

A fact of life for building an internet service is that, sooner or later, bad actors are going to come along and try to abuse the system. Slack is no exception — spammers try to use our invite function as a way to send out spam emails. Having built up the infrastructure to easily deploy machine learning models in production, we could develop a model relatively quickly that could accurately predict which invites were spam and block them from ever being sent out. There’s nothing ground-breaking here; instead, this post aims to describe the sorts of problems that can be best solved with machine learning, along with some tips and tricks on how to do so.
Background
What is invite spam?
When you create a team in Slack, the first thing you do is invite the people you’ll be working with: your co-workers, friends, classmates, or teammates. You enter their email addresses, and Slack sends out the invites on your behalf. These invites usually have a high acceptance rate. However, in a small minority of cases, we see teams where no invites are accepted, or those few users who join, quickly leave. These are typically teams where spammers are trying to use the reputable Slack email domain to reach their targets. The result might look like this:
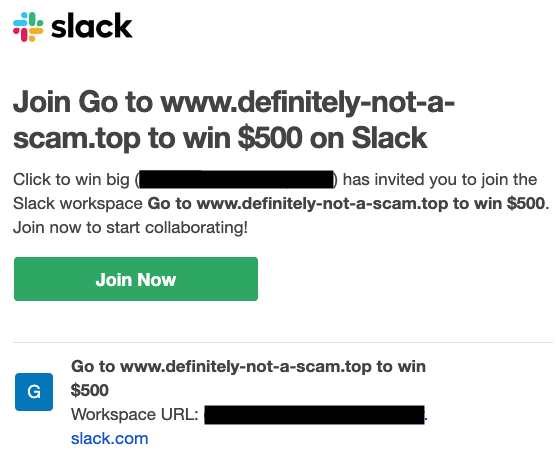
Here, the team was named “Go to www.definitely-not-a-scam.top to win $500!” The goal was never to get someone to join the team, just to have that text sent out in an email. This sort of phishing is dangerous for our customers and detrimental to our brand, so it’s imperative that we prevent it.
Early solutions
Slack’s first solution to spam was to block or rate-limit invites from teams based on hand-tuned rules. Some of these included checking IP addresses against a deny list, checking for certain strings in the text of the invite, and checking for a set of regex matches. We had a Slack channel that would include notifications both when we blocked a team and when, after the fact, it looked like we should have blocked a team. Based on what they saw from this, engineers would update the rules to hopefully catch similar patterns in the future. This system mostly worked, but at a cost:
- It was labor intensive. We needed people watching the channel to identify patterns and update rules. Over time, the spammers got more sophisticated, and we needed a steady stream of human effort to keep up.
- Focusing primarily on spam we missed, we had a lot of false positives. For instance:
- We blocked everything with the string “линк”, which means “link” in Russian because it was common in spam. However, it also popped up in the middle of some Russian last names, who we would accidentally block as well.
- We rate-limited invites from any recently created team which had non-ASCII characters. Though this caught a lot of spam, it also caught a lot of innocuous traffic.
Bringing in ML
Data
The situation above, where a series of rules were being updated based on a stream of historical data, is exactly the sort of thing machine learning can do a lot better and cheaper than humans. We call this sort of problem a “supervised” machine learning problem, where we have a label (an invite being spam) that we want a machine to predict. However, to teach a machine to do it, you need data. In particular, for each of our observations (invites) we need historical records of:
- Labels – a ground truth for thing we want to predict going forward
- Features – some set of facts about the observation which is sufficient to have predicted the label
The hand-tuned model was already based on a great feature set, which was straightforward to recalculate for old invites, so that part was handled. The labels were less straightforward; we hadn’t systematically recorded the teams we thought were spammy. For something like spam, where a human will know it when they see it, crowdsourcing labels are always possible. However, this is hard to do at scale. Instead, as a more readily available proxy, we tried to predict whether an invite would be accepted or not. We already had these labels for every invite. Though invites are regularly ignored or rejected for normal teams, on a team level the rate can readily distinguish between spam and not spam; it’s extremely rare for normal teams to have a low acceptance rate. This was a low-risk approach; if we started blocking invites that weren’t spam but people weren’t going to accept anyway, there’s little harm.
There are two other data tricks that are worth mentioning:
- It’s always better to log the features at the time your model was scored. Trying to recalculate these features later can cause a lot of costly mistakes, such as accidentally including the very outcome you are trying to predict as a feature.
- Users sometimes take days or weeks to respond to invites. However, to respond quickly to spammers’ behavior and treat new and old invites identically, we only treated an invite as accepted if it was accepted in 4 days. 90%+ of invites are accepted within this timeline.
Model design
We trained a sparse logistic regression on our data, a classic go-to for any ML engineer. It considers approximately 60 million features, or facts, about each invite, winnowing out many that aren’t useful for predicting invite acceptance using regularization, and then comes up with a score for the presence of each feature. The total score for an invite is just the sum of all the scores for all the features for that invite. Passing this score through the logit function gives us a predicted probability of the invite being accepted. While simpler than most other models, this offers a few advantages:
- It can easily handle a large number of features.
- It is easy to debug — for every invite the model thinks is spam, we can easily say why it thought so. We generate reports like this for every blocked team:
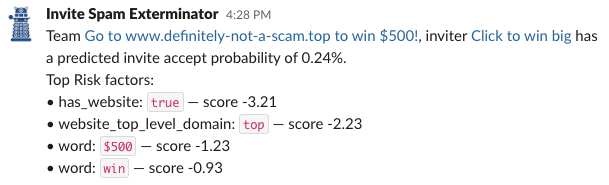
We found that using several large sets of features gave our model a lot of predictive power, including:
- Known team/user IDs, email addresses, email domains, IP addresses
- Various word stems for western languages
- For Chinese, sequences of characters of various lengths
- Websites
- Team age
Model Serving
Often, the biggest hurdle going from a model that can predict something accurately on data “offline” to having an impact in the product is figuring out how to run and score that model “online”. This is particularly a hurdle for data scientists, who often have the tools for the former but not the latter. Thankfully, here at Slack we built an in-house service for serving model predictions, which abstracts most of the difficult part of that process away. To deploy a machine learning model, one only needs to implement a lightweight Python class with a generic prediction method. The service then takes the class and deploys it as a microservice through Kubernetes, which can be queried from the rest of our tech stack. For our spam model, this has allowed us to quickly take the model trained offline and start scoring it on our production traffic. For regularly scheduled updates, the service just checks a static folder in S3 for new versions of the model.
The Impact
Overall, the machine-learned model outperformed the old hand-tuned filter. While neither let through much spam, the machine learning model was much better at preventing false positives. Only 3% of the invites it would have flagged ended up being accepted when allowed through, while around 70% of the invites flagged by the old model actually ended up being accepted, indicating that most of them were pretty normal rather than spammy. Most importantly though, automating the entire process freed up hours of human time each week. The channels where we coordinated updating the hand-tuned model went from often seeing hundreds of messages a month to being basically dormant. While we still log all blocked invites to a channel and double check it periodically, human interaction is rarely required. This is what you hope to see from machine learning; let machines do what they are best at, and free up humans for the work only they can do.
Interested in taking on interesting projects, making people’s work lives easier, or just getting on the machines’ good side before the technological singularity? We’re hiring!





