

Cron scripts are responsible for critical Slack functionality. They ensure reminders execute on time, email notifications are sent, and databases are cleaned up, among other things. Over the years, both the number of cron scripts and the amount of data these scripts process have increased. While generally these cron scripts executed as expected, over time the reliability of their execution has occasionally faltered, and maintaining and scaling their execution environment became increasingly burdensome. These issues lead us to design and build a better way to execute cron scripts reliably at scale.
Running cron scripts at Slack started in the way you might expect. There was one node with a copy of all the scripts to run and one crontab file with the schedules for all the scripts. The node was responsible for executing the scripts locally on their specified schedule. Over time, the number of scripts grew, and the amount of data each script processed also grew. For a while, we could keep moving to bigger nodes with more CPU and more RAM; that kept things running most of the time. But the setup still wasn’t that reliable — with one box running, any issues with provisioning, rotation, or configuration would bring the service to a halt, taking some key Slack functionality with it. After continuously adding more and more patches to the system, we decided it was time to build something new: a reliable and scalable cron execution service. This article will detail some key components and considerations of this new system.
System Components
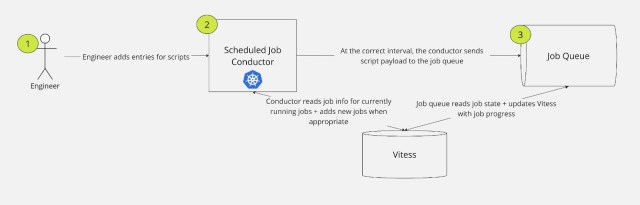
When designing this new, more reliable service, we decided to leverage many existing services to decrease the amount we had to build — and thus the amount we have to maintain going forward. The new service consists of three main components:
- A new Golang service called the “Scheduled Job Conductor”, run on Bedrock, Slack’s wrapper around Kubernetes
- Slack’s Job Queue, an asynchronous compute platform that executes a high volume of work quickly and efficiently
- A Vitess table for job deduplication and monitoring, to create visibility around job runs and failures
Scheduled Job Conductor
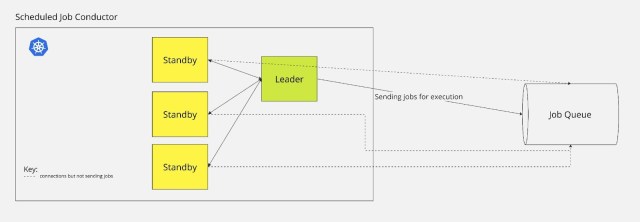
The Golang service mimicked cron functionality by leveraging a Golang cron library. The library we chose allowed us to keep the same cron string format that we used on the original cron box, which made migration simpler and less error prone. We used Bedrock, Slack’s wrapper around Kubernetes, to allow us to scale up multiple pods easily. We don’t use all the pods to process jobs — instead we use Kubernetes Leader Election to designate one pod to the scheduling and have the other pods in standby mode so one of them can quickly take over if needed. To make this transition between pods seamless, we implemented logic to prevent the node from going down at the top of a minute when possible since — given the nature of cron — that is when it is likely that scripts will need to be scheduled to run. It might first appear that having more nodes processing work instead of just one would better solve our problems, since we won’t have a single point of failure and we wouldn’t have one pod doing the memory and CPU intensive work. However, we decided that synchronizing the nodes would be more of a headache than a help. We felt this way for two reasons. First, the pods can switch leaders very quickly, making downtime unlikely in practice. And second, we could offload almost all of the memory and CPU intensive work of actually running the scripts to Slack’s Job Queue and instead use the pod just for the scheduling component. Thus, we have one pod scheduling and several other pods waiting in the wings.
Job Queue
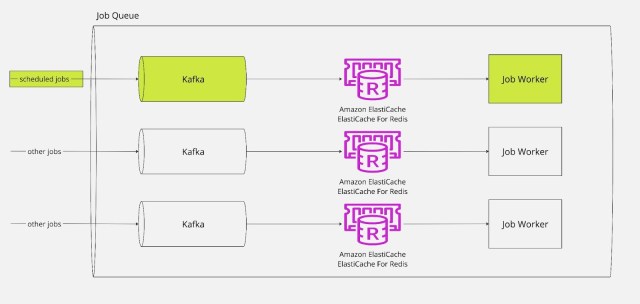
That brings us to Slack’s Job Queue. The Job Queue is an asynchronous compute platform that runs about 9 billion “jobs” (or pieces of work) per day. It consists of a bunch of theoretical “queues” that jobs flow through. In simple terms, these “queues’” are actually a logical way to move jobs through Kafka (for durable storage should the system encounter a failure or get backed up) into Redis (for short term storage that allows additional metadata of who is executing the job to be stored alongside the job) and then finally to a “job worker” — a node ready to execute the code — which actually runs the job. See this article for more detail. In our case, a job was a single script. Even though it is an asynchronous compute platform, it can execute work very quickly if work is isolated on its own “queue”, which is how we were able to take advantage of this system. Leveraging this platform allowed us to offload our compute and memory concerns onto an existing system that could already handle the load (and much, much more). Additionally, since this system already exists and is critical to how Slack works, we reduced our build time originally and our maintenance effort going forward, which is an excellent win!
Vitess Database Table
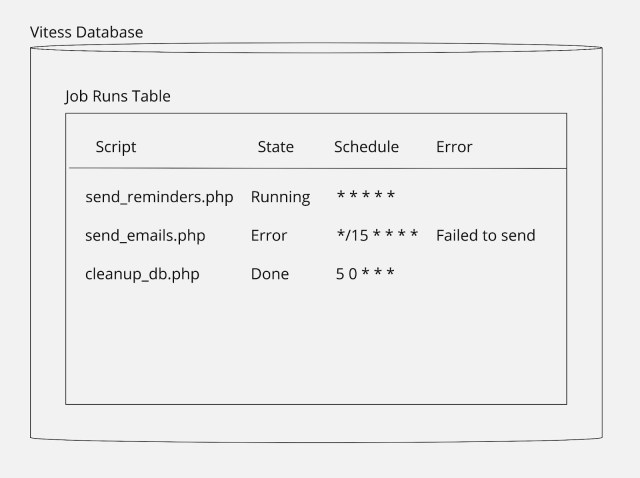
Finally, to round our service out, we employed a Vitess table to handle deduplication and report job tracking to internal users (other Slack engineers). Our previous cron system used flocks, a Linux utility to manage locking in scripts, to ensure that only one copy of a script is running at a time. This only-one requirement is satisfied by most scripts usually. However, there are a few scripts that take longer than their recurrence, so two copies could start running at the same time. In our new system, we record each job execution as a new row in a table and update the job’s state as it moves through the system (enqueued, in progress, done). Thus, when we want to kick off a new run of a job, we can check that there isn’t one running already by querying the table for active jobs. We use an index on script names to make this querying fast.
Furthermore, since we are recording the job state in the table, the table also serves as the backing for a simple web page with cron script execution information, so that users can easily look up the state of their script runs and any errors they encountered. This page is especially useful because some scripts can take up to an hour to run, so users want to be able to verify that the script is still running and that the work they are expecting to happen hasn’t failed.
Conclusion
Overall, our new service for executing cron scripts has made the process more reliable, scalable, and user friendly. While having a crontab on a single cron box had gotten us quite far, it started causing us a lot of pain and wasn’t keeping up with Slack’s scale. This new system will give Slack the room needed to grow, both now and far off into the future.
Want to help us work on systems like this? We're hiring!
Apply now




