


At Slack, we’ve long been conservative technologists. In other words, when we invest in leveraging a new category of infrastructure, we do it rigorously. We’ve done this since we debuted machine learning-powered features in 2016, and we’ve developed a robust process and skilled team in the space.
Despite that, over the past year we’ve been blown away by the increase in capability of commercially available large language models (LLMs) — and more importantly, the difference they could make for our users’ biggest pain points. Too much to read? Too hard to find stuff? Not anymore — 90% of users who adopted AI reported a higher level of productivity than those who didn’t.
But as with any new technology, our ability to launch a product with AI is predicated on finding an implementation that meets Slack’s rigorous standards for customer data stewardship. So we set out to build not just awesome AI features, but awesome and trusted AI.
The generative model industry is quite young; it is still largely research-focused, and not enterprise-customer focused. There were few existing enterprise-grade security and privacy patterns for us to leverage when building out the new Slack AI architecture.
Instead, to inform how we built out Slack AI, we started from first principles. We began with our requirements: upholding our existing security and compliance offerings, as well as our privacy principles like “Customer Data is sacrosanct.” Then, through the specific lens of generative AI, our team created a new set of Slack AI principles to guide us.
- Customer data never leaves Slack’s trust boundary.
- We do not train large language models (LLMs) on customer data.
- Slack AI only operates on the data that the user can already see.
- Slack AI upholds all of Slack’s enterprise-grade security and compliance requirements.
These principles made designing our architecture clearer, although sometimes more challenging. We’ll walk through how each of these informed what Slack AI looks like today.
Customer data never leaves Slack’s trust boundary
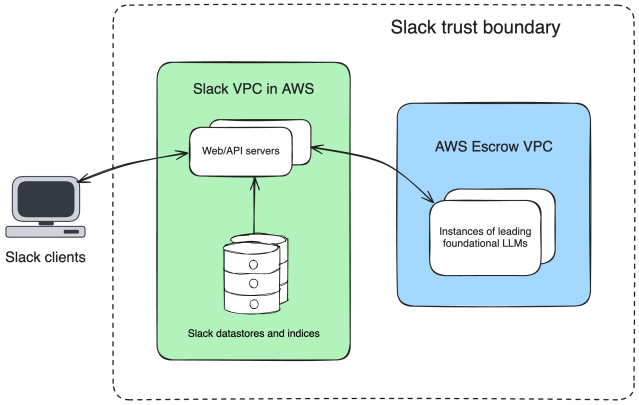
The first, and perhaps most important, decision we faced was how to ensure that we could use a top-tier foundational model while never allowing customer data to leave Slack’s trust boundary. In the generative model industry, most customers of foundational models were calling the hosted services directly, and alternative options were scarce.
We knew this approach wouldn’t work for us. Slack, and our customers, have high expectations around data ownership. In particular, Slack is FedRAMP Moderate authorized, which confers specific compliance requirements, including not sending customer data outside of our trust boundary. We wanted to ensure our data didn’t leave our trust boundary so that we could guarantee that third parties would not have the ability to retain it or train on it.
So we began to look for creative solutions where we could host a foundational model on our own infrastructure. However, most foundational models are closed-source: Their models are their secret sauce, and they don’t like to hand them to customers to deploy on their own hardware.
Fortunately, AWS has an offering where it can be the trusted broker between foundational model provider and customer. By using AWS, we are able to host and deploy closed-source large language models (LLMs) in an escrow VPC, allowing us to control the lifecycle of our customers’ data and ensure the model provider has no access to Slack’s customers’ data.
We had access to a top tier foundational model, hosted within our trust boundary, giving us assurances on our customer data.
We do not train large language models (LLMs) on customer data
The next decision was also key: We chose to use off-the-shelf models instead of training or fine-tuning models. We’ve had privacy principles in place since we began employing more traditional machine learning (ML) models in Slack, like the ones that rank search results. Among these principles are that data will not leak across workspaces, and that we offer customers a choice around these practices; we felt that, with the current, young state of this industry and technology, we couldn’t make strong enough guarantees on these practices if we trained a generative AI model using Slack’s customers’ data.
So we made the choice to use off-the-shelf models in a stateless way by employing Retrieval Augmented Generation (RAG). With RAG, you include all of the context needed to perform a task within each request, so the model does not retain any of that data. For example, when summarizing a channel, we’ll send the LLM a prompt containing the messages to be summarized, along with instructions for how to do so. The statelessness of RAG is a huge privacy benefit, but it’s a product benefit as well. All of Slack AI’s results are grounded in your company’s knowledge base — not the public Internet – which makes the results more relevant and accurate. You get the benefit of incorporating your proprietary and individual data set without the risk of a model retaining that data.
Using RAG can narrow down the set of models you can use; they need to have “context windows” large enough for you to pass in all the data you want to use in your task. Additionally, the more context you send an LLM, the slower your request will be, as the model needs to process more data. As you can imagine, the task of summarizing all messages in a channel can involve quite a bit of data.
This posed a challenge for us: Find a top-tier model with a large context window with fairly low latency. We evaluated a number of models and found one that suited our first use cases, summarization and search, well. There was room for improvement, though, and we began a long journey of both prompt tuning and chaining more traditional ML models with the generative models to improve the results.
RAG is getting easier and faster with each iteration of models: Context windows are growing, as is the models’ ability to synthesize data across a large context window. We’re confident that this approach can get us both the quality we’re aiming for while helping ensure our customers’ data is protected.
Slack AI only operates on the data that the user can already see
It is one of our core tenets that Slack AI can only see the same data that the requesting user can see. Slack AI’s search feature, for example, will never surface any results to the user that standard search would not. Summaries will never summarize content that the user could not otherwise see while reading channels.
We ensure this by using the requesting user’s Access Control List (ACLs) when fetching the data to summarize or search and by leveraging our existing libraries that fetch the data to display in channel or on the search results page.
This wasn’t hard to do, technically speaking, but it needed to be an explicit choice; the best way to guarantee this was to build on top of, and reuse, Slack’s core feature sets while adding some AI magic at the end.
It’s worth noting, too, that only the user who invokes Slack AI can see the AI-generated output. This builds confidence that Slack is your trusted AI partner: Only the data that you can see goes in, and then only you can see the output.
Slack AI upholds all of Slack’s enterprise-grade security and compliance requirements
There’s no Slack AI without Slack, so we ensured that we integrated all of our enterprise grade compliance and security offerings. We follow the principle of least data: We store only the data needed to complete the task, and only for the duration necessary.
Sometimes the least data is: None. Where possible, Slack AI’s outputs are ephemeral: Conversation summaries and search answers all generate point-in-time responses that are not stored on disk.
Where that’s not possible, we reused as much of Slack’s existing compliance infrastructure as possible, and built new support where we had to. Many of our compliance offerings come built in with our existing infrastructure, such as Encryption Key Management and International Data Residency. For others, we built in special support to make sure that derived content, like summaries, are aware of the messages that went into them; for example, if a message is tombstoned because of Data Loss Protection (DLP), any summaries derived from that message are invalidated. This makes DLP and other administrative controls powerful with Slack AI: Where these controls were already active on Slack’s message content, they are also active Slack AI outputs.
Whew — that was a long journey! And I didn’t even get to take you through how we build prompts, evaluate models, or handle spiky demand; we’ll save that for next time. But I’m glad we started here, with security and privacy: We want our customers to know how seriously we take protecting their data, and how we’re safeguarding it each step of the way.
Interested in helping us build Slack's AI capabilities? We're hiring!
Apply now




