

We’ve been working to bring components of Quip’s technology into Slack with the canvas feature, while also maintaining the stand-alone Quip product. Quip’s backend, which powers both Quip and canvas, is written in Python. This is the story of a tricky bug we encountered last July and the lessons we learned along the way about being careful with TCP state. We hope that showing you how we tackled our bug helps you avoid — or find — similar bugs in the future!
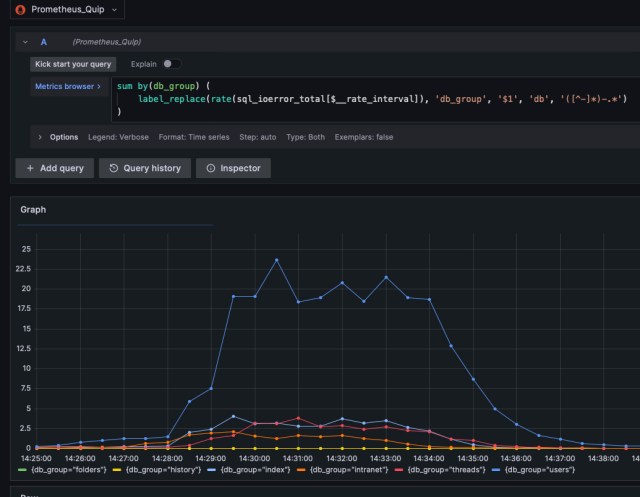
Our adventure began with a spike in EOFError errors during SQL queries. The errors were distributed across multiple services and multiple database hosts:
Investigation
The stacktrace showed an asyncio.IncompleteReadError, which we translate to EOFError, when reading the response from the database:
File "core/mysql.py", line 299, in __read_result_set
header = await self.__read_packet(timeout=timeout)
File "core/mysql.py", line 532, in __read_packet
header = await self.conn.read_exactly(4, timeout=timeout)
File "core/runtime_asyncio.py", line 1125, in read_exactly
raise EOFError() from NoneHere’s the relevant code, which had not been touched recently, along with some associated baffled commentary:
async def _perform_query_locked(...) -> core.sql.Result:
...
if not self.conn.is_connected():
await self.__connect(...)
await self.__send_command(...)
result_set = await self.__read_result_set(...) # <-- EOFError
There are a few places where we close our connection to the database, e.g. if we see one of a certain set of errors. One initial hypothesis was that another Python coroutine closed the connection for its own reasons, after we issued the query but before we read the response. We quickly discarded that theory since connection access is protected with an in-memory lock, which is acquired at a higher level in the code. Since that would be impossible, we reasoned that the other side of the connection must have closed on us.
This theory was bolstered when we found that our database proxies closed a bunch of connections at the time of the event. The closes were distributed independent of database host, which was consistent with the incident’s surface area. The proxy-close metric, ClientConnectionsClosed, represents closes initiated by either side, but we have a separate metric for when we initiate the close, and there was no increase in activity from us at the time. The timing here was extremely suspicious, although it still didn’t quite make sense why this should result in such a high rate of errors on the response read since we had just ensured connection state.
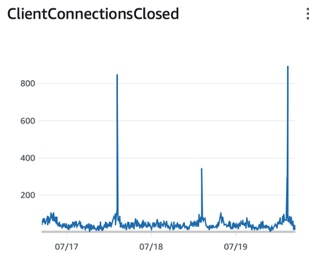
Something clearly wasn’t adding up, so it was time to dig deeper. Suspecting the if not self.conn.is_connected(): line, we looked at our implementation for AsyncioConnection:
class AsyncioConnection(core.runtime.Connection[memoryview]):
def closed(self) -> bool:
return not self.writer or self.writer.is_closing()
def is_connected(self) -> bool:
return self.connectedBoth of these functions turned out to be incorrect. First, let’s look at closed(). Each Asyncio connection has a StreamReader and a StreamWriter. Our code suggested that the closed state is only a function of the writer, which is controlled by the application server, not the reader. This seemed suspiciously incomplete to us since we expected only the reader to be aware of whether the other side closed the connection. We proved this with a unit test:
async def test_reader_at_eof_vs_writer_is_closing(self):
conn = await self.create_connection()
# Ask the unit test's server to close
await conn.write(self.encode_command("/quit"))
# Don't read. Still open since we haven't seen the
# response yet
self.assertFalse(conn.writer.is_closing())
# Read, then sleep(0) since it requires another run
# through the scheduler loop so the stream can detect
# the zero read/eof
response = await conn.read_until(self.io_suffix)
await core.runtime.sleep(0)
self.assertTrue(conn.reader.at_eof()) # passes
self.assertTrue(conn.writer.is_closing()) # failsNext, let’s look at is_connected(). First, it’s not a function of closed(), so the two have the potential to drift. Second, it could return a false positive: the only place where we set the instance variable self.connected to false is when the application server closes the connection, so similar to closed() it’s unaware of the reader being in the EOF state.
We decided to log a metric so we could compare self.connected to not self.closed() to see exactly how much they drift. We found six more bugs, which led to one coworker coining the delightful phrase “when you go picking up rocks, you might find things under those rocks,” which we immediately adopted:
is_connected()could also be a false negative. We saw that the false negatives only occurred on the services that maintain websocket connections to clients. The only place we setself.connectedto true is when the application server initiates the connection, so it’s never set to true when it’s initiated by the client.- There is a check we perform upon connection lock release to see if there is any data on the connection we haven’t read. It was incorrect to perform this check in some circumstances on websocket connections since it’s expected that the client can send data at any point in time.
- Our HTTP client pool could contain closed clients.
- We didn’t correctly handle exceptions during reconnect.
- We found another place where we should be removing connections from the pool.
- The Redis-specific cleanup we thought we would always do upon connection close wasn’t happening when the close wasn’t initiated by the application server.
Resolution
At this point we had all the pieces of the puzzle and were able to understand the sequence of events:
- The proxy closed database connections on us. After communicating with AWS we learned that they introduced behavior where the proxy closes connections after 24h even if it isn’t idle, so the closes were tied to our daily release, which restarts all of our servers.
- We failed to recognize the connections were closed since the close was not initiated by us, and as a result we did not reconnect prior to issuing SQL queries.
- We’d issue a query, then attempt to read the response, but the reader would be in the EOF state from the close, so it would raise
EOFError.
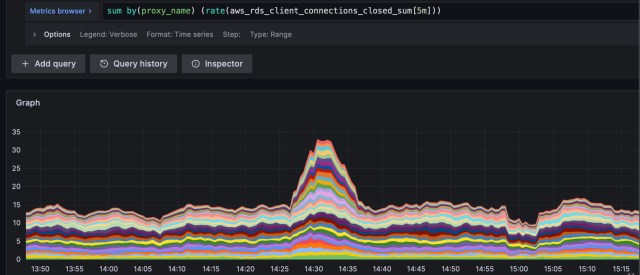
We deployed the fix and saw the near-total reduction in EOFError during SQL queries:

As we deployed the fix for the case where connections are initiated by the client, the false negatives disappeared entirely, too:

 The Asyncio Migration
The Asyncio Migration
The primary impact of this bug fix, however, wasn’t even the improved handling of connection closes. The primary impact was the unblocking of the Python runtime migration.
The migration project began in 2020 and was from our custom runtime — we were early adopters of Python 3 — to asyncio, the standard Python IO library introduced in 3.4. The project ran smoothly and was enabled in all environments with just one exception: one service on our largest single-tenant cluster, since the customer would sporadically experience timeouts when exporting spreadsheets to PDF. The issue only occurred at times of peak load and was difficult to reproduce, so the project stalled.
This PDF export handler makes an RPC request to another service that handles the PDF generation itself. That request goes over an existing connection from a connection pool, if one exists. If the RPC service is overloaded, it may close that connection, and if so we would fail to recognize that. The handler would fire off the RPC request, but the other side wouldn’t be listening, so that request would hang on write and eventually time out since the buffer would never get drained by the RPC service. For small exports we expect it would have raised an EOFError immediately instead of hanging since it wouldn’t completely fill the buffer.
After launching the connection state fixes, we re-enabled asyncio on the final service, and confirmed that the errors didn’t recur. The asyncio project resumed, entered a very satisfying phase of deleting code in our custom runtime scheduler, and concluded shortly after.
Conclusion
This is tricky to get right! As we see from https://man7.org/linux/man-pages/man3/shutdown.3p.html a socket can be in a half-shutdown state. We had expected from the documentation that StreamWriter.is_closing() would encompass that half-shutdown state, but we should have been more careful:
Return True if the stream is closed or in the process of being closed.
In fact, both the default event loop and uvloop contain the same behavior as we did, where the closing state is only set upon client-initiated close. This explains why the unit test mentioned before failed both with uvloop enabled and disabled and why it was insufficient to depend only on StreamWriter.is_closing().
When the other side of a TCP connection sends FIN, we enter the CLOSE WAIT state. But in that state we can still attempt to read for as long as we like. We’ll only exit that state when we tell the OS to close or shut down the socket.

Above all, my personal takeaway is to always pick up rocks[1]. In this case it could have been tempting to simply call it a day after adding EOFError to the list of exceptions upon which we reissue the query to a failover database. But with low-level code, it’s usually worth the extra time and effort to dig a bit deeper if something just doesn’t quite seem right. Even if things are mostly fine on the surface, bugs down there can have far-reaching effects.
Special thanks to Ross Cohen for his hard work and camaraderie through this rollercoaster of a bug. Couldn’t ask for a better buddy on this one!
If you enjoyed this post, you might also like working here. Check out our careers page!
[1] You might find things under those rocks!





