


On Thursday, 12 Oct. 2022, the EMEA part of the Datastores team — the team responsible for Slack’s database clusters — was having an onsite day in Amsterdam, the Netherlands. We’re sitting together for the first time after new engineers had joined the team, when suddenly a few of us were paged: There was an increase in the number of failed database queries. We stopped what we were doing and staged-in to solve the problem. After investigating the issue with other teams, we discovered that there was a long-running job (async job), and that it was purging a large amount of database records. This caused an overload on the database cluster. The JobQueue team — responsible for asynchronous jobs — realized that we couldn’t stop the job, but we could disable it completely (this operation is called shimming). This meant that the running jobs wouldn’t stop, but that no new jobs would be processed. The JobQueue team installed the shim, and the number of failed database queries dropped off. Luckily, this incident didn’t have an impact on our customers.
The very next day, the Datastores EMEA team got the same page. After looking into it, the team discovered that the problem was similar to the one experienced the day before, but worse. Similar actions were taken to keep the cluster in working condition, but there was an edge-case bug in Datastores automation which led to failure to handle a flood of requests. Unfortunately, this incident did impact some customers, and they weren’t able to load Slack. We disabled specific features to help reduce the load on the cluster, which helped give room to recover. After a while, the job finished, and the database cluster operated normally again.
In this post, we’ll describe what caused the issues, how our datastores are set up, how we fixed the issues, and how we’re preventing them from happening again.
The trigger
One of Slack’s customers removed a large number of users from their workspace. Removing a number of users in a single operation is not something customers do often; instead, they tend to remove them in small groups as they leave the company. User removal from Slack is done via an asynchronous job called forget user. When the forget user job started, it led to a spike in the database load. After a while, one of the shards couldn’t cope with the workload.
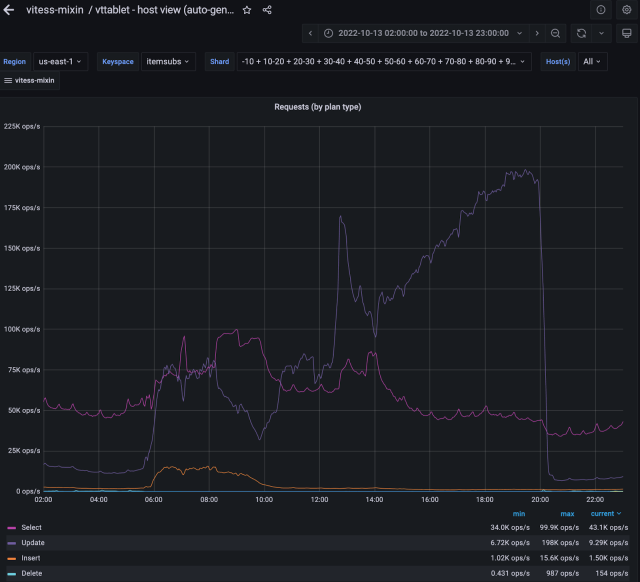
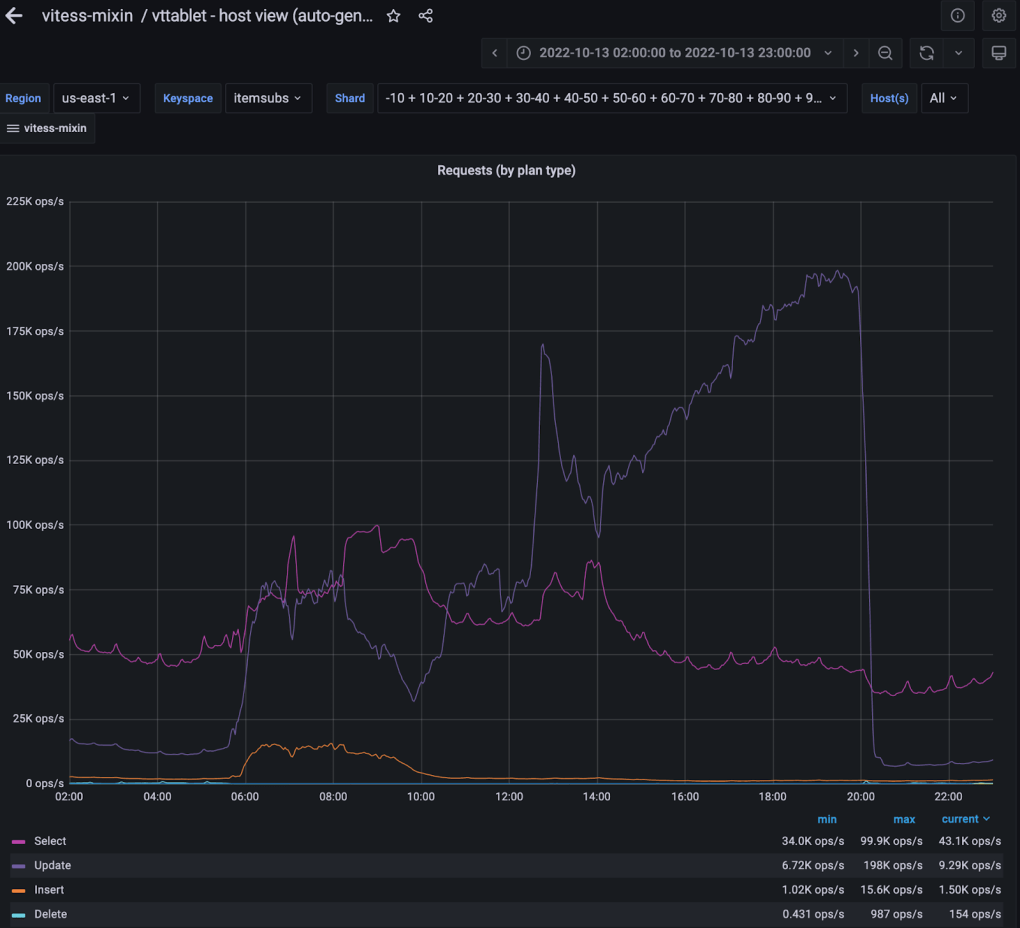
In the figure above, you can see a significant increase in the number of database queries. This is a screenshot of our monitoring dashboard during the incident; it was an essential tool during the incident, and it helped us make educated decisions.
Concepts
Let’s elaborate on some concepts before we take a deep dive into what happened.
Data storage
The Datastores team uses Vitess to manage Slack’s MySQL clusters. Tables in Vitess are organized into keyspaces. A keyspace is a distributed database. It looks like a single MySQL instance to client applications, while being distributed across multiple schemata of different MySQL instances.
Slack relies on a giant dataset that does not fit in a single MySQL instance. Therefore, we use Vitess to shard the dataset. There are other benefits from having a sharded database for each individual MySQL instance that is part of the dataset:
- Faster backup and restore
- Smaller backup sizes
- Blast radius mitigation: in case a shard is down, less uses are impacted
- Smaller host machines
- Distributed database query load
- Increase in write capacity
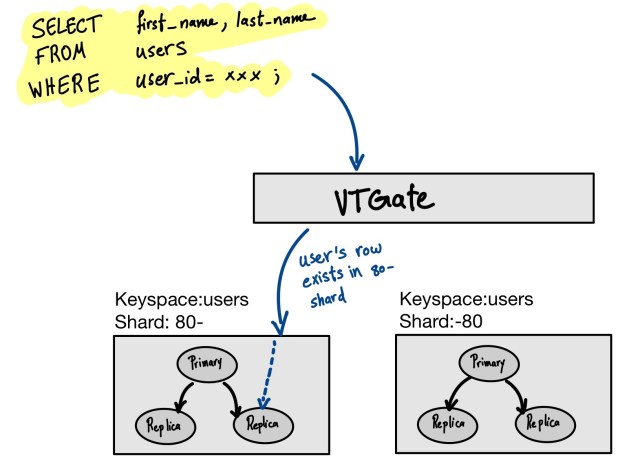
Every keyspace in Vitess is composed of shards. Think of a shard like a slice of a keyspace. Each shard stores a key range of keyspace IDs, and they collectively represent what is called a partition. Vitess shards the data based on the shards’ partition ranges.
For example, a “users” table can be stored in a keyspace composed of two shards. One shard covers keys in the -80 (hexadecimal key ID) range, and the other one, in the 80- range. -80 and 80- represent integer numbers below and above (2^64)/2, respectively. Assuming the sharding key is homogeneously distributed, this means that Vitess will store half the records in one shard, and half in the other one. Vitess also stores shard metadata internally so that VTGates can determine where to find the data when a user requests it. In the figure below, Vitess receives a SELECT statement for one of the user’s data. It looks into the metadata and determines that this user’s data is available in the shard with range “80-“:
Query fulfillment and replication
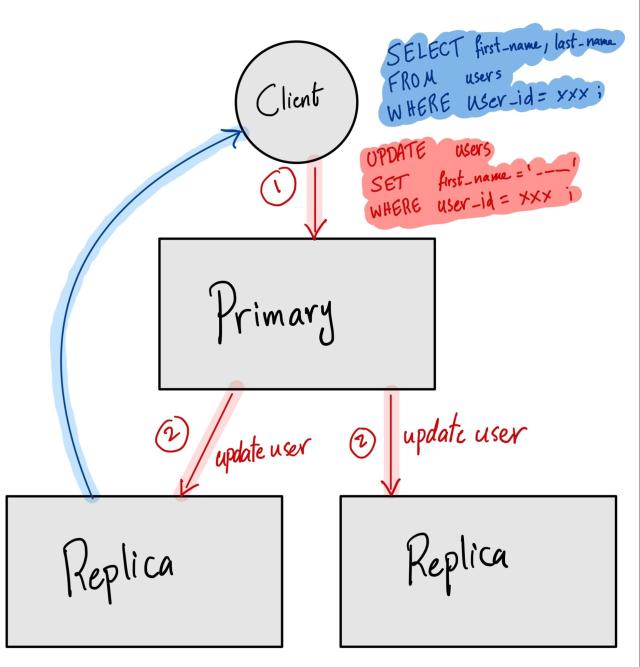
Slack is more than a messaging app, and many other features in Slack also depend on Vitess. To increase database throughput, as well as for failure tolerance, each shard has replicas. For each shard we create, there is one primary tablet and multiple replica tablets. Primary tablets are mainly responsible for queries modifying the data (DELETE, INSERT, UPDATE aka DML). Replicas are responsible for SELECT queries (the primary can also fulfill the SELECT queries, but it’s not recommended as there is limited room for scaling). After data is committed to the primary, it’s distributed to the replicas in the same shard via MySQL replication. The nature of replication is that changes are committed in the primary before they are applied in the replicas. Under low write load and a fast network, the data in the replica lags very little behind the data in the primary, But under high write load, replicas can lag significantly, leading to potential reads of stale/out of date data by client applications. What amount of replication lag is acceptable is dependent on the application. At Slack, we take replicas out of service if their replication lag is higher than one hour —- that is, if the data present on the replicas is missing changes from more than an hour ago.
Replacements
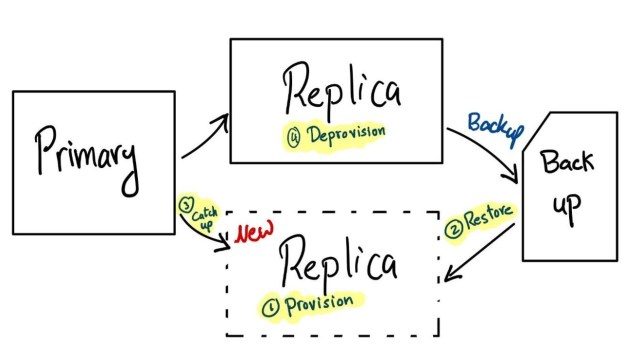
We have a procedure to replace an existing replica tablet with a new one. To simplify the logic, we can imagine it consisting of four steps. The first step is to provision the new host with all the dependencies, tools, security policies, MySQL, and Vitess. The second step is to wait for the tablet to obtain a copy of the data by restoring the most recent backup. The third step is to catch-up on replication. After this is done, the new replica can start serving traffic. Finally, the fourth step is to deprovision the old replica. We will discuss the third step — catching up — a bit in more detail below.
Catching-up
Once the most recent backup has been restored, the new replica has a copy of the dataset; however, it is not up to date, as it does not yet have the changes that have taken place since the backup was taken. Catching up means reading those changes from MySQL’s binary log and applying them to the copy of the data of the new replica. A replica is considered caught up once its replication lag is below an acceptance threshold. While we are discussing catch-up here from the point of view of provisioning a new replica, it’s worth noting that replicas are constantly catching up to any new changes that their primary may have taken.
What happened during the incident
With the high-level context, let’s get back to the incident. If you remember, a customer deleted many users from their workspace. This action kicked off the forget user job, which requires unsubscribing each affected user from the channels and threads they were subscribed to. So to delete users, it’s necessary also to locate and delete records representing each subscription of each user to each channel they belong to, and each subscription of each thread they participated in. This means that an enormous number of database queries were sent to the multiple Vitess shards. That’s the number of users being deleted multiplied by the average number of subscribed items per user. Unfortunately, there was one shard that contained 6% of the user’s subscription data. When this shard started to get that many requests, we started to see MySQL replication lag in the shard. The reason behind this lag is that replicas were having trouble keeping up with the primary due to the large amount of data being modified. To make matters worse, the high volume of write load also led the Vitess tablets to run out of memory on the shard primary, which caused the kernel to OOM-kill the MySQL process. To mitigate this, a replica was automatically promoted to primary, and a replacement started to take place. As described above, the replacement tablet restored data from the last backup, and tried to catch-up with the primary. Because of the large amount of database writes executed on the primary, they took a long time to catch-up, therefore not being able to start serving traffic fast enough. This was interpreted by our automation as the newly provisioned replica not being healthy, and therefore needing to be deprovisioned. In the meantime, high write load continued, causing the new primary to also run out of memory, resulting in its MySQL process being killed by the kernel. Another replica was promoted to primary, another replacement was started, and the cycle repeated.
In other words, the shard was in an infinite-loop of the primary failing, a replica being promoted to primary, a replacement replica being provisioned, trying (and failing) to catch-up, and finally getting deprovisioned.
How we fixed it
Datastores
The Datastores team broke the replacement loop by provisioning larger instance types (i.e. more CPU and memory) replicas manually. This mitigated the OOM-kill of the MySQL process. Additionally, we resorted to manual provisioning instead of automation-orchestrated replacement of failed hosts to mitigate for the issue in which our automation deprovisioned the replacements because it considered them unhealthy, due to the fact that they failed to catch-up in a reasonable amount of time. This was hard for the team because now they need to manually provision replicas, in addition to handling the high write traffic.
Forget User Job
The “forget user” job had problematic performance characteristics and caused the database to work much harder than it needed to. When a “forget user” job was being processed, it gathered all of the channels that the user was a member of and issued a “leave channel” job for each of them. The purpose of the “leave channel” job was to unsubscribe a user from all of the threads that they were subscribed to in that channel. Under typical circumstances, this job is only run for one channel at a time when a user manually leaves a channel. During this incident however, there was a massive influx of these “leave channel” jobs corresponding to every channel that every user being deactivated was a member of.
In addition to the sheer volume of jobs being much higher than normal during this incident, there were many inefficiencies in the work being done in the “leave channel” job that the team that owned it identified and fixed:
- First, each job run would query for all of the User’s subscriptions across all channels that they were a member of even though processing was only being performed for the one channel that they were “leaving”.
- A related problem occurred during the subsequent UPDATE queries to mark these subscriptions as inactive. When issuing the database UPDATEs for the thread subscriptions in the to-be-left-channel, the UPDATE query, while scoped to the channel ID being processed, included all of the user’s thread subscription IDs across all channels. For some users, this was tens of thousands of subscription IDs which is very expensive for the database to process.
- Finally, after the UPDATEs completed, the “leave channel” job queried for all of the user’s thread subscriptions again to send an update to any connected clients that would update their unread thread message count to no longer include threads from the channel they had just left.
Considering that these steps needed to take place for every channel of every user being deleted, it becomes pretty obvious why the database had trouble serving the load.
To mitigate the problem during the incident, the team optimized the “leave channel” job. Instead of querying for all subscriptions across all channels, the job was updated to both query for only the subscriptions in the channel being processed and only include these subscription IDs in the subsequent UPDATEs.
Additionally, the team identified that the final step to notify the clients about their new thread subscription state was unnecessary for deactivated users who could not be connected anyways so that work was skipped in the “forget user” scenario entirely.
Client team
As a final resort to maintain the user experience and let our users continue using Slack, the client team temporarily disabled the Thread View from the Slack client. This action reduced the amount of read queries toward Vitess. This meant that fewer queries hit the replicas. Disabling the feature was only a temporary mitigation. At Slack, our users’ experience is the top priority, so the feature was enabled again as soon as it was safe to do so.
How are we preventing it from happening again?
Datastores
Can you recall the particular edge-case issue that the team encountered with replacements during the incident? The team swiftly recognized its significance and promptly resolved it, prioritizing it as a top concern.
Besides fixing this issue, the Datastores team has started to adapt the throttling mechanism and the circuit breaker pattern, which have proven to be effective in safeguarding the database from query overload. By implementing these measures, the Datastores team is able to proactively prevent clients from overwhelming the database with excessive queries.
In the event that the tablets within the database infrastructure become unhealthy or experience performance issues, we can take action to limit or cancel queries directed at the affected shard. This approach helps to alleviate the strain on the unhealthy replicas and ensures that the database remains stable and responsive. Once the tablets have been restored to a healthy state, normal query operations can resume without compromising the overall system performance.
Throttling mechanisms play a crucial role in controlling the rate at which queries are processed, allowing the database to manage its resources effectively and prioritize critical operations. Because this is a crucial part of preventing overload, the Datastores team has been contributing related features and bug fixes to Vitess [1, 2, 3, 4, 5, 6, 7]. This is one of the positive outcomes of this incident.
In addition to throttling, the team has adopted the circuit breaker pattern, which acts as a fail-safe mechanism to protect the database from cascading failures. This pattern involves monitoring the health and responsiveness of the replicas and, in the event of an unhealthy state being detected, temporarily halting the flow of queries to that specific shard. By doing so, the team can isolate and contain any issues, allowing time for the replicas to recover or for alternate resources to be utilized.
The combination of throttling mechanisms and the circuit breaker pattern provides the Datastores team with a robust defense against potential overload and helps to maintain the stability and reliability of the database. These proactive measures ensure that the system can efficiently handle client requests while safeguarding the overall performance and availability of the database infrastructure.
Forget User Job
After the dust settled from the incident, the team that owned the “forget user” job took the optimizations further by restructuring it to make life much easier for the database. The “leave channel” job is appropriate when a user is actually leaving a single channel. However, during “forget user”, issuing a “leave channel” simultaneously for all channels that a user is a member of causes unnecessary database contention.
Instead of issuing a “leave channel” job for each channel that a user was a member of, the team introduced a new job to unsubscribe a user from all of their threads. “Forget user” was updated to enqueue just a single new “unsubscribe from all threads” job which resulted in much lower contention during “forget user” job runs.
Additionally, the Forget User job started to adapt the exponential back-off algorithm and the circuit breaker pattern. This means jobs that are getting failed will cope with the state of the dependencies (like database) and will stop retrying.
Conclusion
The incidents that occurred on October 12th and 13th, 2022 highlighted some of the challenges faced by the Datastores EMEA team and the teams running asynchronous jobs at Slack. The incident was triggered by a significant number of users being removed from a workspace, leading to a spike in write requests and overwhelming the Vitess shards.
The incident resulted in replicas being unable to catch up with the primary, and the primary crashing, leading to an infinite loop of replacements and further strain on the system. The Datastores team mitigated the issue by manually provisioning replicas with more memory to break the replacement loop.
The team responsible for the Forget User job played a crucial role in stopping the job responsible for the database write requests and optimizing the queries, reducing the load on the primary database.
To prevent similar incidents in the future, the Datastores team has implemented throttling mechanisms and the circuit breaker pattern to proactively prevent overwhelming the database with excessive queries. They have also adapted the exponential back-off algorithm to ensure failed jobs cope with the state of dependencies and stop retrying.
Overall, these measures implemented by the Datastores team, the team owning the forget user job and the team providing async job infrastructure help safeguard the stability and reliability of Slack’s database infrastructure, ensuring a smooth user experience and mitigating the impact of similar incidents.





