

About a year ago, I wrote a blog post called Building the Next Evolution of Cloud Networks at Slack. In it, we discussed how Slack’s AWS infrastructure has evolved over the years and the pain points that drove us to spin up a brand-new network architecture redesign project called Whitecastle. If you have not had an opportunity to read the initial article, I highly recommend you do that before tackling this one.
In this article we’ll discuss:
- What have we learned?
- What have we improved?
- What’s next?
But first, let’s do a very quick recap.
Quick recap

As part of the project Whitecastle,
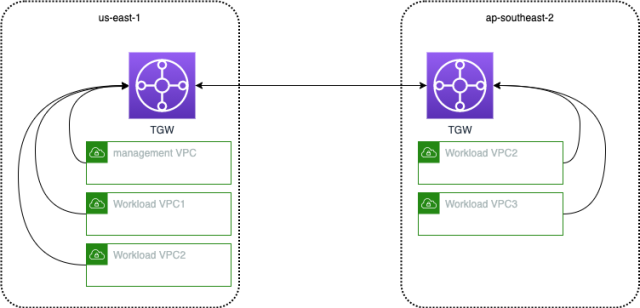
- We built new VPCs across our global AWS regions and connected them all together using the AWS Transit Gateway.
- We also built a management VPC that has connectivity to all other VPCs, so that we can use it to host our management services, such as our Chef configuration management server.
- We also connected our old legacy infrastructure to this new infrastructure so that the teams did not have to do a single big-bang migration, and could instead do it gradually.
This has all been depicted in the diagram below.
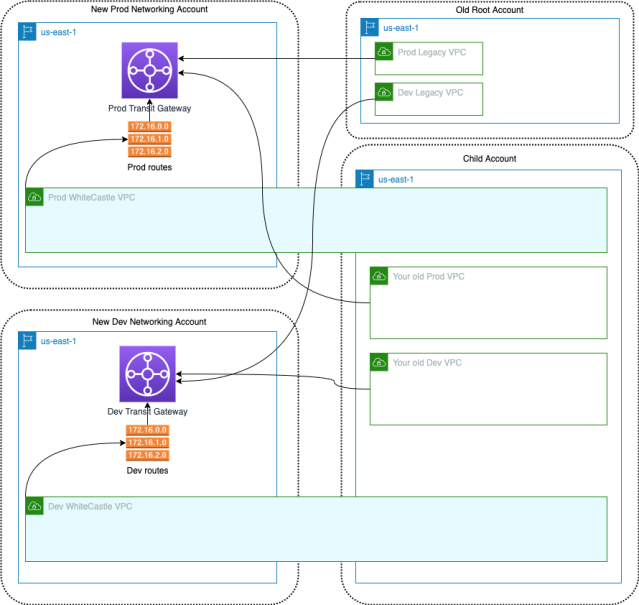
It‘s almost been a year since we released this new network design to the wider teams at Slack. The vast majority of our teams have been moving their services into the Whitecastle network. During this process, we have learned a lot about the areas we can improve on.
What have we learned?
Proxy environment variables are not your friend

In our Whitecastle VPCs, we have 2 subnets. A set of public subnets which have a route of `0.0.0.0/0` pointing at an AWS Internet gateway. On these subnets, we have built Squid proxy stacks with auto scaling enabled behind network load balancers. We chose to build our own instance-based NAT solution in order to meet our internal logging-related compliance requirements.
The second is a set of private subnets with no such route. Any services that live on these private subnets that need internet access must route their traffic through a Squid Proxy Stack in the public subnets. Teams can use the pre-existing default Squid stack or if they generate a large network load, they can request their own dedicated stack.
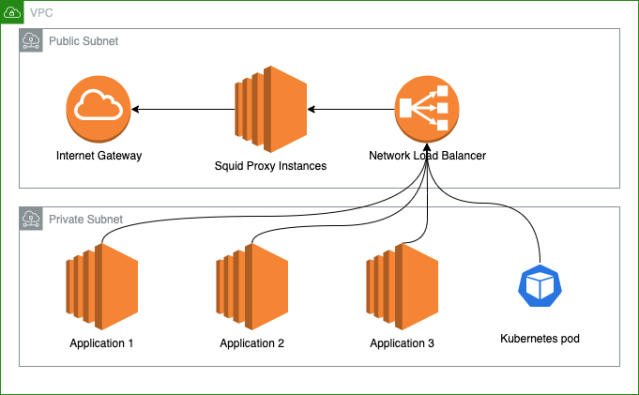
In the past, we had public IPs on most of our instances, so we’ve always had the luxury of being able to connect to the Internet. However, any services that moved to Whitecasle must be configured to use the proxies. To make this internet connectivity through our proxies easier for our teams, on all our Whitecastle instances we export `http_proxy` and `https_proxy` environment variables, as well as the `no_proxy` environment variable. We include a set of internal endpoints and AWS VPC endpoints in the `no_proxy` environment variable. The reason we include AWS VPC endpoints in `no_proxy` is so that we don’t leave the Amazon network for AWS API requests (as going out through the proxy to the public internet incurs additional unnecessary latency and charges).
For example:
no_proxy=127.0.0.1,$internal_addresses,s3.ap-southeast-2.amazonaws.com,ec2.ap-southeast-2.amazonaws.com,$other_aws_vpc_endpoints
http_proxy=http://whitecastle-proxy-server-01:3000
https_proxy=http://whitecastle-proxy-server-01:3000
HTTP_PROXY=http://whitecastle-proxy-server-01:3000
HTTPS_PROXY=http://whitecastle-proxy-server-01:3000The good news is some applications, such as ones written in Golang, honours these variables and uses them with no changes to the application at all. Other applications, such as ones written in Java, are not so friendly, and because of this, service teams must configure them using the environment variables we set that contain the targets which the proxy should skip or not skip. To make matters worse, applications interpret these variables differently too. For example, Ruby and Golang support CIDR blocks in the `no_proxy` variable while Python does not. This is a really good article about proxy environment variables for further reading.
Our service teams now have to worry about configuring `proxy` and `no_proxy` lists as well as ensuring their applications honour these values. This has slowed down the migration to the Whitecastle network because of this additional complexity, and we’re still looking for a better solution.
Watching the Transit Gateway?

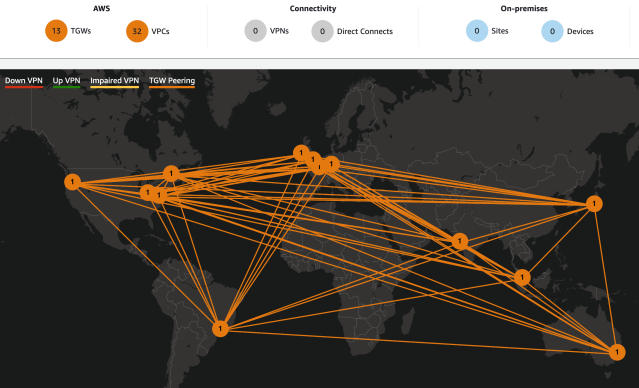
As workloads gradually migrate to Whitecasle, we’re in a state where some of our services are in the legacy VPCs and others are in the new Whitecastle VPCs. This is temporary, but during this state, we put massive amounts of network traffic through the Transit Gateway with unpredictable spikes and bursty patterns.
As our services and infrastructure relies heavily on Transit Gateways to process our edge-case traffic patterns, visibility on the Transit Gateway is critically important for our day-to-day cloud operations. We extensively use Transit Gateway’s Cloudwatch metrics – namely PacketsIn, PacketsOut, PacketDropCountBlackhole and PacketDropCountNoRoute – for monitoring traffic patterns at attachment-level granularity. We use these metrics in combination with automated scripts for correlation and validation of traffic traversing across multiple VPCs via the Transit Gateway. As we move further along, we look forward to the advanced visibility on the Transit Gateway featured on the AWS future roadmap.
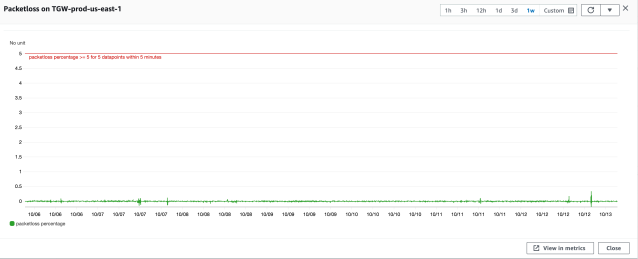
Is Transit Gateway scaling infinite?

As we significantly ramped up our usage volume on the Transit Gateways, we had to heavily rely on Transit Gateway’s auto-scaling capabilities for handling unpredictable traffic bursts. Also, the fact that some applications migrated parts of the stack to the new VPC, leaving other parts in the old VPC, meant a lot of traffic that previously was meant to be local to the VPC now traversed through the TGW. At our scale, this posed a big challenge in terms of sheer volume of network traffic to be routed between multiple VPCs in our AWS network. To overcome this challenge, we worked closely with the AWS Transit Gateway team and our AWS technical account managers to scale up some of our Transit Gateway deployments to adequately meet our hyperscale capacity needs.
Migrating from peering to Transit Gateways

As Transit Gateways become our central hub to connect VPCs together, we looked to replace our existing peering connections between the legacy VPCs with the AWS Transit Gateway. This simplified our network architecture as well as the Terraform code we use to manage it.
A critical requirement was to have the ability to cutover without losing the connectivity between two VPCs. So how did we do this?
- First we attached the region’s Transit Gateway to both VPCs. This attachment didn’t change any network routing as no changes were made to the VPCs route table.
- The second step was to add a default route of `10.0.0.0/8` pointing at the Transit Gateway attachment. This didn’t make any changes to the network path either as it prefers a specific VPC to a generic one.
- Then we deleted the route from both VPCs that were pointing at the peering connection. This caused the VPCs to start using the Transit Gateway path.
- Once everything worked well, we simply deleted the peering connection.
Tracking our migration status

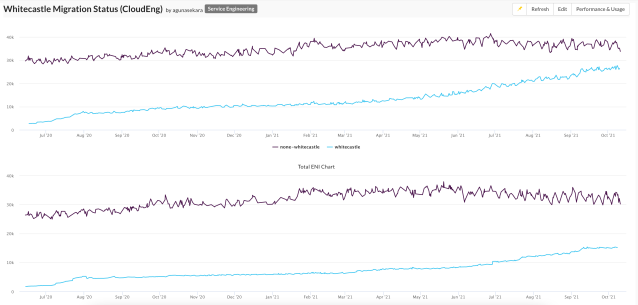
An important metric for the new Whitecastle network is the migration status of our current services. This metric is helpful for reporting purposes as well as the company’s upper management to visualise where we’re at with the migration.
We’ve come up with a simple metric to achieve this: number of IP addresses and elastic network interfaces in each VPC. Once a day, we go through each of our AWS accounts and count the number of IP addresses and elastic network interfaces in the legacy VPCs and the new Whitecastle VPCs. This gives us a basic view of where services are located and how the migration is progressing.
What have we improved?
Multiple workload VPCs, because one isn’t enough

Our original Whitecastle network design architecture consists of one workload VPC per region. This VPC was shared using AWS Resource Access manager to an AWS Organizational Unit using the power of AWS VPC Sharing. The advantage of this approach is that we took away the network and connectivity management overhead from the service teams and let them do what they do best, focus on building awesome services. Slack’s Cloud Engineering team then manages all the VPCs, routing across multiple VPCs, and any attached private Route53 zones.
However some of our customers with their services on legacy VPCs do have some special configurations, such as custom DHCP option sets attached to their VPCs. To cater for these special needs, we have added workload specific VPCs to some regions and attached them to the region’s local Transit Gateway. Since we use Terraform modules to create VPCs, building new VPCs is quite straightforward. Since the AWS Transit Gateway takes care of the routing, adding extra VPCs to a given region is relatively easy as long as the CIDRs of the new VPCs do not overlap with anything existing. Furthermore Transit Gateways support inter-region peering which greatly simplifies VPC connectivity and routing of traffic across multiple AWS regions.
Private Route53 zones management

In the past, we had one big account containing all our private and public Route53 zones. With the new Whitecastle approach, we’ve split them up into three completely separate environments for Sandbox, Dev, and Prod networks. Because of this, we chose to move the common private Route53 zones into the environment network account, allowing us to restrict access to these zones to the services who need it.
However, some internal teams have the need to manage their own DNS records, and for these use cases, we use the AWS’s Route53 private zones’ authorize the association feature. This allows the association between the private hosted zone in Account A and the VPC in Account B.

We can create private zones in service teams’ AWS accounts and authorize the association of these zones to the Whitecatle VPCs in the managed network account. With this approach, each service team can fully manage their private zones and the records inside them. The Whitecastle network management team can manage zone associations with the managed VPCs. This prevents random private zones from being attached to the managed VPCs and any private zone association can be accessed and approved while giving the service team full power to manage their own zones.
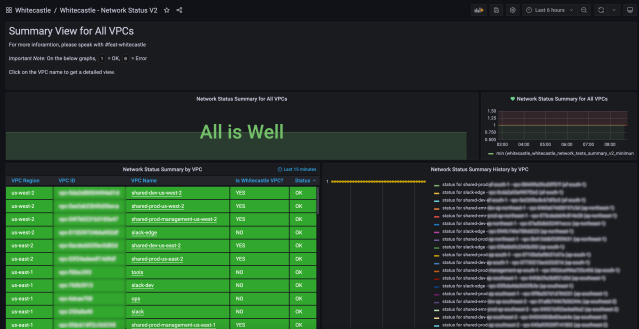
Network Tester improvements

We built a tool called Whitecastle Network Tester to validate the routes between each VPC. It does two things:
- First, the Whitecastle Network Tester starts a simple web server and responds to HTTP requests on the /health endpoint with a HTTP 200.
- Second, it reads a configuration file to discover what environments it needs to connect to, then it requests the `/health` endpoint.
We expect some of these endpoint calls to succeed and some to fail. This way we can ensure things that need to talk to each other, can talk to each other, but not to anything else. As we have multiple environments and a vast number of VPCs in each, it’s important to ensure our Network mesh is correct. This is an important part of network security as we must have a strong separation between our environments (Sandbox, Dev and Prod environments). For example, traffic from an instance in Dev networks should not be able to route traffic to an instance in Prod networks.
As I discussed in my original blog post about Whitecastle, the Network Tester tool has been important for our network path validation. However, as we started to build more and more VPCs, adding each of these VPCs to the network tester configuration was no longer practical. The solution was to use the network environment in the Network Tester configuration instead of each VPC ID. Each network tester registers themselves on a DynamoDB table when they spin up. Network Testers use this discovery table for learning about each other. The current version of the Tester checks what VPC and the environment it’s running in and checks the configuration for other environments that it should be able to communicate with and the ones it shouldn’t. Then it tests each of these network paths. This approach allowed us to have a minimal configuration file as well as not having to update the file every time we built a new VPC, where we only had to do this when we built new environments.
A few years ago, Slack developed and open sourced an overlay network solution called Nebula. The Network tester tool validates direct network paths as well as Nebula network paths. Nebula does not yet support running in Lambda functions, otherwise a Network tester application would be a good candidate for Lambda functions running inside VPCs.
We built a bot

A challenge our Whitecastle network users had was discovering details about the network. For various reasons, they wanted to find out about available VPC IDs, Subnet IDs, Transit Gateway IDs, or CIDR ranges. It’s possible to find these details by logging into the AWS console and looking for a specific resource, however having separate accounts for different environments makes it an annoying process. This information is also buried into our Terraform code, but again, it’s not a very user-friendly way to look up information. So how did we solve this? We built a Slack Bot.
We created a restricted read-only role in each of our networking AWS accounts and gave the bot permission to assume them. Once a user queries a certain bit of information for an environment, the bot looks up the correct AWS account, assumes a role into it, retrieves the information, and posts those details as a message in Slack.
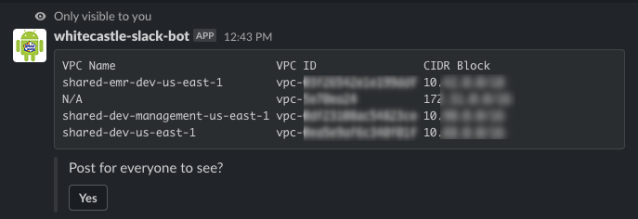
This bot has the ability to display the information privately to the user or post it into a Slack channel for everyone to see. It can be quite helpful during an incident where we need fast access to information about bits of our network.
What’s next?
All in all, this has been a challenging yet exciting journey. We’ve found issues with our new build, and have had incidents, but this has taught us to iterate and improve on our design. We were able to successfully overcome the scaling challenges associated with our unique migration workloads using AWS Transit Gateway thanks to working closely with that service team. In the near future, we’d love to make our Squid proxy tier more user friendly and integrate with the AWS network firewall to ensure mandatory security policies are automatically enforced, and take advantage of activity monitoring through Amazon CloudWatch metrics.
This is all very exciting as we move more services onto the new network build. We’ll have more hurdles to overcome and build more innovative infrastructure, so please keep an eye on our careers page as something interesting might just pop up.





