for next quarter.
Our codebase is largely written in Hack. While Hack comes from work that Facebook performed to develop a typed version of PHP, it is a separate language and there are no static analysis tools broadly available for it. Given that over 5 million lines of code at Slack are written in Hack, how can we ensure it remains secure at scale?
The problem
This past summer, we (Nicholas Lin and David Frankel) focused on solving this problem as software engineering interns on the Product Security team.
Building a static analysis tool for Hack
Building a static analysis tool from scratch would be extremely complex, and the high costs would easily exceed the benefits. Instead, we decided to extend an existing open source tool, Semgrep. At Slack, we use Semgrep to scan our code for vulnerabilities in six different languages and have existing infrastructure to integrate Semgrep in our CI/CD pipeline. Our decision was a combination of realizing we could leverage Slack’s existing static analysis tool and that a net-new tool would be a huge engineering lift for the team. But how would we teach Semgrep the Hack programming language? We reached out to the developers of Semgrep at r2c and distilled the complex process to two major questions:
- What are the grammar rules for the Hack language?
- How can Semgrep understand these grammar rules?
Developing a grammar for Hack
Like all human languages, programming languages have a structure to them known as a grammar. Since the grammar rules define the source language, we can write grammar rules to define Hack. We then apply these grammar rules to any given source code and derive a structural understanding of the code or concrete syntax tree (CST). A CST is an exact visual representation of the parsed source code based on the grammar.
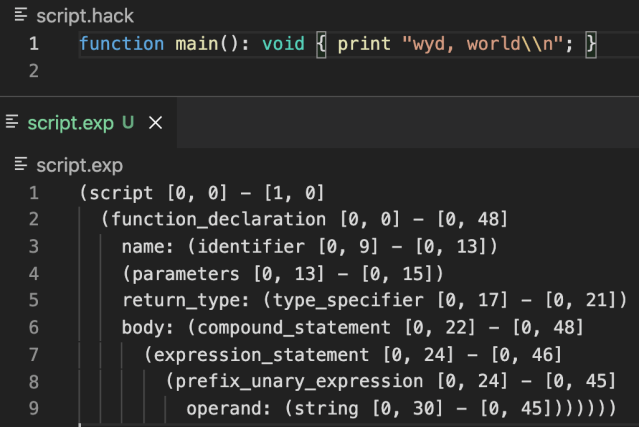
Example tree-sitter CST (bottom) generated from Hack source (top)
To perform this conversion we use Tree-sitter, a fast and robust library that generates a parser from grammar rules. The generated parser is used to convert source code to a CST. The tree-sitter CST has many use cases such as robust syntax highlighting, code folding, and linting. Most importantly for our use case, Semgrep can use the tree-sitter CST to understand Hack on a semantic level. This can be summarized by the following diagram.
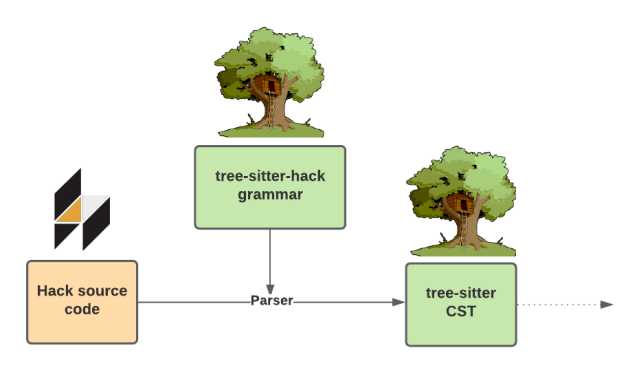
Converting source code to a CST
Luckily, Slack Backend Engineer Antonio Ochoa Solano had already been developing a grammar for Hack as a personal project:
“I’m often frustrated when I find a useful tool for one programming language and can’t use it with other languages. So I was excited when I learned about Tree-sitter and the promise of an ecosystem of developer tools that are extensible to any language. I started working on the Hack grammar to learn how Tree-sitter works and as a way of contributing to the project.”
We worked closely alongside Antonio, building upon his foundation and incrementally improving the grammar. We repeatedly ran our grammar against internal repositories and prioritized writing grammar rules based on error count. The key metric that we used to measure the performance of the grammar was the parse rate, the proportion of code that could be properly parsed to construct a CST. We were able to achieve a parse rate of greater than 99.999% out of over 5 million lines of code by reducing the number of unparsable lines from more than 120,000 to 15.
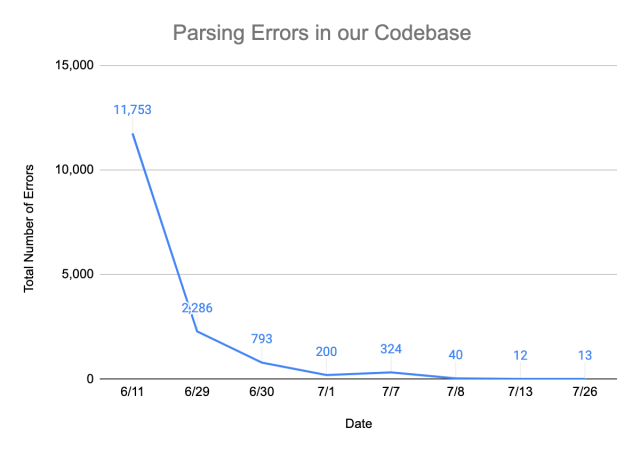
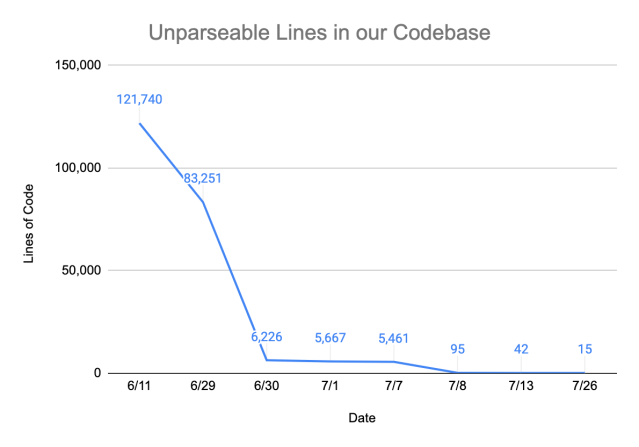
We are happy to share that the grammar is open sourced at GitHub, and we’re continuing to update the grammar to reach a 100% parse rate.
Teaching Semgrep the grammar
Unfortunately, Semgrep cannot use a Tree-sitter CST directly. Instead, it relies on an abstract syntax tree (AST) to understand the grammar. An AST only captures essential information, excluding unnecessary syntax such as comments or syntax that can be derived from the tree’s structure such as parentheses. Furthermore, the Semgrep AST provides a common structure for Semgrep to understand any programming language. Instead of having a separate CST or AST for every programming language, they are all mapped to a common Semgrep AST. This means that Semgrep is loosely coupled with each language, making it a highly extensible tool. The semantic understanding of the language from the AST in conjunction with Semgrep rules can detect vulnerabilities in source code. This process is demonstrated in the diagram below.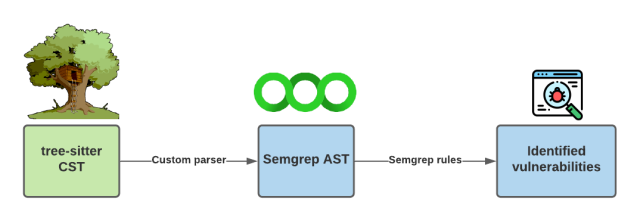
Semgrep using tree-sitter
In order to map the tree-sitter CST to the Semgrep AST, we had to write a custom parser file in the OCaml programming language. This was also a highly incremental process:
- Identify a Hack language construct
- Observe the implementation of the construct in the grammar and CST
- Identify the proper mappings in the AST
- Implement the mapping accordingly
This was the most intensive part of the project as it involved drawing knowledge from a lot of different areas — Hack, Tree-sitter, Semgrep, and OCaml. We were able to make steady progress by focusing on each construct individually and meeting with r2c for clarification. We currently have a parse rate of 99.9%, and we’re continuing to update the parser to reach a 100% parse rate. After the custom parser is complete, all that is left is to write a set of Semgrep rules. Semgrep applies these rules to the AST in order to find security vulnerabilities.
Leveraging Semgrep’s pattern matching
With our end goal in sight, we could begin the final step necessary before using Semgrep rules to identify risky code. Semgrep rules are written with a special syntax, but this syntax is not parsable in Hack. For example, let’s say we want to prevent calls to MD5, a common insecure hashing algorithm. In Hack, this may look like this: `md5(“some string to hash using md5, an insecure algorithm”)`. We want to flag this function call, so our Semgrep rule pattern will look something like this: `md5(…)`. In this case, the ellipses represent any arguments because we want to identify all calls to this function. In order to correctly identify these ellipses in our AST, we extended the Tree-sitter parser to track Semgrep-specific syntax. This allows us to write increasingly complex rules, like checking nested function calls and statements. If you’re interested in learning more about this syntax, r2c’s docs cover it in much more detail.
At Slack, we use Semgrep rules to ensure we safely handle user input, complete authentication, and more. This allows us to leverage Semgrep for OWASP Top Ten vulnerability checking across all of our Hack code and protect our systems. In the future, we hope to share these rules with the larger community so anyone can easily write safer and more secure Hack code.
Putting it all together
In summary, the raw text of the Hack source code first gets mapped to a CST (primitive structural representation) then generalized to an AST. Semgrep uses the AST and security rules to identify potential vulnerabilities. This processes is illustrated below: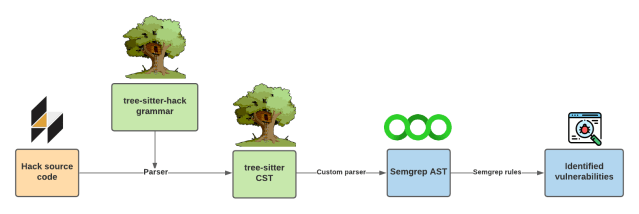
Adding Hack support to Semgrep
The Hack implementation for Semgrep will run on new code before a developer can deploy it to production and runs daily on the entire codebase. This work will proactively secure Slack by automating the discovery of vulnerabilities and preventing their introduction in Slack’s largest codebase, making Slack more secure for everyone!
Are you interested in helping to secure a product used by millions? Join us!
References
- Bug icon in diagram made by Freepik





