


When do you need to overhaul a large code base to address tech debt?
What is the best way to address widespread inconsistencies and outdated patterns?
How can you make significant architectural improvements to a complex application while still continuing to ship features?
These were questions we grappled with at the beginning of 2020, when we realized that tech debt in Slack’s mobile codebases had slowed development down enough to affect product roadmaps, and it would take a major refactor of our codebases to address it. This is the story of the first stage of the cross-functional initiative we launched to solve these issues. In later posts we’ll discuss the other phases and the results.
Part II of this series, about Modularization, is here; part III, about Modernization, is here
Background
In the early days, Slack workspaces tended to be fairly small: clients were able to fetch most of the data about a team each session and backend APIs could return complete data about a team, or send events to every user when any property changed. The development teams at Slack were also small, so it was easy to coordinate changes. Developers were familiar with a large portion of the features and codebase.
But over the years, Slack’s rapid growth required changes to the product’s behavior and assumptions. On a team with 500,000 users, or 20,000 channels, it is no longer possible for clients to fetch all the data, or for the backend to send every possible event to all clients. Also, as Slack grew, its feature set grew exponentially as well — we added support for app integrations, admin features, shared channels, better sign-in and onboarding, large enterprise deployments, and more. All of this has made the client and backend codebases much more complex, and as development teams also become larger, we outgrew our old development patterns and saw the need to make substantial second-generation investments in our codebases.
Since then, Slack’s webapp codebase has undergone two major re-investments: the Sonic project to rewrite the desktop client and the conversion of the PHP codebase to Hack. These efforts improved development for frontend and backend engineers at Slack thanks to enhancements in architecture, modernization of the tech stack, and establishment of reusable design patterns.
On the other hand, the mobile codebases have evolved organically since Slack’s launch, and had not undergone the same reinvestment. The Android app was rewritten in 2015, but since then new technologies have gained popularity. The team and the codebase have also grown considerably, and opinions about ideal architecture patterns have shifted. The iOS codebase hadn’t had a major rewrite since it was created in 2013. In addition to widespread tech debt, we needed to rethink the overall feature and application architecture. On both platforms, we had outdated or inconsistent design patterns, and legacy code was impacting both the development speed and reliability of the app.
Tech Debt
On both iOS and Android, most of the code was in large, monolithic app targets. Any changes to code in the app target required time consuming rebuilds, and there wasn’t clear separation between components, leading to tangled interdependencies and classes with overly complex responsibilities. This lack of separation, and factors like use of global state and singletons, led to brittle code where it was easy for changes to have unintended consequences — any changes to one part of the app could easily break another, even though they seemed unconnected. As Slack’s mobile development teams continued to grow, we needed to let developers work independently, and as our codebases grew, long build times became more of an issue.

We also had a number of stalled migrations on both platforms, since refactors or adoption of new technology had been hampered by lack of time or resources. On iOS, for example, we were trying to finish adoption of our infrastructure libraries, and also attempting to move to 100% Swift from Objective-C. On Android, we had been developing in Kotlin for some time, but our reliance on AutoValue and AutoValueGson to generate fast JSON parsers created an area where development remained in Java despite our desire to use Kotlin data classes and Moshi. Without concerted effort behind them, none of these migrations were making much progress towards completion.
This, along with a lack of strict conventions in many areas, meant there was a lot of inconsistency to contend with when writing features. On iOS, before this initiative we generally used a MVVM+C (Model, View, View Model + Coordinator) feature architecture, but it wasn’t universally adopted, and we didn’t have strong enough guidance on exactly how to implement it, or which classes should hold which responsibilities. In practice, this meant each feature was implemented slightly differently, which led to confusion.
On Android we were using an MVP (Model, View, Presenter) feature architecture, but it also hadn’t been fully adopted across the codebase. There were still a number of critical components that weren’t yet migrated, which made them harder for engineers to understand or test. Instead of having a single correct way to do things, there were often several different patterns in the codebase. This was confusing for developers, made it harder to onboard new team members, and created uncertainty about how to write new code.
These factors led to mobile feature development that was too complex and time consuming, which impacted overall feature ship dates. We realized that to address these issues and improve mobile development at Slack we needed to launch a major refactor of our mobile codebases, reducing tech debt and adopting new patterns and technologies that would enable us to build for a better future.
Rewrite? Refactor?
Once we decided on an overhaul of our mobile codebases, we considered a number of approaches to it. Should we do a complete rewrite and start from scratch? While it is appealing to start over and completely rearchitect the app, that would be a highly risky option. If we attempted a full rewrite, but hit major blockers part way through, we could waste a huge amount of time and resources. In addition, having old and new codebases under development simultaneously would entail developing new features in both for a lengthy period while the rewrite was underway. It’d also require reimplementing legacy features in the new codebase, which would be a massive effort. Finally, our developers felt that the basic structure of the codebase was sound, particularly on Android, so a full rewrite wasn’t required.
What about sharing code across platforms? There were various possible options we could explore for sharing code between iOS and Android, or with our desktop client as well. We could have shared UI code, through something like React Native or Flutter, or infrastructure code with C++ or cross-platform Kotlin. There are some clear benefits to using shared code: it would let us share development resources across platforms while reducing the number of times we’d have to implement each feature or service. But Slack has tried shared code before and we ran into significant drawbacks with that approach. We found it can lead to performance issues, lack of native look and feel, and complications with debugging and tooling. Slack’s mobile developers wanted to work with native language features and APIs, and build best-of-breed apps for each platform; so they generally weren’t in favor of this option.
Finally, a third option was to refactor the codebase in place, with ambitious plans to rethink the existing coding patterns and architecture, but without doing a full rewrite. This is the option we chose, in order to minimize risk, start seeing the payoff as soon as possible, and avoid having to maintain separate codebases. But choosing this option did mean that we had to deal with our existing tech debt — we had to migrate our legacy code and re-architect the apps in place, while keeping the app shippable and continuing development of new features.
Project Duplo
In the summer of 2020 we launched Project Duplo as a coordinated effort across iOS and Android. The overall goal was to reduce tech debt, improve development velocity, adopt more modern design patterns and technologies, and get our codebases ready for the next five years of development at Slack.
From the beginning, Project Duplo was an individual-contributor led initiative. Engineers on the mobile teams, with help from some key engineering leaders on other platforms, investigated possible options, wrote proposals, and came up with detailed project plans and goals for each platform.
We started outlining a proposal to get buy-in from our executive stakeholders. We’d be asking for a substantial long-term re-investment in mobile that would have to be balanced against other ongoing work — we had to make sure we gave our exec team a clear picture of what they would get in return. The proposal delineated the key issues we faced, documented the status of stalled migrations, and charted a course from our current state towards a future state that would have the properties we desired in terms of tech stack, architecture, and developer velocity.
Our proposal focused on three things:
- How the issues we were facing could be addressed by the effort we had in mind, backed by data regarding build times, test failure rates, progress of ongoing migrations, qualitative feedback from mobile devs, and explanation of the state of mobile architecture at peer companies. This was practical, project-by-project information that roughly mapped to a quarterly plan regarding staff allocations and project sequencing.
- How we would measure progress. This involved assembling annotated data dashboards to track progress toward our goals, such as reduction in build time, completion of technology migrations, or number of lines of code in the main app target. These were used for reporting and analysis of overall staff allocations.
- What failure modes would be most likely at each phase of the project. This demonstrated our thinking about what could go wrong, and allowed us to have detailed conversations about how we would run the project to mitigate those risks. This included technical risks but also organizational and cultural concerns regarding momentum and coordination on a large cross-functional project, including buy-in from other roles like Product, and the need for local leadership on all contributing teams.
While the details of the plans and objectives for the initiative were different on the two platforms, the themes were the same: Stabilization, Modularization, and Modernization.
- Stabilization entailed getting rid of the worst of our tech debt and anti-patterns, and finishing the most important of our stalled migrations.
- Modularization focused on breaking apart our app monolith into smaller components or building blocks (this is where we got the name Duplo) to reduce interdependencies, decrease build times, and allow independent development.
- Modernization was about adopting more forward-looking technologies and design patterns, to keep us compatible with industry trends and get ready for other technologies we might be interested in using in future.
We coordinated project planning and schedules across iOS and Android, with a small group of project leads drawn from both platforms. We launched the Stabilization phase first, which gave us time to make more concrete plans for the increasingly complicated Modularization and Modernization phases.
Stabilization
The Stabilization phase of Project Duplo lasted six months. In this phase, we wanted to “stop the bleeding”, by addressing key elements of tech debt that were slowing development on each platform. We talked to our mobile developers about the issues they thought were the most important to address, used code health metrics to assess which files in the codebase were the “worst”, and tried to focus on a few key areas where we could make big impacts. For this phase, we had a core team of developers who were dedicated to working on Duplo, as well as leads for each platform. This core team worked together throughout the Stabilization phase, to ensure we had developers focused on the project (and not pulled off onto feature development).
iOS goals
On iOS, we had three top goals in Stabilization:
- Port our remaining Objective-C code to Swift
- Finish migrating to our data access libraries
- Finish migrating to our native networking library
We also had secondary goals around adoption of UI components and reducing use of singletons for navigation.
At the beginning of Stabilization, we had about 80,000 lines of Objective-C remaining in the app (15% of the codebase at that time). Developers still had to support Objective-C interfaces for interoperability, which made it harder to use modern Swift patterns, and hurt performance due to the costs of marshaling data across the boundaries between Objective-C and Swift. Using both Objective-C and Swift in our frameworks also increased our build times. We wanted to move to a 100% Swift app, where developers could be free to use new language features.
We also had to finish a couple of major migrations to our own infrastructure libraries. We created several layers of data access libraries on top of our CoreData repository, but there were still many places in the legacy code which accessed CoreData directly. Direct CoreData calls led to bugs, data inconsistencies, crashes, and threading issues. We wanted to reach full adoption of our data provider frameworks to fix these issues and also allow us more freedom to change our caching implementation without having to update the rest of the app.
Similarly, we had written a native networking library to make API calls and other HTTP requests, and to handle WebSocket connections. It was only partially adopted, however; in some places we were still using a third-party library. This led to confusion about how specific APIs were implemented, and lack of consistency when writing features. Having two separate implementations also made it harder to add support for new networking features, like analytics, or priorities for API requests.
Android goals
On Android, we had five top goals in Stabilization:
- Split our monolith networked API call interface by feature area
- Migrate remaining database queries to SQLDelight
- Split out monolith database access interface into several data access objects (DAO).
- Standardize on the repository pattern for network/disk data access.
- Remove remaining usages of Otto bus events.
In the early days of the Android client, the set of network endpoints the client called was a pretty reasonable size and each was defined as a method in an interface called SlackApi. However, as our product and teams scaled, so did the number of endpoints this interface supported. Knowing that we wanted to modularize our application in a way that split apart features, a single interface that unnecessarily coupled these feature endpoints together would present a challenge.
SQLDelight is a library written by Square that we adopted to bring increased safety and performance to our SQLite queries while reducing boilerplate. It verifies all our SQL schemas, queries, and migrations during compilation while also adhering to best practices like query caching. Also, as we looked to the future phase of modularization, it could provide a way for schemas to be contributed to a database from many sub-projects. For all these reasons, we wanted to finish migrating handwritten database queries to SQLDelight.
Not unlike our SlackApi monolith, we had a monolithic interface for accessing and modifying locally persisted data called PersistentStore. It provided operations to nearly all Slack nouns (bots, messages, channels, commands, etc.). Breaking apart this interface into DAOs by type not only was consistent with more recent architectural decisions we had made, it was critical in unblocking the upcoming modularization work.
The repository pattern was another design decision we chose to standardize on. Prior to this, we had no standard way of abstracting whether to fetch and/or mutate data from local persistence or the server. Standardizing on the repository pattern made it much easier for us to support smarter caching behaviors to improve the application performance.
When the Android application was rewritten in 2015, RxJava was still fairly new and so the team chose Otto, another library by Square, to implement an event bus to propagate real time server events throughout the application. Since making that decision, most of the application moved to RxJava for purpose, but a number of examples remained. It was finally time to remove this long deprecated library.
Metrics
One of the key factors to the success of the Duplo project as a whole, and the Stabilization phase in particular, was having clear metrics to track progress for each goal. For some parts of the project we used standard methods like breaking the work down into tasks which could be collectively tracked in Jira. But while that was useful for burndowns of particular tasks, it didn’t give us a very good measure of our progress in completing large migrations. For that, we used automated scripts which tabulated the deprecated patterns remaining in the codebase, with dashboards to show our progress and determine how much work remained to be done. These enabled us to see if we were on track to complete each goal by our set deadlines, or if we were falling behind and might need to reallocate resources from one part of the project to another.
On iOS, we used these scripts to track progress on each of our Stabilization goals. For Objective-C to Swift conversion, the scripts could just search for remaining Objective-C files, and to determine progress on the other goals we searched for deprecated method and class names to see how much work remained.
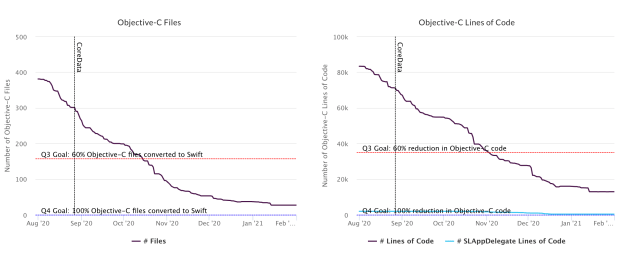
Stabilization complete
After six months of work on Duplo, by early 2021, we finished the Stabilization phase of the project. We successfully met our deadlines and completed all of the goals we had set on both iOS and Android for this first phase!
On iOS, removing Objective-C from our codebase and moving to 100% Swift not only allowed us to use more Swift language features but also made it easier to adopt new frameworks like Combine later in the project. Completing the migration onto our internal data frameworks fixed an entire class of crashes and bugs we had been seeing from improper CoreData access, and freed us up to make changes and performance optimizations in our caching layer without having to update feature code. Similarly, by fully moving onto our networking library, we were able to add support for new networking features and use them across the product. Completing both of these migrations made it easier for engineers to understand the infrastructure code and use it consistently. Instead of multiple ways to do the same thing in the codebase, we had a single correct way.
Achieving our Android stabilization goals had two primary impacts. Our more consistent codebase both helped us onboard teammates more easily and enabled teams to work in parallel when extracting these more focused components into their proper sub-projects.
At this point, we had removed some of the worst tech debt, the codebases were in better shape, and we had positive feedback from our developers that the project was already improving their productivity. Just as important, we proved that the overall project could be successful and deliver a substantial impact. This set us up for the later, more ambitious and forward looking phases of the project.
Our next step was to take on modularizing our codebases, adopting more modern patterns and technologies, and on iOS doing a significant overhaul of our app and feature architecture. We’ll talk about those phases of the project, and the results of the initiative as a whole in later posts!





