




From the very beginning of Slack, MySQL was used as the storage engine for all our data. Slack operated MySQL servers in an active-active configuration. This is the story of how we changed our data storage architecture from the active-active clusters over to Vitess — a horizontal scaling system for MySQL. Vitess is the present and future of Datastores for Slack and continues to be a major success story for us. From the solid scalability fundamentals, developer ergonomics, and the thriving community, our bet on this technology has been instrumental for Slack’s continued growth.
Our migration to Vitess began in 2017 and Vitess now serves 99% of our overall query load. We expect to be fully migrated by the end of 2020. In this post, we will discuss the design considerations and technical challenges that went into choosing and adopting Vitess, as well as an overview of our current Vitess usage.
Availability, performance, and scalability in our datastore layer is critical for Slack. As an example, every message sent in Slack is persisted before it’s sent across the real-time websocket stack and shown to other members of the channel. This means that storage access needs to be very fast and very reliable.
In addition to providing a critical foundation for message sending, over the last three years Vitess has given us the flexibility to ship new features with complex data storage needs, including Slack Connect and international data residency.
Today, we serve 2.3 million QPS at peak. 2M of those queries are reads and 300K are writes. Our median query latency is 2 ms, and our p99 query latency is 11 ms.
The beginning
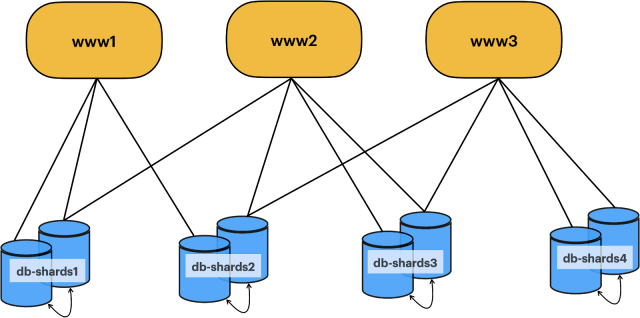
Slack started as a simple LAMP stack: Linux, Apache, MySQL, and PHP. All our data was stored on three primary database clusters based on MySQL:
- Shards: These virtually contained all the customer data tied to using Slack, such as messages, channels, and DMs. The data was partitioned and scaled horizontally by workspace id (a workspace is the specific Slack domain you login into). All the data for a given workspace was stored on the same shard, so the application just needed to connect to that one database.
- Metadata cluster: The metadata cluster was used as a lookup table to map a workspace id to the underlying shard id. This means that to find the shard for a particular Slack domain to a workspace, we had to lookup the record in this metadata cluster first.
- Kitchen sink cluster: This cluster stored all the other data not tied to a specific workspace, but that was still important Slack functionality. Some examples included the app directory. Any tables that did not have records associated with a workspace id would have gone into this cluster.
The sharding was managed and controlled by our monolith application, “webapp”. All data access was managed by webapp, which contained the logic to look up metadata for a given workspace, and then create a connection to the underlying database shard.
From a dataset layout perspective, the company started out using a workspace-sharded model. Each database shard contained all of a workspace’s data, with each shard housing thousands of workspaces and all their data including messages and channels.
From an infrastructure point of view, all those clusters were made up of one or more shards where each shard was provisioned with at least two MySQL instances located in different datacenters, replicating to each other using asynchronous replication. The image below shows an overview of the original database architecture.
Advantages
There are many advantages to this active-active configuration, which allowed us to successfully scale the service. Some reasons why this worked well for us:
- High availability: During normal operations, the application will always prefer to query one of the two sides based on a simple hashing algorithm. When there are failures connecting to one of the hosts, the application could retry a request to the other host without any visible customer impact, since both nodes in a shard can take reads and writes.
- High product-development velocity: Designing new features with the model of having all the data for a given workspace stored on a single database host was intuitive, and easily extensible to new product functionality.
- Easy to debug: An engineer at Slack could connect a customer report to a database host within minutes. This allowed us to debug problems quickly.
- Easy to scale: As more teams signed up for Slack, we could simply provision more database shards for new teams and keep up with the growth. However, there was a fundamental limitation with the scaling model. What if a single team and all of their Slack data doesn’t fit our largest shard?
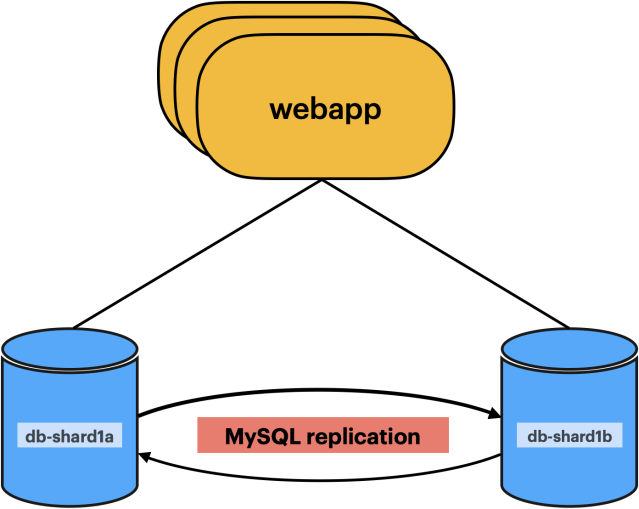
View into how a single shard is configured with multi-primary replication
Disadvantages
As the company grew, so did the number of product teams working on building new Slack features. We found that our development velocity was slowing down significantly in trying to fit new product features into this very specific sharding scheme. This led to some challenges:
- Scale limits: As we onboarded larger and larger individual customers, their designated shard reached the largest available hardware and we were regularly hitting the limits of what that single host could sustain.
- Stuck to one data model: As we grew, we launched new products such as Enterprise Grid and Slack Connect, both of which challenge the paradigm that all data for a team will be on the same database shard. This architecture not only added complexity to developing these features, but also a performance penalty in some cases.
- Hot spots: We found that we were hitting some major hotspots, while also massively underutilizing the majority of our database fleet. As we grew, we onboarded more and more enterprise customers with large teams, consisting of thousands of Slack users. An unfortunate outcome with this architecture was that we were unable to spread the load of these large customers across the fleet and we ended up with a few hot spots in our database tier. Because it was challenging to split shards and move teams, and difficult to predict Slack usage over time, we over provisioned most of the shards, leaving the long tail underutilized.
- Workspace and shard availability concerns: All core features, such as login, messaging, and joining channels, required the database shard that housed the team’s data to be available. This meant that when a database shard experienced an outage, every single customer whose data was on that shard also experienced a full Slack outage. We wanted an architecture where we can both spread the load around to reduce the hot spots, and isolate different workloads so that a unavailable second tier feature couldn’t potentially impact critical features like message sending
- Operations: This is a not standard MySQL configuration. It required us to write a significant amount of internal tooling to be able to operate this configuration at scale. In addition, given that in this setup we didn’t have replicas in our topology and the fact that the application routed directly to the database hosts, we couldn’t safely use replicas without reworking our routing logic.
What to do?
In the fall of 2016, we were dealing with hundreds of thousands of MySQL queries per second and thousands of sharded MySQL hosts in production. Our application performance teams were regularly running into scaling and performance problems and having to design workarounds for the limitations of the workspace sharded architecture.— we needed a new approach to scale and manage databases for the future.
From the early stages of this project, there was a question looming in our heads: should we evolve our approach in place or replace it? We needed a solution that could provide a flexible sharding model to accommodate new product features and meet our scale and operational requirements.
For example, instead of putting all the messages from every channel and DM on a given workspace into the same shard, we wanted to shard the message data by the unique id of the channel. This would spread the load around much more evenly, as we would no longer be forced to serve all message data for our largest customer on the same database shard.
We still had a strong desire to continue to use MySQL running on our own cloud servers. At the time there were thousands of distinct queries in the application, some of which used MySQL-specific constructs. And at the same time we had years of built up operational practices for deployment, data durability, backups, data warehouse ETL, compliance, and more, all of which were written for MySQL.
This meant that moving away from the relational paradigm (and even from MySQL specifically) would have been a much more disruptive change, which meant we pretty much ruled out NoSQL datastores like DynamoDB or Cassandra, as well as NewSQL like Spanner or CockroachDB.
In addition, historical context is always important to understand how decisions are made. Slack is generally conservative in terms of adopting new technologies, especially for mission-critical parts of our product stack. At the time, we wanted to continue to devote much of our engineering energy to shipping product features, and so the small datastores and infrastructure team valued simple solutions with few moving parts.
A natural way forward could have been to build this new flexible sharding model within our application. Since our application was already involved with database shard routing, we could just bake in the new requirements such as sharding by channel id into that layer. This option was given consideration, and some prototypes were written to explore this idea more fully. It became clear that there was already quite a bit of coupling between the application logic and how the data was stored. It also became apparent that it was going to be time consuming to untangle that problem, while also building the new solution.
For example, something like fetching the count of messages in a channel was tightly coupled to assumptions about what team the channel was on, and many places in our codebase worked around assumptions for organizations with multiple workspaces by checking multiple shards explicitly.

On top of this, building sharding awareness into the application didn’t address any of our operational issues or allow us to use read replicas more effectively. Although it would solve the immediate scaling problems, this approach seemed positioned to run into the very same challenges in the long term. For instance, if a single team’s shard got surprisingly hot on the write path, it was not going to be straightforward to horizontally scale it.
Why Vitess?
Around this time we became aware of the Vitess project. It seemed like a promising technology since at its core, Vitess provides a database clustering system for horizontal scaling of MySQL.
At a high level Vitess ticked all the boxes of our application and operational requirements.
- MySQL Core: Vitess is built on top of MySQL, and as a result leverages all the years of reliability, developer understanding, and confidence that comes from using MySQL as the actual data storage and replication engine.
- Scalability: Vitess combines many important MySQL features with the scalability of a NoSQL database. Its built-in sharding features lets you flexibly shard and grow your database without adding logic to your application.
- Operability: Vitess automatically handles functions like primary failovers and backups. It uses a lock server to track and administer servers, letting your application be blissfully ignorant of database topology. Vitess keeps track of all of the metadata about your cluster configuration so that the cluster view is always up-to-date and consistent for different clients.
- Extensibility: Vitess is built 100% in open source using golang with an extensive set of test coverage and a thriving and open developer community. We felt confident that we would be able to make changes as needed to meet Slack’s requirements (which we did!).
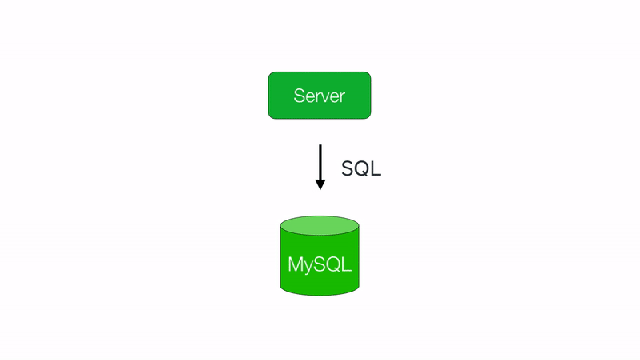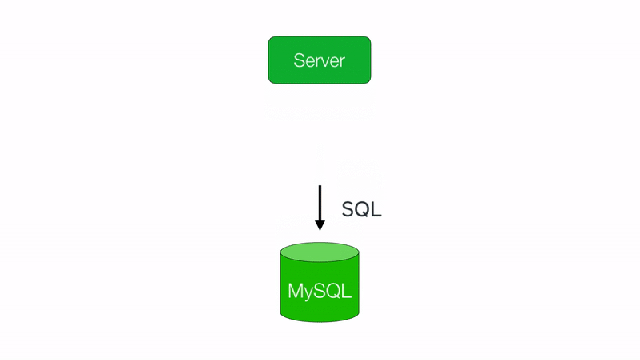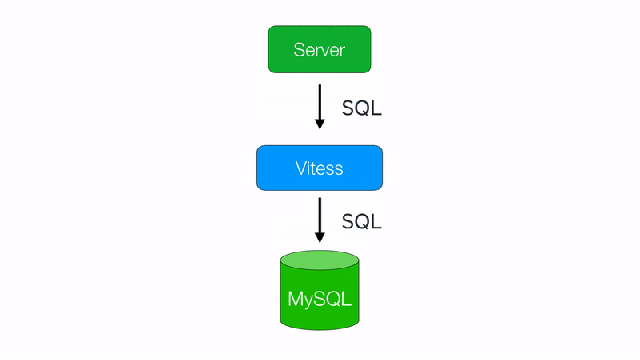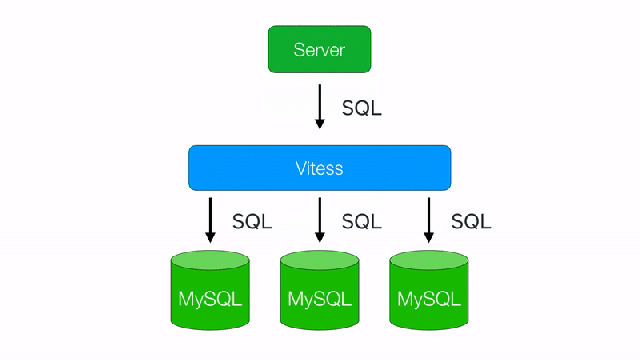
Image from SquareCash Vitess blog post. Check out their cool work too!
We decided to build a prototype demonstrating that we can migrate data from our traditional architecture to Vitess and that Vitess would deliver on its promise. Of course, adopting a new datastore at Slack scale is not an easy task. It required a significant amount of effort to set up all the new infrastructure in place.
Our goal was to build a working end-to-end use case of Vitess in production for a small feature: integrating an RSS feed into a Slack channel. It required us to rework many of our operational processes for provisioning deployments, service discovery, backup/restore, topology management, credentials, and more. We also needed to develop new application integration points to route queries to Vitess, a generic backfill system for cloning the existing tables while performing double-writes from the application, and a parallel double-read diffing system so we were sure that the Vitess-powered tables had the same semantics as our legacy databases. However, it was worth it: the application performed correctly using the new system, it had much better performance characteristics, and operating and scaling the cluster was simpler. Equally importantly, Vitess delivered on the promise of resilience and reliability. This initial migration gave us the confidence we needed to continue our investment in the project.
At the same time, it is still important to call out that during this initial prototype and continuing for the years since, we have identified gaps in Vitess in ways that it would not work for some of Slack-specific needs out of the box. As the technology showed promise at solving the core challenges we were facing, we decided it was worth the engineering investment to add-in the missing functionality.
Some key contributions by Slack include:
- Refactoring the topology metadata service for scalability across isolation regions.
- Closing some of the gaps in full MySQL query compatibility. [a], [b], [c], [d], [e].
- New tools to enable migrations of data into Vitess.
- New tools to load test and introspect Vitess.
- More robust integrations with Prometheus, Orchestrator, and Percona xtrabackup.
- And more!
Today, it is not an overstatement to say that some of the folks in the open source community are an extended part of our team, and since adopting Vitess, Slack has become and continues to be one of the biggest contributors to the open source project.
Now, exactly three years into this migration, we are sitting at 99% of all Slack MySQL traffic having been migrated to Vitess. We are on track to finish the remaining 1% in the next two months. We’ve wanted to share this story for a long time, but we waited until we had full confidence that this project was a success.
Here’s a graph showing the migration progression and a few milestones over the last few years:
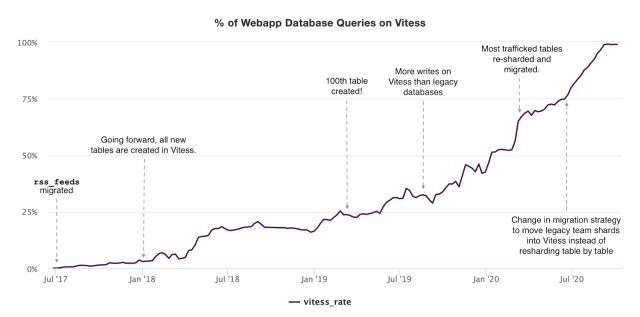 There are many other stories to tell in these 3 years of migrations. Going from 0% to 99% adoption also meant going from 0 QPS to the 2.3 M QPS we serve today. Choosing appropriate sharding keys, retrofitting our existing application to work well with Vitess, and changes to operate Vitess at scale were necessary and each step along the way we learned something new. We break down a specific migration of a table that comprises 20% of our overall query load in a case study in Refactoring at Scale, written with Maude Lemaire, a Staff Engineer at Slack. We also plan on writing about our change in migration strategy and technique to move whole shards instead of tables in a future blog post.
There are many other stories to tell in these 3 years of migrations. Going from 0% to 99% adoption also meant going from 0 QPS to the 2.3 M QPS we serve today. Choosing appropriate sharding keys, retrofitting our existing application to work well with Vitess, and changes to operate Vitess at scale were necessary and each step along the way we learned something new. We break down a specific migration of a table that comprises 20% of our overall query load in a case study in Refactoring at Scale, written with Maude Lemaire, a Staff Engineer at Slack. We also plan on writing about our change in migration strategy and technique to move whole shards instead of tables in a future blog post.
Has Vitess at Slack been a success?
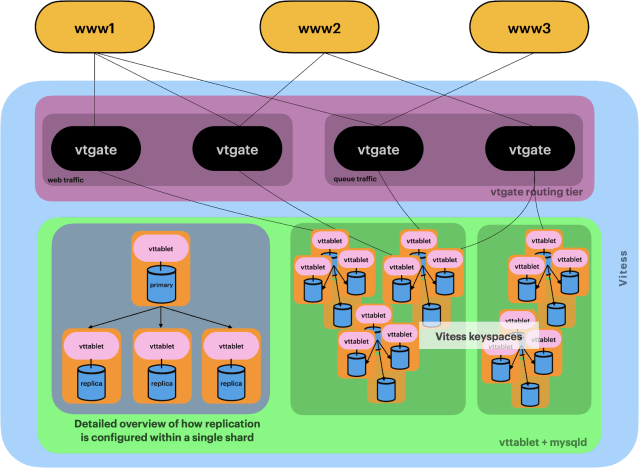
Today, we run multiple Vitess clusters with dozens of keyspaces in different geographical regions around the world. Vitess is used by both our main webapp monolith as well as other services. Each keyspace is a logical collection of data that roughly scales by the same factor — number of users, teams, and channels. Say goodbye to only sharding by team, and to team hot-spots! This flexible sharding provided to us by Vitess has allowed us to scale and grow Slack.
During March 2020, as our CEO Stewart Butterfield tweeted, we saw an unprecedented increased usage of Slack as the reality of the COVID-19 pandemic hit the U.S. and work/school shifted out of offices and became distributed. On the datastores side, in just one week we saw query rates increase by 50%. In response to this, we scaled up one of our busiest keyspaces horizontally using Vitess’s splitting workflows. Without resharding and moving to Vitess, we would’ve been unable to scale at all for our largest customers, leading to downtime.
As product teams at Slack started writing new services, they were able to use the same storage technology we use for the webapp. Choosing Vitess instead of building a new sharding layer inside our webapp monolith has allowed us to leverage the same technology for all new services at Slack. Vitess is also the storage layer for our International Data Residency product, for which we run Vitess clusters in six total regions. Using Vitess here was instrumental to being able to ship this feature in record time. It enabled our product engineering team to focus on the core business logic, while the actual region locality of the data was abstracted from their efforts. When we chose Vitess, we didn’t expect to be writing new services or shipping a multi-region product, but as a result of Vitess’s suitability and our investment in it over the last few years, we’ve been able to leverage the same storage technology for these new product areas.
Now that the migration is complete, we look forward to leveraging more capabilities of Vitess. We have been already investing in VReplication, a feature that allows you to hook into MySQL replication to materialize different views of your data.
The picture below shows a simplified version of what our Vitess deployment at Slack looks like.
Conclusion
This success still begs the question: Was this the right choice? In Spanish, there is a saying that states: “Como anillo al dedo”. It is often used when a solution fits with great exactitude. We think that even with the benefit of hindsight, Vitess was the right solution for us. This doesn’t mean that if Vitess didn’t exist, we would have not figured out how to scale our datastores. Rather, that with our requirements, we would have landed on a solution that would be very similar to Vitess. In a way, this story is not only about how Slack scaled its datastores. It is also a story that tells the importance of collaboration in our industry.
We wanted to give a shout out to all the people that have contributed to this journey: Alexander Dalal, Ameet Kotian, Andrew Mason, Anju Bansal, Brian Ramos, Chris Sullivan, Daren Seagrave, Deepak Barge, Deepthi Sigireddi, Huiqing Zhou, Josh Varner, Leigh Johnson, Manuel Fontan, Manasi Limbachiya, Malcolm Akinje, Milena Talavera, Mike Demmer, Morgan Jones, Neil Harkins, Paul O’Connor, Paul Tuckfield, Renan Rangel, Ricardo Lorenzo, Richard Bailey, Ryan Park, Sara Bee, Serry Park, Sugu Sougoumarane, V. Brennan and all the others who we probably forgot.





