

Last year, we migrated Airflow from 1.8 to 1.10 at Slack (see here) and we did a “Big bang” upgrade because of the constraints we had. This year, due to Python 2 reaching end of life, we again had a major migration of Airflow from Python 2 to 3 and we wanted to put our learnings from 2019 into practice. This post describes how we moved our Apache Airflow infrastructure, and hundreds of DAGs, from Python 2 to Python 3 in a more reliable “Red-black” deployment using Celery queues, resulting in the migration being completely transparent to our users.
Apache Airflow is a tool for describing, executing, and monitoring workflows. At Slack, we use Airflow to schedule our data warehouse workflows, which includes product metrics, business metrics, and also other use-cases like search and offline indexing. We run hundreds of workflows and tens of thousands of airflow tasks every day.
High-level steps for Airflow Python 3 migration
Here are the list of things we did for the migration:
- Set up a virtual environment: Created a working Python 3 virtual environment with Airflow and all the dependencies.
- Set up Python 3 workers: Launched Python 3 celery workers running the virtual environment from step 1, and make them pick tasks from a “python3” queue on Redis.
- Clean up phase 1: Removed stale or unused DAGs to make the migration easier.
- Fix Python 3 incompatibilities in DAGs: Updated DAGs to be Python 2/3 compatible but let them continue to run on Python 2 workers.
- Move the DAGs to Python 3 workers: Tested and switched DAGs from Python 2 to Python 3 workers. We started with a small set and kept increasing depending on success rate. If DAGs failed, we fixed forward or rolled back to Python 2 workers.
- Migrate the Airflow services to Python 3: Switched web server, scheduler, and flower to Python 3.
- Clean up phase 2: Cleaned up Python 2 references and virtual environments, and terminated Python 2 celery workers.
We did these steps in a dev environment first and then in prod. Let’s delve into each step in the following sections (except for the clean-up steps, which are self-explanatory).
Pro tip: The above order of migration is important; migrating scheduler or webserver to Python 3 before fixing DAG incompatibilities will result in errors because the scheduler in Python 3 will be unable to parse the DAG.
Set up a virtual environment
To set up a working python3 virtual environment, we did the following:
- Decouple Python system installation using pyenv: This is not a necessary step but we noticed that we were depending on system Python on Airflow boxes which had version 3.5.2 installed, and which don’t work with the more recent versions of Airflow. We resolved this by installing pyenv to manage Python installations and decouple from system installations. Pyenv comes with a virtual environment plugin and we used that for creating virtual environments.
- Use Poetry for dependency management of Python 2 and 3: We use Poetry to help install the right versions of dependencies for Python 2 and 3 needed for Airflow to work. These dependencies can be defined in one file (pyproject.toml). For example:

- Enable virtual environment relocation: We build virtual environments, ship them to Airflow boxes and we make use of the “–relocatable” option in virtualenv to make them “shippable”. However, in Python 3, this option is deprecated. To get past this, we updated the virtual environment’s files with the following command (basically replacing the shebang in the files with the final location of the virtual environment). This step is not needed if the virtual environment is not shipped, or if one is using containers.

Setup Python 3 workers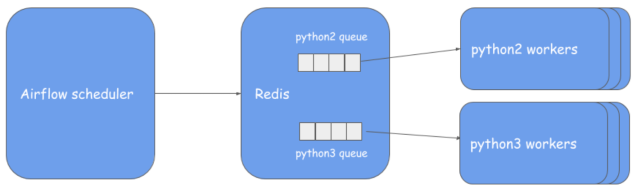
- Launch instances: In this step, we launched a fleet of python3 celery workers that runs the Airflow worker process using the Python 3 virtual environment that we built in step 1. These instances run alongside the existing python2 worker fleet.
- Configure queues: We configured the workers to listen to the python2 and python3 queues from Redis (the queue creation on Redis is automatic when airflow scheduler submits a task to Redis with a queue configured).

- Patch sqlalchemy: Airflow uses sqlalchemy—which is a Python SQL toolkit and object relational mapper—to read/write to the metadata DB. Some fields in the Airflow tables are written out in serialized or pickle format and are read by other Airflow services. Unfortunately, sqlalchemy writes out using a higher protocol version in Python 3 and this creates deserialization errors on the scheduler running on Python 2, resulting in celery failure task states not getting propagated to scheduler (Note: schedule/web servers move to Python 3 towards the end, and until then we need to support it on Python 2). To resolve this, we patched sqlalchemy to serialize using protocol version 2 on Python 3 workers, which can then be deserialized on Python 2. The change has to be made here. We can remove this once we migrate everything to Python 3.

Fix Python 3 incompatibilities in DAGs
Now that we have the infrastructure in place, the next step is to make the DAGs Python 2/3 compatible. It’s important that it’s Python 2/3 compatible for two reasons; Firstly, the services still on Python 2, like the scheduler, should still be able to parse the DAGs. Secondly, when we migrate to Python 3 workers, the rollback is simpler since there will be no code change in the DAGs except for the queue configuration. Here are some details about fixing incompatibilities:
- Automatic conversion of Python 2 to 3 code: Fortunately we didn’t have to go file by file and change Python 3 incompatibilities manually. We evaluated two automatic Python 2 to 3 converters: 2to3 and futurize. We chose futurize because it produces Python 2 and 3 compatible code, while 2to3 is more suitable for one way porting.
- Using futurize: futurize applies fixers (think of a fixer as something that fixes a specific Python 3 incompatibility, like converting print function to use parenthesis). futurize divides the fixers into stage 1 (safe changes) and stage 2 (potentially unsafe changes). We applied fixers carefully (especially in stage 2), one by one, and then tested and deployed them over the course of a few days so that it’s easy to narrow down issues. Fixers can be applied one by one like this:

- Incompatibility detection in CI tests: As we applied fixers, we wanted to make sure that users don’t add the same type of incompatibility again in the future that we just fixed. To avoid that, we added a CI test in PRs to catch Python 3 incompatibilities that have already been fixed. Here is the script.
Move DAGs to Python 3 workers
- Team by team migration: We needed to migrate hundreds of DAGs. Among the various ways we can pick DAGs to move over to Python 3 workers, we chose to move “team by team”. We contacted teams, got a point of contact in case of issues, prioritized the DAGs, tested DAGs locally, and then migrated them based on criticality (low criticality first). We fixed forward any runtime issues that we faced and barely had to rollback any DAGs. Once we migrated a few hundred DAGs and got enough confidence, we did a mass switch over of all the remaining ones.
- Usage of Python 3 DAG list: To move a DAG or task to Python 3, we need to set the “queue” attribute to “python3”. Instead of setting this config manually for every DAG we move, we maintained a file which had all the migrated DAGs. We then wrote code to read from that file and set the configuration automatically. This makes adding DAGs or rolling back easier because we needed to touch just one file.
Final steps
Once all the DAGs were moved to Python 3 workers, we switched over the Airflow scheduler, web server, and flower to Python 3 by shipping the Python 3 virtual environment built in step 1. Finally, we cleaned up all Python 2 related code and terminated the python2 workers. Now, we can call the migration done!
Common issues and solutions
- TypeError: a bytes-like object is required, not ‘str’
Solution: This is the most frequent error we observed, and happens because of type mismatch of bytes and strings due to Python 3 treating all strings as unicode. To fix this, we need to explicitly convert string to bytes using encode(). - Snowflake connector issues
Solution: We notice errors like “ERROR – asn1crypto.keys.PublicKeyInfo().unwrap() has been removed, please use oscrypto.asymmetric.PublicKey().unwrap() instead” with Snowflake operators. We resolved this by upgrading the snowflake-connector-python library to 2.x.
- Dictionary random ordering of entries
Solution: In Python 2, we had predictable ordering of keys in dictionaries, while in Python 3 this wasn’t the case. We solved this by using OrderedDict, which preserves the keys in insertion order. - Broken DAG: ‘ascii’ codec can’t decode byte 0xe2 in position 3825: ordinal not in range(128)
Solution: This issue happened when we tried to open files in Python 3 without specifying the encoding (it defaults to ASCII). To sort this out, we explicitly specified the encoding while opening files.
- futurize missed converting Python code in SQL files
Solution: We have a small set of SQL scripts with embedded Python code and futurize skipped it because it only looks at Python files for porting. This caused issues and we had to manually convert those files to be Python 2/3 compatible. - Openssl issue with Mac OS Catalina
Solution: We noticed issues when we moved to Python 3 where running Airflow locally gave errors like “Abort trap: 6”. This was due to an OpenSSL issue that specifically happens on Mac OS Catalina. We fixed this by running the following commands: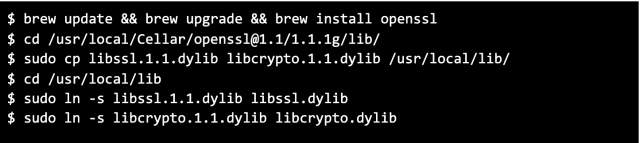
Conclusion
This Airflow migration proved to be reliable, completely transparent to users, and had zero SLA misses since we did a “red black” deployment. This was done by running both Python 2 and 3 infrastructure side-by-side and eventually moving all the traffic to Python 3. In conclusion, this migration went well, and we are excited that it enables us to use Python 3 features, not to mention the ability to upgrade to Airflow 2.0, in the future.
Big thanks to Prateek Kakirwar, Diana Pojar, Travis Cook, Joohee Yoo, Ajay Bhonsule for their contributions to the project and to Ross Harmes for reviewing this tech blog.
We are always looking for engineers to join our Data Engineering team. If you’d like to help us, please check out https://slack.com/careers





