


Slack, as a product, presents many opportunities for recommendation, where we can make suggestions to simplify the user experience and make it more delightful. Each one seems like a terrific use case for machine learning, but it isn’t realistic for us to create a bespoke solution for each.
Instead, we developed a unified framework we call the Recommend API, which allows us to quickly bootstrap new recommendation use cases behind an API which is easily accessible to engineers at Slack. Behind the scenes, these recommenders reuse a common set of infrastructure for every part of the recommendation engine, such as data processing, model training, candidate generation, and monitoring. This has allowed us to deliver a number of different recommendation models across the product, driving improved customer experience in a variety of contexts.
More than just ML models
We aim to deploy and maintain ML models in production reliably and efficiently, which is termed MLOps. This represents the majority of our team’s work, whereas model training is a relatively small piece in the puzzle. If you check out Matt Turck’s 2021 review talking about the ML and data landscape, you’ll see for each phase of MLOps, there are more tools than you can choose from on the market, which is an indication that industry standards are still developing in the area. As a matter of fact, reports show a majority (up to 88%) of corporate AI initiatives are struggling to move beyond test stages. Companies such as Facebook, Netflix, Uber usually implement their own in-house systems, which is similar here in Slack.

Fortunately, most often we don’t need to bother with choosing the right tool, thanks to Slack’s well-maintained data warehouse ecosystem that allows us to:
- Schedule various tasks to process sequentially in Airflow
- Ingest and process data from the database, as well as logs from servers, clients, and job queues
- Query data and create dashboards to visualize and track data
- Look up computed data from the Feature Store with primary keys
- Run experiments to facilitate feature launching with the A/B testing framework
Other teams in Slack, such as Cloud Services, Cloud Foundations, and Monitoring, have provided us with additional infrastructure and tooling which is also critical to build the Recommend API.
Where is ML used in Slack?
The ML services team at Slack partners with other teams across the product to deliver impactful and delightful product changes, wherever incorporating machine learning makes sense. What this looks like in practice is a number of different quality-of-life improvements, where machine learning smoothes rough edges of the product, simplifying user workflows and experience. Here are some of the areas where you can find this sort of recommendation experience in the product:
- Composer DMs, where we suggest additional candidates to add to the conversation
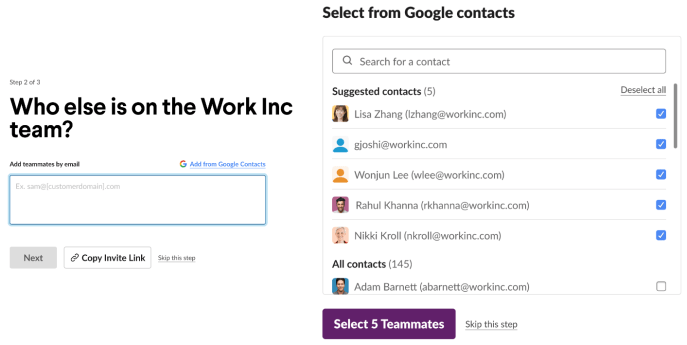
- Creator invite flow, where we suggest top contacts to invite to the workspace for team creators based on their Google calendar events
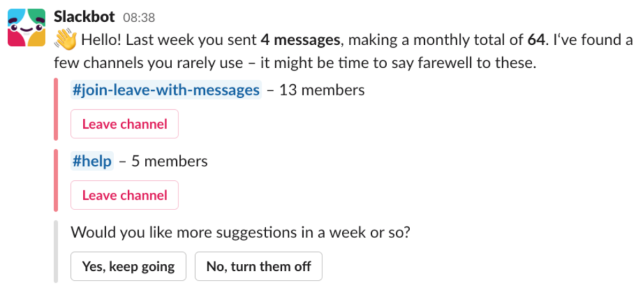
- Slackbot channel suggestions, where we suggest channels to leave or archive based on user activities
- Channel browser recommendation, the default sorting method (⌘ + ⇧ + L) when users want to view channels
- Invite reminder send-time optimization, where instead of always sending the reminder at a static, default time, we personalize the send time based on team and inviter’s activity and attributes

An important result of the Recommend API — even aside from the current use cases that can be found in the product — are the near equal number of use cases we are currently testing internally, or we have tried and abandoned. With simple tools to bootstrap new recommenders, we’ve empowered product teams to follow a core product design principle at Slack of “prototyping the path”, testing and discovering where machine learning makes sense in our product.
Machine learning, when built up from nothing, can require heavy investment and can be quite hit-or-miss, so previously we avoided trying out many use cases that might have made sense simply out of a fear of failure. Now, we’ve seen a proliferation of ML prototypes by removing that up-front cost, and are netting out more use cases for machine learning and recommendation from it.
Unified ML workflow across product
With such a variety of use cases of recommendation models, we have to be deliberate about how we organize and think about the various components. At a high level, recommenders are categorized according to “corpus”, and then “source”. A corpus is a type of entity — e.g. a Slack channel or user — and a source represents a particular part of the Slack product. A corpus can correspond to one or more sources — e.g. Slackbot channel suggestions and Channel browser recommendation each correspond to a distinct source, but the same corpus channel.
Irrespective of corpus and use case though, the treatment of each recommendation request is pretty similar. At a high level:
- Our main backend serves the request, taking in a query, corpus, and source and returning a set of recommendations that we also log.
- When those results are interacted with in our client’s frontend, we log those interactions.
- Offline, in our data warehouse (Airflow), we combine those logs into training data to train new models, which are subsequently served to our backend as part of returning recommendations.
Here is what that workflow looks like in total: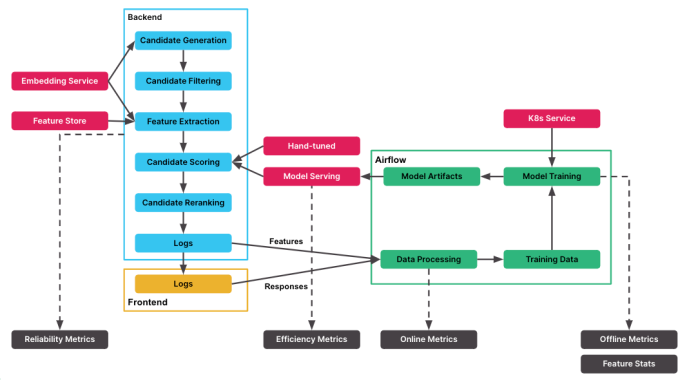
Backend
Each source is associated with a “recommender” where we implement a sequence of steps to generate a list of recommendations, which:
- Fetch relevant candidates from various sources, including our embeddings service where similar entities have close vector representations
- Filter candidates based on relevancy, ownership, or visibility, e.g. private channels
- Augment features such as entities’ attributes and activities using our Feature Store
- Score and sort the candidates with the predictions generated by corresponding ML models
- Rerank candidates based on additional rules
Each of these steps is constructed as a standardized class which is reusable between recommenders, and each of these recommenders is in turn constructed as a sequence of these steps. While use cases might require bespoke new components for those steps, often creating a new recommender from existing components is as simple as writing something like this:
final class RecommenderChannel extends Recommender {
public function __construct() {
parent::__construct(
/* fetchers */ vec[new RecommendChannelFetcher()],
/* filters */ vec[new RecommendChannelFilterPrivate()],
/* model */ new RecommendLinearModel(
RecommendHandTunedModels::CHANNEL,
/** extra features to extract **/
RecommendFeatureExtractor::ALL_CHANNEL_FEATURES,
),
/* reranker */ vec[new RecommendChannelReranker()],
);
}
}
Data processing pipelines
Besides being able to serve recommendations based on these comments, our base recommender also handles essential logging, such as tracking the initial request that was made to the API, the results returned from it, and the features our machine learning model used at scoring time. We then output the results through the Recommend API to the frontend where user responses, such as clicks, are also logged.
With that, we schedule Airflow tasks to join logs from backend (server) providing features, and frontend (client) providing responses to generate the training data for machine learning.
Model training pipelines
Models are then scheduled to be trained in Airflow by running Kubernetes Jobs and served on Kubernetes Clusters. With that we score the candidates and complete the cycle, thereafter starting a new cycle of logging, training, and serving again.
For each source we often experiment with various models, such as Logistic Regression and XGBoost. We set things up to make sure it is straightforward to add and productionize new models. In the following, you can see the six models in total we are experimenting with for people-browser as the source and the amount of Python code needed to train the XGBoost ranking model.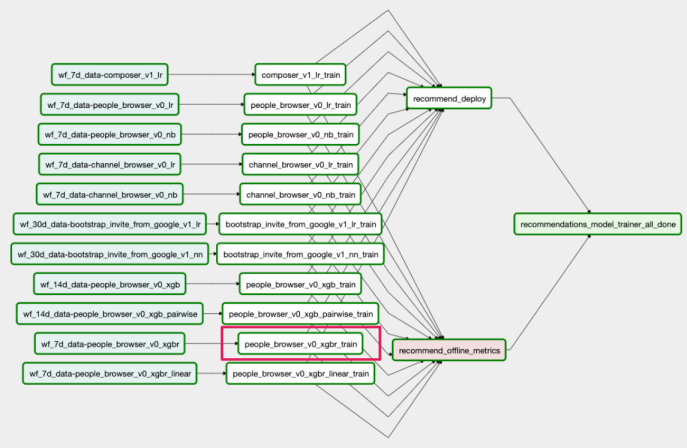
ModelArtifact(
name="people_browser_v0_xgbr",
model=RecommendationRankingModel(
pipeline=create_recommendation_pipeline(
XGBRanker(
**{
"objective": "rank:map",
"n_estimators": 500,
}
)
),
input_config=RecommenderInputConfig(
source="people-browser",
corpus=Corpus.USER,
feature_specification=UserFeatures.get_base_features(),
),
),
)Data Privacy
While training models for our recommenders, one of core concerns is ensuring the privacy and security of Customer Data—the content users put in messages, files, and elsewhere. Per our privacy principles, we don’t use any modeling technique that we think has even the possibility of leaking any aspect of that content outside of its original workspace. To achieve that while still being able to develop useful machine learning models, we carefully engineer our features and training data:
- We de-identify all of our training data. Teams, users, and channels are all represented by numeric IDs rather than names and text.
- The vast majority of our features—and generally the most heavily used by our models—are based on metadata about usage of Slack rather than the actual content you put in Slack. For instance, various counts of interactions on the entity we’re evaluating for recommendation. Even the most common sort of embedding we use is based on this; it is derived from factoring a matrix tracking interaction counts by users in channels. These features are all constructed without any usage of Customer Data whatsoever.
- The similarity in topics being discussed in/by an entity and the user we’re recommending it to does matter, though. To incorporate this into our models in a privacy-conscious fashion, we construct features that capture the semantic similarity between user and entity without including—or even summarizing—the content itself. The most common way we do this is by using an open source embedding model, not trained on our own data, to embed the messages from both the user and entity, aggregate those up to a single embedding for each, and then use the cosine similarity between the two embeddings as a feature in our model. We don’t use the embedding themselves as features, since they are roughly summarizations of content.
The end result of these steps is training data that is scrubbed of customer data and any sort of personally identifiable information. Models trained on this data can do a great job of recommendation, and without ever accessing our customer’s content, there’s no risk the model will memorize it and somehow leak it.
Monitoring
We also output metrics in different components so that we can get an overall picture on how the models are performing. When a new model is productionized, the metrics will be automatically updated to track its performance.
- Reliability metrics: Prometheus metrics from the backend to track the number of requests and errors
- Efficiency metrics: Prometheus metrics from the model serving service, such as throughput and latency, to make sure we are responding fast enough to all the requests
- Online metrics: business metrics which we share with external stakeholders. Some most important metrics we track are the clickthrough rate (CTR), and ranking metrics such as discounted cumulative gain (DCG). Online metrics are frequently checked and monitored to make sure the model, plus the overall end-to-end process, is working properly in production
- Offline metrics: metrics to compare various models during training time and decide which one we potentially want to experiment and productionize. We set aside the validation data, apart from the training data, so that we know the model can perform well on data it hasn’t seen yet. We track common classification and ranking metrics for both training and validation data
- Feature stats: metrics to monitor feature distribution and feature importance, upon which we run anomaly detection to prevent distribution shift
Iteration and experimentation
In order to train a model, we need data, both features and responses. Most often, our work will target active Slack users so we usually have features to work with. However, without the model, we won’t be able to generate recommendations for users to interact in order to get the responses. This is one variant of the cold start problem which is prevalent in building recommendation engines, and it is where our hand-tuned model comes into play.
During the first iteration we’ll generally rely on a hand-tuned model which is based on common knowledge and simple heuristics, e.g. for send-time optimization, we are more likely to send invite reminders when the team or inviter is more active. At the same time, we brainstorm relevant features and begin extracting from the Feature Store and logging them. This will give us the first batch of training data to iteratively improve upon.
We rely on extensive A/B testings to make sure ML models are doing their job to improve the recommendation quality. Whenever we switch from hand-tuned to model based recommendations, or experiment with different sets of features or more complicated models, we run experiments and make sure the change is boosting the key business metrics. We will often be looking at metrics such as CTR, successful teams, or other metrics related to specific parts of Slack.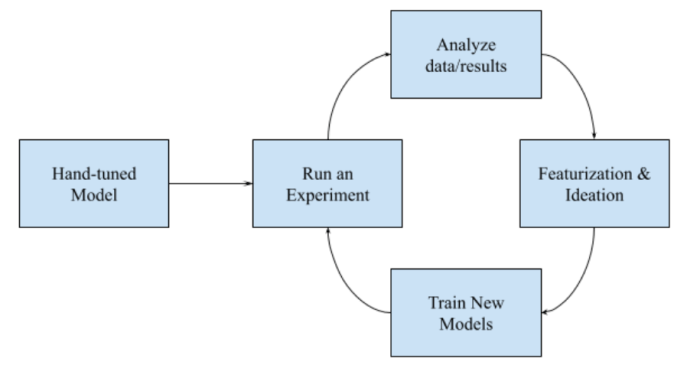
Following is a list of recent wins we’ve made to the aforementioned ML powered features, measured in CTR.
- Composer DMs: +38.86% when migrating from hand-tuned model to logistic regression and more recently +5.70% with XGBoost classification model and additional feature set
- Creator invite flow: +15.31% when migrating from hand-tuned model to logistic regression
- Slackbot channel suggestions: +123.57% for leave and +31.92% for archive suggestions when migrating from hand-tuned model to XGBoost classification model
- Channel browser recommendation: +14.76% when migrating from hand-tuned model to XGBoost classification model. Below we can see the impact of the channel browser experiment over the time:
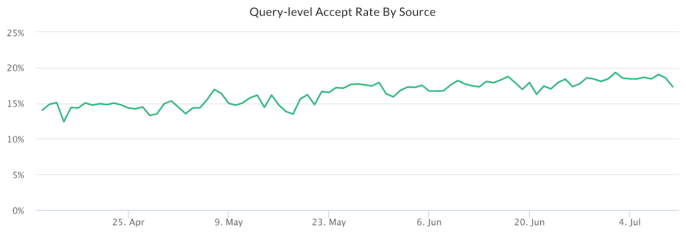
Final thoughts
The Recommend API has been used to serve ML models over the last couple of years, though it took much longer to build the groundwork of various services backing up the infrastructure. The unified approach of Recommend API makes it possible to rapidly prototype and productionize ML models across the product. Meanwhile, we are constantly making improvements to:
- Data logging and preprocessing process, so that can be extended to more use cases
- Model training infrastructure, e.g. scaling, hardware acceleration, and debuggability
- Model explainability and model introspection tooling utilizing SHAP
We are also reaching out to various teams within the Slack organization for more opportunities to collaborate on new parts of the product that could be improved with ML.
Acknowledgments
We wanted to give a shout out to all the people that have contributed to this journey: Fiona Condon, Xander Johnson, Kyle Jablon
Interested in taking on interesting projects, making people’s work lives easier, or just building some pretty cool forms? We’re hiring! 💼
Apply now





