

With the release of Slack Connect, people can now collaborate both with internal employees and external organizations in the same channel. To make this as smooth as possible, Slack does predictive email analysis to classify and recommend the best way for a user to work with people they want to collaborate with. To accomplish this, we need a way to accurately predict whether an invited email address is an internal employee or an external collaborator.
Email Classification is a system we’ve designed to help make these smart predictions.
Predicting Slack Connect invites
With Slack, people can start collaborating with each other using one of two invite mechanisms:
- Workspace Invites: They become a full member or guest in your workspace
- Slack Connect Invites: They connect through a Slack Connect DM or Shared Channel
When someone begins the invite process they typically enter an email address of the person they’d like to invite. The email classification engine must determine if each given email address is an internal team member or an external organization or user. If they are classified as an external email, we suggest a collaboration through a Slack Connect channel or as a guest part of your workspace.
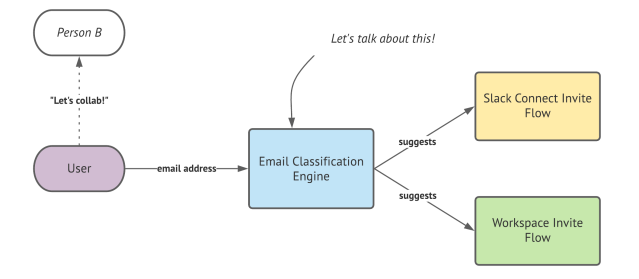
Classification engine
With a provided email address, our classification engine must make a smart prediction to classify the token as an internal user or an external user.
The engine uses several data sources to make its classification determination, here are some examples:
- Settings Context: Relationship between the domain and the organization settings
- Inviter Context: How the domain relates to the inviter’s user profile
- Team Context: How the domain related to the existing team members
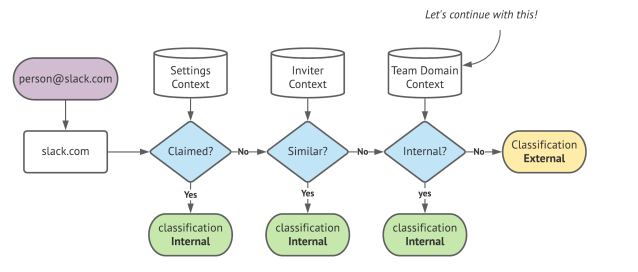
We first process all email addresses the user entered to extract the unique email domains. Next, we pass each domain through our classification pipeline to determine its classification. If it’s external, we suggest Slack Connect; if it’s internal, we suggest a Workspace Invite.
The Settings and Inviter Context operate in O(1) time by comparing the domain to our execution context. These allow us to determine classification sooner by leveraging claimed domains by the team or the domain’s relationship to the inviter’s email domain.
At Slack’s scale, it is important to ensure the algorithm executes in linear time (O(N) where N is the number of unique domains provided). Only the Team Context lookup requires a database round-trip per domain.
The Team Context is an aggregate dataset of email domain counts for a given team grouped by role. Based on the size of the team, we use a threshold of a domain count which the count needs to be above to be considered an internal domain.
It’s essentially a dynamic list of calculated domains that are very likely to be part of the organization. And thus, being categorized as internal.
Let’s dive deeper in the team context data store as it stands central to our classification engine.
Team domain context
Since teams at Slack can grow to over a million users, the query to perform this aggregation check real-time during the classification process would be too expensive. We had to design a data model that reflects the aggregate dataset in real-time.
We use Vitess to store the aggregate data in a simple table shared by team_id. Since classification always happens in the context of a single team, this ensures that we always only hit a single shard.
CREATE TABLE `domains` (
`team_id` bigint unsigned NOT NULL,
`domain` varchar NOT NULL,
`count` int NOT NULL DEFAULT '0',
`date_update` int unsigned NOT NULL,
`role` varchar NOT NULL,
PRIMARY KEY (`team_id`,`domain`,`role`)
)For each team, we store the total count of users grouped by their role, matching the same email domain. This allows us to use different weights based on their role. Example, an admin having “slack-corp.com” is a bigger indication that it’s an internal domain than a guest user.
Note that the count column is a signed number, this is designed on purpose to detect drift in our dataset. If it goes negative, we know something is off and that we need to fix the drift with a component that we call the “Healer” (this will be covered in more detail in later sections!) We therefore consider the value of count to be eventually consistent.
Domain thresholds by example
With the team domain context containing the total number of users per domain grouped by role, we can now make data-driven decisions for email classification.
Let’s use an example scenario. Company A has 100 employees, both US and Canadian offices, and their HR department issues region-based email addresses to all of their employees.
Company A has also three consultants as full members in their org from Consult Co.
70 employees work in the US and have a <name>@example-a.com email address, while the 30 employees located in Canada have <name>@example-a.ca.
Our team domain context table contains the following:
| Team | Role | Domain | Count |
|---|---|---|---|
| Company A | admin | example-a.com | 2 |
| Company A | member | example-a.com | 68 |
| Company A | member | example-a.ca | 30 |
| Company A | member | consult-co.com | 3 |
The total member size of Company A’s Slack workspace is 103 members.
With a 10% threshold configuration, we state that for a domain to be considered “internal” there must be at least 10% or more employees in your organization with that given domain.
The breakdown for our existing domains:
- example-a.com: 67.9%
- example-a.ca: 29.1%
- consult-co.com: 2.9%
Since both example-a.com and example-a-ca are above 10%, they are considered internal. While consult-co.com at 2.9% is considered external.
An eventually-consistent architecture
The relationship between domains and teams evolves over time. Users may change their email address, and new users may have been invited or deactivated. Recalculating the entire dataset for each event is too expensive for all the teams at Slack.
Because of these scale requirements we’ve designed an eventually-consistent architecture that can provide real-time domain knowledge while maintaining a low compute footprint.
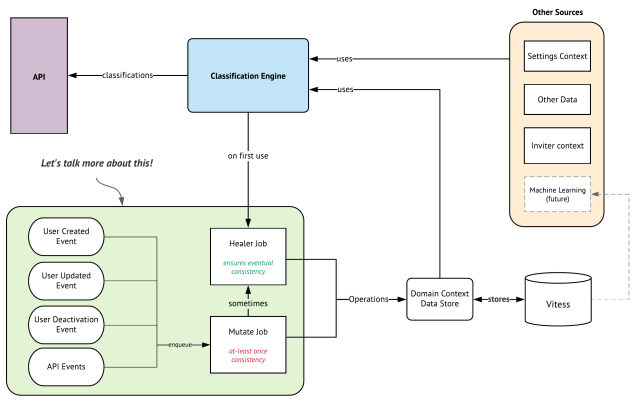
The classification engine is the business logic that uses data sources to make a determination on the type of email that was provided on the API. On the bottom left is the mutation logic that performs operations to keep the data up to date in real-time.
Real-time mutations
When users join a workspace or change their email address, we enqueue a Mutate Job on the job queue which will perform one or more mutations to update the total count of domains for their given aggregate in the background.
These mutations use simple arithmetic UPSERTs which perform relative additions or subtractions of the existing count values that can operate just within Vitess. Decoupling the application state from the operations.
Example #1 – A user joins the workspace
Our first example scenario, Slack has five admins and 2,000 regular members with the email domain <span style="font-weight: 400">slack-corp.com</span>. Jessica joins Slack as a new hire and has a user account provisioned for her.
Before her Slack account is created, our state contains the following:
| Team | Role | Domain | Count |
|---|---|---|---|
| Slack | admin | slack-corp.com | 5 |
| Slack | member | slack-corp.com | 2000 |
When her account is provisioned, an event fires that enqueues a mutation job which will perform the following query:
UPSERT count=count+1 WHERE team_id=7 AND domain='slack-corp.com' AND role='member';The existing row is incremented by one and our updated state becomes:
| Team | Role | Domain | Count |
|---|---|---|---|
| Slack | admin | slack-corp.com | 5 |
| Slack | member | slack-corp.com | 2001 |
With all UPSERTs doing a row-level lock, and using the local existing state to do a simple +1, we can reliably do adjustments to the current count even if there are many overlapping operations on the same value. Eventually, we have a consistent total count.
Example #2 – Role change and a user is deactivated
Let’s consider a second example where two events occur simultaneously: The first event is a user being deactivated (resulting in a -1) and a second user changing their role from a member to an owner.
The initial state indicates we have 2,005 users:
| Team | Role | Domain | Count |
|---|---|---|---|
| Slack | admin | slack-corp.com | 5 |
| Slack | member | slack-corp.com | 2000 |
Since we group our counts by role, a role change requires two operations: one decrementing their old aggregate row, and a second incrementing their new role aggregate row.
--Query 1:
UPSERT count=count=1
WHERE team_id=7 AND domain='slack-corp.com' AND role='member';
--Query 2:
UPSERT count=count+1
WHERE team_id=7 AND domain='slack-corp.com' AND role='owner';
The user deactivation is a separate mutation job that will perform a third operation:
--Query 3:
UPSERT count=count-1
WHERE team_id=7 AND domain='slack-corp.com' AND role='member';
Due to the nature of job queues, we cannot guarantee that these queries will execute in the exact same order as above. Let’s assume there is some slight delay between query 1 and query 2, making the order of actual operations the following:
UPSERT count=count=1 WHERE team_id=7 AND domain='slack-corp.com' AND role='member';
UPSERT count=count-1 WHERE team_id=7 AND domain='slack-corp.com' AND role='member';
-- snapshot here --
<span style="font-weight: 400">UPSERT count=count+1 WHERE team_id=7 AND domain='slack-corp.com' AND role='owner';</span>If we would take a snapshot of the state right between the second and the third query, our state would be for a moment the following:
| Team | Role | Domain | Count |
|---|---|---|---|
| Slack | admin | slack-corp.com | 5 |
| Slack | member | slack-corp.com | 1998 |
Only one member was deactivated, while our total count for Slack is 2,003. It seems that two accounts were deactivated. This is a side-effect of operations running out of order.
If we unpause and let the third query execute as well, the state will eventually be consistent:
| Team | Role | Domain | Count |
|---|---|---|---|
| Slack | admin | slack-corp.com | 5 |
| Slack | member | slack-corp.com | 1998 |
| Slack | member | slack-corp.com | 1 |
After all queries are completed, our final total count is again at 2,004, which is the correct amount of active users.
Data drift
With asynchronous job queues, it’s not guaranteed that a certain mutation job executed only once, twice, or not at all. Because of this, there is going to be a natural drift of total counts over time which must be healed by recalculating the reverse operations to fix the drift.
A great example of this is when a company has four guests with the domain <span style="font-weight: 400">example.com</span>, and three of them are removed from the team.
Our initial state:
| Team | Role | Domain | Count |
|---|---|---|---|
| slack | guest | example.com | 4 |
For some reason, one of the jobs is executed three times due to a fatal error right before it could ACK to the job coordinator that it was completed. If you don’t acknowledge the job in time, it gets automatically re-queued.
If we take a snapshot of our state right now, we clearly see some invalid state:
| Team | Role | Domain | Count |
|---|---|---|---|
| Slack | guest | example.com | -1 |
We originally had a count of four guests with example.com, there were five decrements which makes the new total count -1.
This behavior is considered data drift and if left unchecked will result in less reliable email classification results. Next, we will talk about the self-healing nature of our classification system.
Self-healing system
To prevent the drift described above, we’ve also built a Healer component that will calculate the current drift and calculate the appropriate operations it must perform to realign the counts.
Since our counts can continue to change based on new events, we can’t just sum up all users and then replace all records in the table, this would result in lost records for the events that occurred during the heal itself.
The healer has the following five distinct phases:
- Fetch all current domain counts for the team
- Iterate through all users of the team and do a second in-memory count
- Compare the in-memory counts to the current domain counts
- Calculate the operations needed to align the two sets
- Apply the operations with the same UPSERT queries as our mutations
Since heal operations are still simple UPSERTs that do a +N or -N with the existing count value in the database, any mutations that occur between our five phases are never lost.
Remember that unsigned count column in our schema? When a mutation job detects that it goes negative during its execution, it will enqueue an additional healer job to fix it!
In addition to detecting negative drift through our mutation jobs, heals are also performed when they enter an email address for the first time, upgrade to a new plan, or when they haven’t used the email classification system for a while.
The healer ensures we have an eventual consistent dataset.
Putting it all together
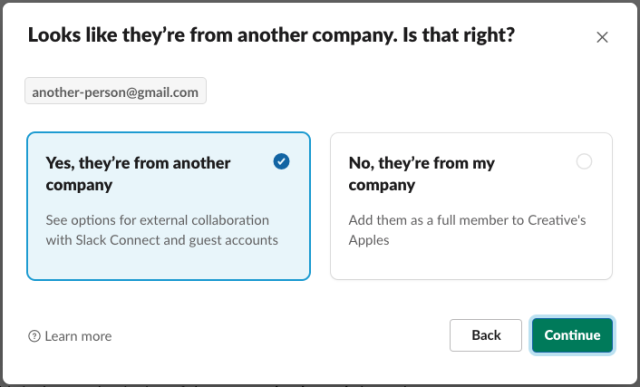
By connecting the classification engine to our existing tokenizer, we can now determine whether a given email address belongs to someone who is part of your organization (highlighted below) or to someone external (shown as a paper plane). The email classification provided predictions whether each provided email is internal or external.
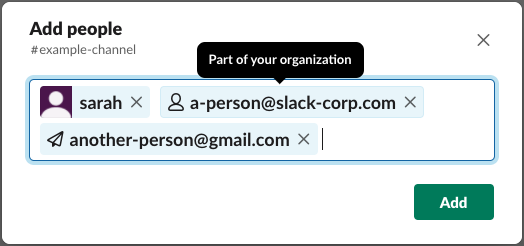
Since <span style="font-weight: 400">another-person@gmail.com</span> was classified as external, we can now provide a better experience to our users by providing a tailored invite step for external users.
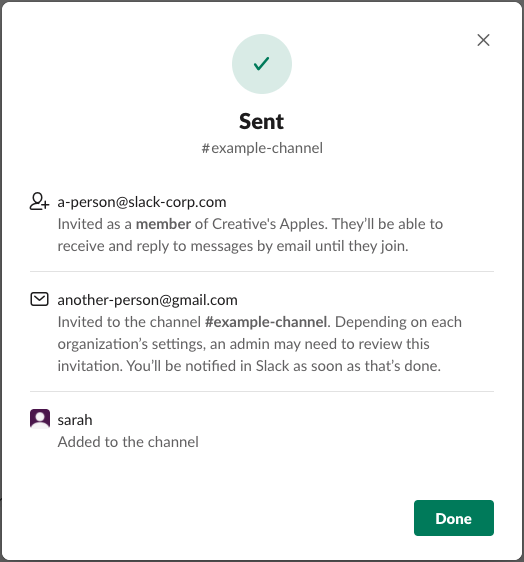
Once completed through the flow, we helped invite all 3 people to the channel in a simple easy-to-comprehend invite flow which dynamically changes itself based on data-driven email classification.
Conclusion
To provide smart suggestions to our end-users we developed a classification engine that can determine if an email address is internal or external. To support this, we need a near real-time representation of the total number of users each team has grouped by domain and role.
A backfill to perform aggregation for millions of users would have been too expensive to execute on a daily basis. By designing an eventually-consistent data model we were able to roll out this feature without backfills and with real-time data updates to provide a highly accurate data model for predicting email types in context to your team.
Closing notes
Designing real-time data models that can scale is hard. In this post we covered an eventual consistent system that leverages thresholds to do smart predication. Often, tradeoffs need to be made and in our use-case, we allow reduced accuracy in exchange for faster performance.We’ve just scratched the service for email classification, and we’re excited to see what we’ll be able to do next with deep learning! If you like designing architecture, data models and async service, come join us!





