

We are heavy users of Amazon Compute Compute Cloud (EC2) at Slack — we run approximately 60,000 EC2 instances across 17 AWS regions while operating hundreds of AWS accounts. A multitude of teams own and manage our various instances.
The Instance Metadata Service (IMDS) is an on-instance component that can be used to gain an insight to the instance’s current state. Since it first launched over 10 years ago, AWS customers used this service to gather useful information about their instances. At Slack, IMDS is used heavily for instance provisioning, and also used by tools that need to understand their running environments.
Information exposed by IMDS includes IAM credentials, metrics about the instance, security group IDs, and a whole lot more. This information can be highly sensitive – if an instance is compromised, an attacker may be able to use instance metadata to gain access to other Slack services on the network.
In 2019, AWS released a new version of IMDS (IMDSv2) where every request is protected by session authentication. As part of our commitment to high security standards, Slack moved the entire fleet and tools to IMDSv2. In this article, we are going to discuss the pitfalls of using IMDSv1 and our journey towards fully migrating to IMDSv2.
The v2 difference
IMDSv1 uses a simple request-and-response pattern that can magnify the impact of Server Side Request Forgery (SSRF) vulnerabilities — if an application deployed on an instance is vulnerable to SSRF, an attacker can exploit the application to make requests on their behalf. Since IMDSv1 supports simple GET requests, they can extract credentials using its API.
IMDSv2 eliminates this attack vector by using session-oriented requests. IMDSv2 works by requiring these two steps:
- Make a PUT request with the header X-aws-ec2-metadata-token-ttl-secondsheader, and receive a token that is valid for the TTL provided in the request
- Use that token in a HTTP GET request with the header named X-aws-ec2-metadata-token to make any follow-up IMDS calls
With IMDSv2, rather than simply making HTTP GET requests, an attacker needs to exploit vulnerabilities to make PUT requests with headers. Then they will have to use the obtained credentials to make follow-up GET requests with headers to access IMDS data. This makes it much more challenging for attackers to access IMDS via vulnerabilities such as SSRF.
Our journey towards IMDSv2
At Slack there are several instance provisioning mechanisms at play, such as Terraform, CloudFormation and various in-house tools that call the AWS EC2 API. As an organization, we rely heavily on IMDS to get insights into our instances during provisioning and the lifecycle of these instances.
We create AWS accounts per environment (Sandbox, Dev and Prod) and per service team and sometimes even per application – so we have hundreds of AWS accounts.
We have a single root AWS organization account. All our child accounts are members of this organization. When we create an AWS account, the account creation process writes information about the account (such as the account ID, owner details, and account tags) to a DynamoDB table. Information in this table is accessible via an internal API called Archipelago for account discovery.
Figuring out the scale of the problem
Before migrating, first we needed to understand how many instances in our fleet used IMDSv1. For this we used the EC2 CloudWatch metric called MetadataNoToken that counts how often the IMDSv1 API was used for a given instance.
We created an application called imds-cw-metric-collector to map those metrics and instance IDs we collected to alert various service teams and applications. The application used our internal Archipelago API to get a list of our AWS accounts, the aforementioned MetadataNoToken metric, and talked to our instance provisioning services to collect info like owner IDs and Chef Roles (for instances that are using Chef to configure them). Our custom app sent all those metrics to our Prometheus monitoring system.
A dashboard aggregated these metrics to track all instances that made IMDSv1 calls. This information was then used to connect with service teams, and work with them to update their services to use IMDSv2.
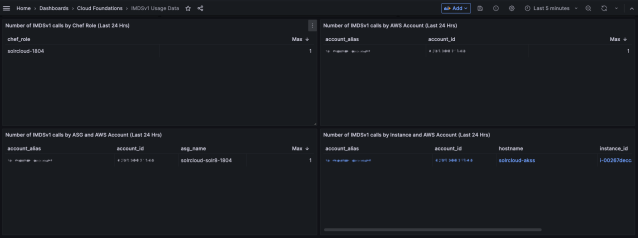
However, the list of EC2 instance IDs and their owners was only a part of the equation. We also needed to understand which processes on these instances were making these calls to the IMDSv1 API.
At Slack, for the most part, we use Ubuntu and Amazon Linux on our EC2 instances. For IMDSv1 call detection, AWS provides a tool called AWS ImdsPacketAnalyzer. We decided to build the tool and package it up as a Debian Linux distribution package (*.deb) in our APT repository. This allowed the service teams to install this tool on demand and investigate IMDSv1 calls.
This worked perfectly for our Ubuntu 22.04 (Jammy Jellyfish) and Amazon Linux instances. However, the ImdsPacketAnalyzer does not work on our legacy Ubuntu 18.04 (Bionic Beaver) instances so we had to resort to using tools such as lsof and netlogs in some cases.
As a last resort on some of our dev instances we just turned off IMDSv1 and listed things that were broken.
Stop calling IMDSv1
Once we had a list of instances and processes on those instances that were making the IMDSv1 calls, it was time for us to get to work and update each one to use IMDSv2 instead.
Updating our bash scripts was the easy part, as AWS provides very clear steps on switching from IMDSv1 and IMDSv2 for these. We also upgraded our AWS CLI to the latest version to get IMDSv2 support. However doing this for services that are written using other languages was a bit more complicated. Luckily AWS has a comprehensive list of libraries that we should be using to enforce IMDSv2 for various languages. We worked with service teams to upgrade their applications to IMDSv2 supported versions of libraries and roll these out across our fleet.
Once we had rolled out those changes, the number of instances using IMDSv1 dropped precipitously.
Turning off IMDSv1 for new instances
Preventing our services from using the IMDSv1 API only solved part of the problem. We also needed to turn off IMDSv1 on all future instances. To solve this problem, we turned to our provisioning tools.
First we looked at our most commonly used provisioning tool, Terraform. Our team provides a set of standard Terraform modules for service teams to use to create things such as AutoScaling groups, S3 buckets, and RDS instances. These common modules enable us to make a change in a single place and roll it out to many teams. Service teams that just want to build an AutoScaling group do not need to know the nitty-gritty configurations of Terraform to use one of these modules.
However we didn’t want to roll out this change to all our AWS child accounts at the same time, as there were service teams that were actively working on switching to IMDSv1 at this time. Therefore we needed a way to exclude those teams and their child accounts. We came up with a custom Terraform module called accounts_using_imdsv1 as the solution.Then we were able to use this module in our shared Terraform modules to keep or terminate IMDSv1 as per the example below:
module "accounts_using_imdsv1" {
source = "../slack/accounts_using_imdsv"
}
resource "aws_instance" "example" {
ami = data.aws_ami.amzn-linux-2023-ami.id
instance_type = "c6a.2xlarge"
subnet_id = aws_subnet.example.id
metadata_options {
http_endpoint = "enabled"
http_tokens = module.accounts_using_imdsv1.is_my_account_using_imdsv1 ? "optional" : "required"
}
}We started with a large list of accounts in the accounts_using_imdsv1 module as using IMDSv1, but we were slowly able to remove them as service teams migrated to IMDSv2.
Blocking instances with IMDSv1 from launching
The next step for us was to block launching instances with IMDSv1 enabled. For this we turned to AWS Service control policies (SCPs). We updated our SCPs to block launching IMDSv1 supported instances across all our child accounts. However, similar to the AutoScaling group changes we discussed earlier, we wanted to exclude some accounts at the beginning while the service owners were working to switch to IMDSv2. Our accounts_using_imdsv1 Terraform module came to the rescue here too. We were able to use this module in our SCPs as below. We blocked the ability to launch instances with IMDSv1 support and also blocked the ability to turn on IMDSv1 on existing instances.
# Block launching instances with IMDSv1 enabled
statement {
effect = "Deny"
actions = [
"ec2:RunInstances",
]
resources = [
"arn:aws:ec2:*:*:instance/*",
]
condition {
test = "StringNotEquals"
variable = "ec2:MetadataHttpTokens"
values = ["required"]
}
condition {
test = "StringNotEquals"
variable = "aws:PrincipalAccount"
values = module.accounts_using_imdsv1.accounts_list_using_imdsv1
}
}
# Block turning on IMDSv1 if it's already turned off
statement {
effect = "Deny"
actions = [
"ec2:ModifyInstanceMetadataOptions",
]
resources = [
"arn:aws:ec2:*:*:instance/*",
]
condition {
test = "StringNotEquals"
variable = "ec2:Attribute/HttpTokens"
values = ["required"]
}
condition {
test = "StringNotEquals"
variable = "aws:PrincipalAccount"
values = module.accounts_using_imdsv1.accounts_list_using_imdsv1
}
}
}
How effective are these SCPs?
SCPs are effective when it comes to blocking most IMDSv1 usage. However there are some places where they do not work.
SCPs do not apply to the AWS root organization’s account, and only apply to child accounts that are members of the organization. Therefore, SCPs do not prevent launching instances with IMDSv1 enabled, nor turning on IMDSv1 on an existing instance in the root AWS account.
SCPs also do not apply to service-linked roles. For example, if an autoscaling group launches an instance in response to a scaling event, under the hood the AutoScaling service is using a service-linked IAM role managed by AWS and those instance launches are not impacted by the above SCPs.
We looked at preventing teams from creating AWS Launch Templates that do not enforce IMDSv2, but AWS Launch Template policy condition keys currently do not provide support for ec2:Attribute/HttpTokens.
What other safety mechanisms are in place?
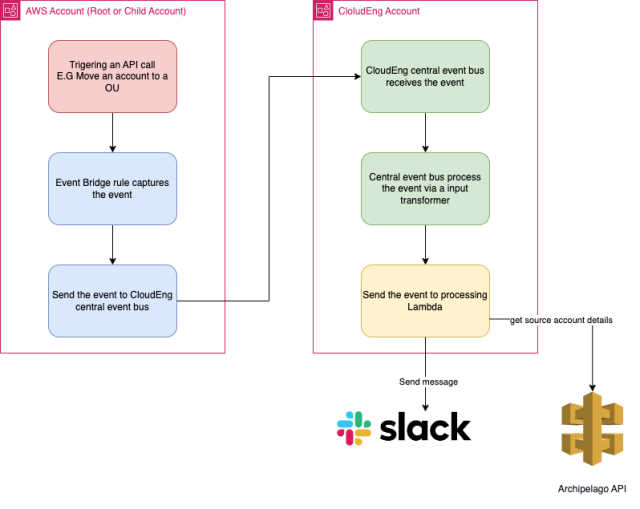
As there is no 100%-foolproof way to stop someone from launching an IMDSv1-enabled EC2 instance, we put in a notification system utilizing AWS EventBridge and Lambda.
We created two EventBridge rules in each of our child accounts using CloudTrail events for EC2 events. One rule captures requests to the EC2 API and the second captures responses from the EC2 API, telling us when someone is making a EC2:RunInstances call with IMDSv1 enabled.
Rule 1: Capturing the requests
{
"detail": {
"eventName": ["RunInstances"],
"eventSource": ["ec2.amazonaws.com"],
"requestParameters": {
"metadataOptions": {
"httpTokens": ["optional"]
}
}
},
"detail-type": ["AWS API Call via CloudTrail"],
"source": ["aws.ec2"]
}Rule 2: Capturing the responses
{
"detail": {
"eventName": ["RunInstances"],
"eventSource": ["ec2.amazonaws.com"],
"responseElements": {
"instancesSet": {
"items": {
"metadataOptions": {
"httpTokens": ["optional"]
}
}
}
}
},
"detail-type": ["AWS API Call via CloudTrail"],
"source": ["aws.ec2"]
}These event rules have a target setup to point them at a central event bus living in an account managed by our team.
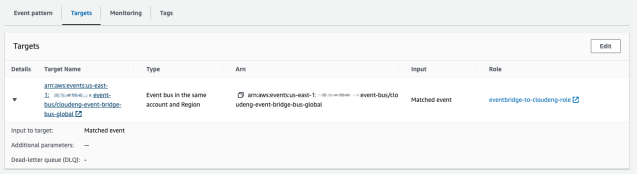
Events matching these rules are sent to the central event bus. The Central Event bus captures these events via a similar set of rules. Next it sends them through an Input Transformer to format the event similar to the following:
Input path:
{
"account": "$.account",
"instanceid": "$.detail.responseElements.instancesSet.items[0].instanceId",
"region": "$.region",
"time": "$.time"
}Input template:
{
"source" : "slack",
"detail-type": "slack.api.postMessage",
"version": 1,
"account_id": "<account>",
"channel_tag": "event_alerts_channel_imdsv1",
"detail": {
"text": ":importantred: :provisioning: instance `<instanceid> (<region>)` in the AWS account `<account>` was launched with `IMDSv1` support"
}
}Finally the transformed events get sent a Lambda function in our account.
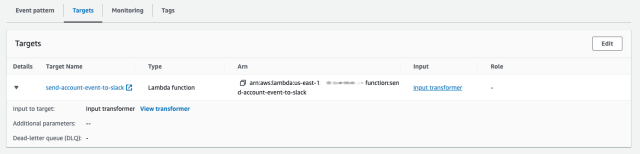
This Lambda function uses the account ID from the event and our internal Archipelago API to determine the Slack Channel, then sends this event to Slack.
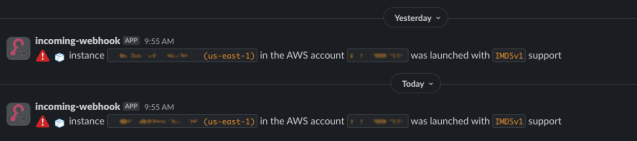
This flow looks like the following:
We also have a similar alert in place for when IMDSv1 is turned on for an existing instance.

What about the instances with IMDSv1 enabled?
Launching new instances with IMDSv2 is cool and all, but what about our thousands of existing instances? We needed a way to enforce IMDSv2 on them as well. As we saw above, SCPs do not block launching instances with IMDSv1 entirely.
This is why we created a service called IMDSv1 Terminator. It’s deployed on EKS and uses an IAM OIDC provider to obtain IAM credentials. These credentials have access to assume a highly restricted role in all our child accounts created for this very purpose.
The policy attached to the role assumed by IMDSv1 Terminator in child accounts is as below:
{
"Statement": [
{
"Action": "ec2:ModifyInstanceMetadataOptions",
"Condition": {
"StringEquals": {
"ec2:Attribute/HttpTokens": "required"
}
},
"Effect": "Allow",
"Resource": "arn:aws:ec2:*:*:instance/*",
"Sid": ""
},
{
"Action": [
"ec2:DescribeRegions",
"ec2:DescribeInstances"
],
"Effect": "Allow",
"Resource": "*",
"Sid": ""
}
],
"Version": "2012-10-17"
}
Similar to our earlier metric collector application, this also uses the internal Archipelago API to get a list of our AWS accounts, lists our EC2 instances in batches and analyzes each one and checks if IMDSv1 is enabled. If it is, the service will enforce IMDSv2 on the instance.
When the service remediates an instance, we get notified in Slack.

Initially we saw hundreds of these messages for existing instances, but as they were remediated and only new instances were launched with IMDSv2, we stopped seeing these messages. Now if an instance gets launched with IMDSv1 support enabled we have the comfort of knowing that it’ll get remediated and we’ll get notified.
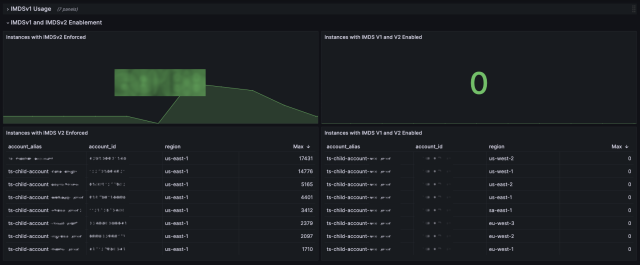
This service also sends metrics to our Prometheus monitoring system about the IMDS status of our instances. We can easily visualize what AWS accounts and regions that are still running IMDSv1 enabled instances, if there are any.
Some last words
Being able to enforce IMDSv2 across Slack’s vast network was a challenging but rewarding experience for the Cloud Foundations team. We worked with our large number of service teams to accomplish this goal, in particular our SecOps team who went above and beyond to help us complete the migration.
Want to help us build out our cloud infrastructure? We're hiring!
Apply now




