

Slack Connect, AKA shared channels, allows communication between different Slack workspaces, via channels shared by participating organizations. Slack Connect has existed for a few years now, and the sheer volume of channels and external connections has increased significantly since the launch. The increased volume introduced scaling problems, but also highlighted that not all external connections are the same, and that our customers have different relationships with their partners. We needed a system that allowed us to customize each connection, while also allowing admins to easily manage the number of ever-growing connections and connected channels. The existing configuration system did not allow customization by external connections, and admin tools were not built to handle the ever-growing scale. In this post, we’ll talk about how we solved these challenges on the backend (the frontend implementation is its own story, and deserves a separate blog entry).
Our first attempt at per-connection configuration
Slack Connect was built with security in mind. In order to establish a shared channel between two organizations, an external user must first accept a Slack Connect invitation, then the admins on both sides must approve the new shared channel, and only after those steps can the communication begin. This works fine for one-off channels between two companies, but the manual approval delay can become a nuisance—and potentially a barrier—when you need new channels created daily by many users in your organization. This also places a heavy burden on admins to review and approve an ever growing number of channels they might lack the context around.
The solution was to add the ability for admins to automate the approval process. We created a MySQL table which represented a connection between two teams. Team A could authorize automatic approvals for requests from team B, and vice versa. We needed several database columns to represent how the automatic approvals should work. Slack Admins got a dashboard where they could go in and configure this setting. This approach worked well, and further accelerated the growth of Slack Connect. But soon after we realized we needed to customize more than just approvals.
General solution to managing per-connection configuration
In addition to auto-approvals, we also needed connection-level settings to control restrictions on file uploads in Slack Connect channels and the ability to limit visible user profile fields for external users. In the long term, the plan was to customize the Slack Connect experience on a partner-by-partner level. The possibility of adding a new database table per setting was not appealing. We needed an extensible solution that could accommodate adding new settings without requiring infrastructure changes. The main requirements were support for built-in default configuration, a team-wide configuration, and the ability to set per-connection configurations. A connection/partner-level configuration allows for a specific setting to be applied on a target partner. Default configuration is something that comes out of the box, and is the setting which will be applied when the admin doesn’t customize anything. Org/team-level configuration allows admins to override the default out-of-the-box setting, and will be applied in cases when a connection-level setting does not exist. The diagram below describes the sequence in which settings are evaluated and applied.

We borrowed from the database schema of the approvals table, and created a new table with source and target team IDs, and a payload column. The table looked like this:
CREATE TABLE `slack_connect_prefs` (
`team_id` bigint unsigned NOT NULL,
`target_team_id` bigint unsigned NOT NULL,
`prefs` mediumblob NOT NULL,
`date_create` int unsigned NOT NULL,
`date_update` int unsigned NOT NULL,
PRIMARY KEY (`team_id`,`target_team_id`),
KEY `target_team_id` (`target_team_id`)
)We modeled org-level configuration by setting the target team as 0. Partner-level configuration had the team ID of the connection. We created an index on source and destination team IDs which allowed us to efficiently query the table. The table was also partitioned by source team ID, which means all rows belonging to the source team lived on the same shard. This is a common sharding strategy at Slack which allows us to scale horizontally. Instead of using a set of columns to model each setting, we opted to use a single column with a Protobuf blob as the payload. This allowed us to have complex data types per each setting, while also reducing DB storage needs and avoiding the 1,017 columns-per-table restriction. Here at Slack we have existing tooling for handling Protobuf messages, which makes it easy to operate on the blob columns inside the application code. The default configuration was implemented in application code by essentially hardcoding values.
Now that we had a solid storage layer, we had to build the application layer. We applied an existing Slack pattern of creating a Store class to handle all database interactions with a given table or a related set of tables. A store is a similar concept to a service in a microservices architecture. We created a SlackConnectPrefsStore class whose main job was to give clients a simple API for interacting with Slack Connect prefs. Under the hood, this involved reading from the database or cache, running validation logic, sending events and audit logs, and parsing Protobufs. The Protobuf definition looked like this, with the SlackConnectPrefs message being the container for all subsequent prefs:
message SlackConnectPrefs {
PrefOne pref_one = 1;
PrefTwo pref_two = 2;
...
}
message PrefOne {
bool value = 1;
}Our Store class supports get, set, remove, and list operations, and uses Memcached to reduce database calls when possible. The initial Store implementation was tightly coupled to the prefs it was operating on. For example, some prefs needed to send fanout messages to clients about a pref state change, so inside our set function we had a block like this:
function set(PrefContainer container) {
...
if (container.pref_one != null) {
send_fanout_message(container.pref_one);
}
...
}We had code blocks to handle transformation and validation for each pref, to bust cache, and for error handling. This pattern was unsustainable: the code grew very long, and making changes to a store function for a single pref carried a risk of breaking all prefs. The store design needed to evolve to have isolation between prefs, and to be easily and safely extendable for new prefs.
Evolution of the application layer
We had two competing ideas to handle the isolation and extendability problems. One option was to use code generation to handle the transformation, and possibly the validation tasks as well. The other option was to create wrapper classes around each pref Protobuf message and have the store delegate tasks to these classes. After some discussion and design doc reviews, our team decided to go with the wrapper class option. While code generation has extensive tooling, each pref was too different to specify as a code-generated template, and would still require developers to customize certain aspects related to the pref.
We modeled our class structure to reflect the Protobuf definition. We created a container class which was a registry of all supported prefs and delegated tasks to them. We created an abstract pref class with some common abstract methods like transform, isValid, and migrate. Finally, individual prefs would inherit from the abstract pref class and implement any required methods. The container class was created from a top-level Protobuf message, SlackConnectPrefs in the example above. The container then orchestrated creation of individual pref classes—PrefOne in the example above—by taking the relevant Protobuf sub messages and passing them to their respective classes. Each pref class knew how to handle its own sub message. The extensibility problem was solved, because each new pref had to implement its own class. The implementer did not need to have any knowledge of how the store works and could focus on coding up the abstract methods. To make that job even easier, our team invested in creating detailed documentation (and still continues to update it as the code evolves). Our aim is to make the Slack Connect prefs system self-serve, with little-to-no involvement from our team.
The final application layer looked something like this:
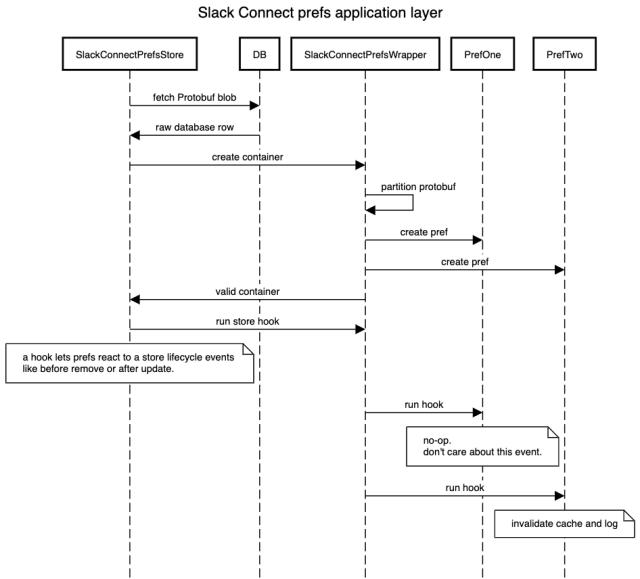
The isolation problem was partially solved by this design, but we needed an extra layer of protection to ensure that an exception in one pref did not interfere with others. This was handled at the container level. For example, when the Store needed to check that all messages in the Protobuf are valid, it would call containers isValid method. The container would then iterate through each pref and call the prefs isValid method, any exceptions would be caught and logged.
Simplifying administration at scale
So far, we have a solid database layer and a flexible application layer which can be plugged into places where we need to consume pref configuration. On the admin side, we have some dashboards which show information about external connections, pending invitations, and approvals. The APIs behind the dashboards had a common pattern of reading rows from multiple database tables, combining them together, and then applying search, sort, and filtering based on API request parameters.
This approach worked fine for several thousand external connections, but the latency kept creeping up, and the number of timeouts—and consequently triggered alerts—kept increasing. The admin dashboard APIs were making too many database requests, and the resulting data sets were unbounded in the number of rows. Adding caching helped to a degree, but as the number of connections kept going up, the existing sorting, filtering, and search functionality was not meeting user needs. Performance issues and lacking functionality led us to consider a different pattern for admin API handlers.
We quickly ruled out combining multiple database calls into a single SQL statement with many joins. While database-level join would have reduced the number of individual queries, the cost of doing a join over partitioned tables is high, and something we generally avoid at Slack. The database partitioning and performance of queries is its own topic, and is described in more detail in Scaling Datastores at Slack with Vitess.
Our other option was to denormalize the data into a single data store and query it. The debate was centered around which technology to use, with MySQL and Solr being the two options. Both of these options would require a mechanism to keep the denormalized view of the data in sync with the source of truth data. Solr required that we build an offline job which can rebuild the search index from scratch. MySQL guaranteed reading the data immediately after a write, while Solr had a five second delay. On the other hand, Solr documents are fully indexed, which gives us efficient sorting, filtering, and text search capabilities without the need to manually add indexes to support a given query. Solr also offers an easy query mechanism for array-based fields which are not supported in MySQL. Adding new fields to a Solr document is easier than adding a new column to a database table, should we ever need to expand the data set we operate on. After some internal discussions, we opted to go with the Solr option for its search capabilities. In the end it proved to be the right choice: we now have a dashboard which can scale to handle millions of external connections, while providing fast text-based searching and filtering. We also took advantage of the ability to dynamically add fields to a Solr document, which allowed for all newly created Slack Connect settings to be automatically indexed in Solr.
What will we build next?
The ability to have configuration per external connection has opened a lot of doors for us. Our existing permission and policy controls are not connection aware. Making permissions like WhoCanCreateSlackConnectChannels connection-aware can unlock a lot of growth potential. Our scaling work is never done and we will continue to have looming challenges to overcome when it comes to the number of connected teams and the number of connected external users.
If you found these technical challenges interesting, you can also join our network of employees at Slack!





