




Slack uses a job queue system for business logic that is too time-consuming to run in the context of a web request. This system is a critical component of our architecture, used for every Slack message post, push notification, URL unfurl, calendar reminder, and billing calculation. On our busiest days, the system processes over 1.4 billion jobs at a peak rate of 33,000 per second. Job execution times range from a few milliseconds to (in some cases) several minutes.
The previous job queue implementation, which dates back to Slack’s earliest days, has seen us through growth measured in orders of magnitude and has been adopted for a wide range of uses across the company. Over time we continued to scale the system when we ran into capacity limits on CPU, memory, and network resources, but the original architecture remained mostly intact.
However, about a year ago, Slack experienced a significant production outage due to the job queue. Resource contention in our database layer led to a slowdown in the execution of jobs, which caused Redis to reach its maximum configured memory limit. At this point, because Redis had no free memory, we could no longer enqueue new jobs, which meant that all the Slack operations that depend on the job queue were failing. What made this even worse is that our system actually required a bit of free Redis memory in order to dequeue a job, so even when the underlying database contention was resolved, the job queue remained locked up and required extensive manual intervention to recover.
This incident led to a re-evaluation of the job queue as a whole. What follows is a story of how we made a significant change in the core system design, with minimal disruption to dependent systems, no “stop the world” changeovers or one-way migrations, and room for future improvements.
Initial Job Queue System Architecture
Around this time last year, the job queue architecture could be sketched out as follows, and will be roughly familiar to people who have created or used a Redis task queue:

Life of a Job
- When enqueuing a job, the web app first creates an identifier based on the job type and arguments.
- The enqueue handler selects one of the configured Redis hosts based on a hash of this identifier and the logical queue for the given job.
- Using data structures stored on the Redis host, the handler performs limited deduplication — if there is a job with an identical ID already in queue, the request is discarded, otherwise the job is added to the queue.
- Pools of worker machines poll the Redis clusters, looking for new work. When a worker finds a job in one of the queues it monitors, it moves the job from the pending queue to a list of in-flight jobs, and spawns an asynchronous task to handle it.
- Once the task completes, the worker removes the job from the list of in-flight jobs. If the job has failed, the worker moves it to a special queue to be retried a configured number of times until it eventually succeeds or moves onto a list of permanently failed jobs which is manually inspected and repaired.
Architectural Problems
The post-mortem of the outage led us to conclude that scaling the current system was untenable, and more fundamental work would be required.
Some of the constraints we identified were:
- Redis had little operational headroom, particularly with respect to memory. If we enqueued faster than we dequeued for a sustained period, we would run out of memory and be unable to dequeue jobs (because dequeuing also requires having enough memory to move the job into a processing list).
- Redis connections formed a complete bipartite graph — every job queue client must connect to (and therefore have correct and current information on) every Redis instance.
- Job workers couldn’t scale independently of Redis — adding a worker resulted in extra polling and load on Redis. This property caused a complex feedback situation where attempting to increase our execution capacity could overwhelm an already overloaded Redis instance, slowing or halting progress.
- Previous decisions on which Redis data structures to use meant that dequeuing a job requires work proportional to the length of the queue. As queues become longer, they became more difficult to empty — another unfortunate feedback loop.
- The semantics and quality-of-service guarantees provided to application and platform engineers were unclear and hard to define; asynchronous processing on the job queue is fundamental to our system architecture, but in practice engineers were reluctant to use it. Changes to existing features such as our limited deduplication were also extremely high-risk, as many jobs rely on them to function correctly.
Each of these problems suggests a variety of solutions, from investing further work in scaling the existing system, to a complete ground-up rewrite. We identified three aspects of the architecture we felt would address the most pressing needs:
- Replacing the Redis in-memory store with durable storage (such as Kafka), to provide a buffer against memory exhaustion and job loss.
- Developing a new scheduler for jobs, to improve quality-of-service guarantees and provide desirable features like rate-limiting and prioritization.
- Decoupling job execution from Redis, allowing us to scale up job execution as required, rather than engaging in a difficult and operationally costly balancing act.
Incremental Change or Full Rewrite?
We knew that implementing all these potential architectural enhancements would require significant changes in the web app and the job queue workers. The team wanted to focus on the most critical problems and gain production experience with any new system components rather than attempt to do everything at once. A series of incremental changes felt like the most efficient way to make progress towards productionizing the revised system.
The first problem we decided to address is that we couldn’t guarantee write availability during queue buildup. If the workers dequeue jobs at a rate slower than the enqueue rate, the Redis cluster itself would eventually run out of memory. At Slack’s scale, this could happen very quickly. At this point the Redis cluster would be unavailable to accept writes to enqueue any additional jobs.
We thought about replacing Redis with Kafka altogether, but quickly realized that this route would require significant changes to the application logic around scheduling, executing, and de-duping jobs. In the spirit of pursuing a minimum viable change, we decided to add Kafka in front of Redis rather than replacing Redis with Kafka outright. This would alleviate a critical bottleneck in our system, while leaving the existing application enqueue and dequeue interfaces in place.
Here is a sketch of the incremental change to the job queue architecture with Kafka and its supporting components in front of Redis.
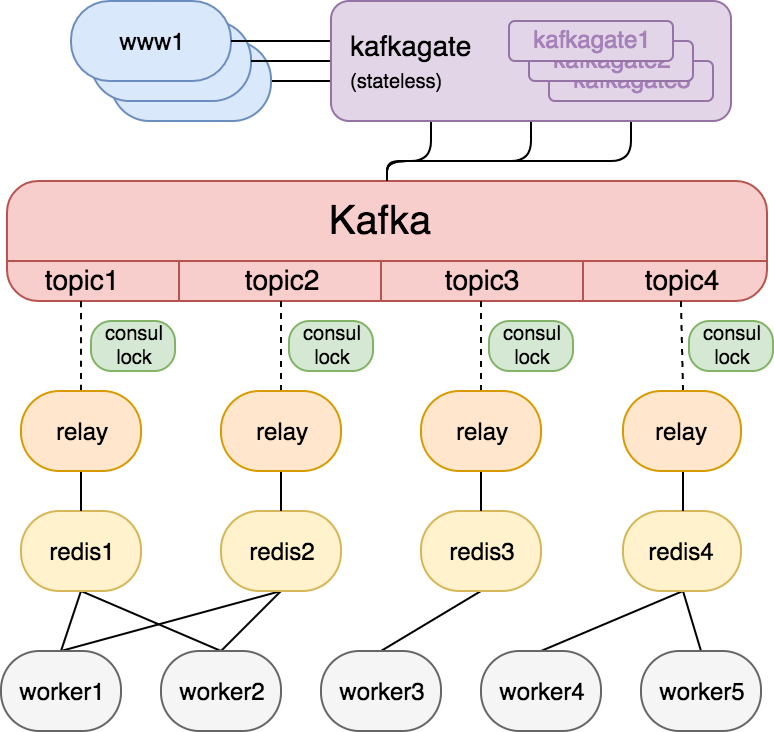
Enqueuing Jobs to Kafka
The first challenge we faced was how to efficiently get a job from our PHP/Hacklang web app into Kafka. Although we explored existing solutions for this purpose, none were well-suited for our needs, so we developed Kafkagate, a new stateless service written in Go, to enqueue jobs to Kafka.
Kafkagate exposes a simple HTTP POST interface whereby each request contains a Kafka topic, partition, and content. Using the Sarama golang driver for Kafka, it simply relays the incoming HTTP request into Kafka and returns the success/failure of the operation. With this design, Kafkagate maintains persistent connections to the various brokers and can follow the leadership changes, while offering a low latency simple interface to our PHP/Hack web application.
Kafkagate is designed for:
- A bias towards availability over consistency: While writing jobs to Kafka, we only wait for the leader to acknowledge the request, and not for replication of the job to additional brokers. This choice provides the lowest latency possible, but does create a small risk of lost jobs in the event that a broker host dies unexpectedly before replicating. This is the right tradeoff for most of Slack’s application semantics, though we are also considering adding an option to Kafkagate to allow critical job applications to wait for stronger consistency guarantees for certain operations.
- Simple client semantics: Kafkagate uses a synchronous write to Kafka, which allows us to positively acknowledge jobs that make it to the queue (notwithstanding the risk of lost writes described above), and return errors in the case of failures or timeouts. This tightens up the existing semantics without dramatic change, allowing engineers to use it with confidence while still giving us the ability to modify the job queue design in the future.
- Minimum latency: In order to reduce the amount of time spent to enqueue a job, we made a number of optimizations to the performance. One example relates to how we deploy and route to Kafkagates: Slack is deployed on AWS, which provides several “availability zones” (AZs) in each independent region. AZs within a region have low-latency links and provide a degree of isolation where most failures will not impact other AZs. Connections between AZs are typically higher latency than connections that stay within a single AZ, and also incur transfer costs. The job queue now preferentially routes a request to Kafkagate instances in the same AZ as the host enqueueing a job, while still allowing failover to other AZs, which improves the latency and costs while still allowing for fault tolerance.
In the future, we are considering a further optimization of having a Kafkagate service running locally on the web app host to avoid an extra network hop when writing to Kafka.
Relaying Jobs from Kafka to Redis
The next new component in the architecture addresses the need to relay jobs out of Kafka and into Redis for execution. JQRelay is a stateless service written in Go that relays jobs from a Kafka topic to its corresponding Redis cluster. While designing this service, we had to think about the following:
Data Encoding
In the earlier system, the web app (written in PHP and Hack) would JSON encode a representation of the job when storing it in Redis. Subsequently, the job queue worker (also written in PHP) would decode the job payload for execution. In the new system, we relied on JQRelay (written in Go) to decode the JSON encoded job, examine it, and then re-encode in JSON and write it to the appropriate Redis cluster. Sounds simple enough, right?
It turns out that both the golang and the PHP JSON encoders have some unexpected quirks related to escaping characters that caused us some heartache. Specifically, in Go, <, >, and & characters are replaced with equivalent unicode entities by default, and in PHP, / characters are “escaped” with a by default. Both of these behaviors resulted in issues where the JSON representation of a data structure would differ between the two runtimes, a situation that didn’t exist in the original PHP-only system.
Self-configuration
When a JQRelay instance starts up, it attempts to acquire a Consul lock on an key/value entry corresponding to the Kafka topic. If it gets the lock, it starts relaying jobs from all partitions of this topic. If it loses its lock, it releases all resources and restarts so that a different instance can pick up this topic. We run JQRelay in an EC2 auto-scaling group, so that any failed machines are automatically replaced into service and go through this lock flow. When combined with this Consul lock strategy, we ensure that all Kafka topics used by the job queue have exactly one relay process assigned to them, and failures automatically heal themselves.
Handling failures
JQRelay relies on Kafka commit offsets to track jobs in each topic partition. A partition consumer only advances the offset if the job is successfully written to Redis. In the event of a Redis issue, it retries indefinitely until Redis comes back (or the Redis service itself is replaced). Job specific errors are handled by re-enqueuing the job to Kafka instead of silently dropping the job. This way we prevent a job-specific error from blocking all progress on a given queue, but we keep the job around so that we can diagnose and fix the error without losing the job altogether.
Rate limiting
JQRelay respects the rate limits configured in Consul when writing to Redis. It relies on the Consul watch API to react to rate limit changes.
Kafka Cluster Setup
Our cluster runs the 0.10.1.2 version of Kafka, has 16 brokers and runs on i3.2xlarge EC2 machines. Every topic has 32 partitions, with a replication factor of 3, and a retention period of 2 days. We use rack-aware replication (in which a “rack” corresponds to an AWS availability zone) for fault tolerance and have unclean leader election enabled.
Load testing
We set up a load test environment to stress our Kafka cluster before rolling it out to production. As part of load testing, we enqueued jobs to various Kafka topics at their expected production rate. This load testing allowed us to properly size our production Kafka cluster to have sufficient headroom to handle individual brokers going down, cluster leadership changes and other administrative actions, and to give us headroom for future growth of the Slack service.
Failure testing
It was important to understand how different Kafka cluster failure scenarios would manifest in the application, e.g. connect failures, job enqueue failures, missing jobs, and duplicate jobs. For this, we tested our cluster against following failure scenarios:
- Hard kill and gracefully kill a broker
- Hard kill and gracefully kill two brokers in a single AZ
- Hard kill all three brokers to force Kafka to pick an unclean leader
- Restart the cluster
In all these scenarios, the system functioned as we expected and we hit our availability goals.
Data migrations
We used our load test setup to identify an optimal throttle rate for safe data migration across brokers. In addition, we experimented with using a lower retention period during migration (since we don’t need to retain a job after it has successfully executed).
With 1.4 billion jobs flowing every day, we would prefer to selectively migrate partitions, instead of topics, across brokers. This is planned as part of future work.
Production Rollout
Rolling out the new system included the following steps:
- Double writes: We started by double writing jobs to both the current and new system (each job was enqueued to both Redis and Kakfa). JQRelay, however, operated in a “shadow” mode where it dropped all jobs after reading it from Kafka. This setup let us safely test the new enqueue path from web app to JQRelay with real production traffic.
- Guaranteeing system correctness: To ensure the correctness of the new system, we tracked and compared the number of jobs passing through each part of the system: from the web app to Kafkagate, Kafkagate to Kafka, and finally Kafka to Redis.
- Heartbeat canaries: To ensure that the new system worked end-to-end for 50 Redis clusters and 1600 Kafka partitions (50 topics × 32 partitions), we enqueued heartbeat canaries for every Kafka partition every minute. We then monitored and alerted on the end-to-end flow and timing for these heartbeat canaries.
- Final roll-out: Once we were sure of our system correctness, we enabled it internally for Slack for a few weeks. After that showed no problems, we rolled it out one by one for various job types for our customers.
Conclusion
Adding Kafka to the job queue was a great success in terms of protecting our infrastructure from exhaustion of Redis memory. Let’s walk through the scenario where we have a queue build up again: In the old system, if the web app sustained a higher enqueue rate than the job queue dequeue rate, the Redis cluster itself would eventually run out of memory and cause an outage. In the new system, the web app can sustain its high enqueue rate as the jobs are written to durable storage (Kafka). We instead adjust the rate limits in JQRelay to match the dequeue rate or pause enqueues to Redis altogether.
In the broader picture, this work has also improved the operability of the job queue, with configurable rate limits and durable storage for when job enqueues outstrip our execution capacity — finer-grained tools than we had at our disposal before. Clearer client semantics will help our application and platform teams make more confident use of the job queue. And the infrastructure team has a foundation for continued improvements to the job queue, ranging from tying JQRelay’s rate limiting to Redis memory capacity to the larger goals of improving the scheduling and execution aspects of the system.
Even with new systems like this in place, we are always looking for ways to make Slack more reliable. If you’re interested in helping, get in touch.





