
Summary
In recent years, cellular architectures have become increasingly popular for large online services as a way to increase redundancy and limit the blast radius of site failures. In pursuit of these goals, we have migrated the most critical user-facing services at Slack from a monolithic to a cell-based architecture over the last 1.5 years. In this series of blog posts, we’ll discuss our reasons for embarking on this massive migration, illustrate the design of our cellular topology along with the engineering trade-offs we made along the way, and talk about our strategies for successfully shipping deep changes across many connected services.
Background: the incident
At Slack, we conduct an incident review after each notable service outage. Below is an excerpt from our internal report summarizing one such incident and our findings:
At 11:45am PDT on 2021-06-30, our cloud provider experienced a network disruption in one of several availability zones in our U.S. East Coast region, where the majority of Slack is hosted. A network link that connects one availability zone with several other availability zones containing Slack servers experienced intermittent faults, causing slowness and degraded connections between Slack servers and degrading service for Slack customers.
At 12:33pm PDT on 2021-06-30, the network link was automatically removed from service by our cloud provider, restoring full service to Slack customers. After a series of automated checks by our cloud provider, the network link entered service again.
At 5:22pm PDT on 2021-06-30, the same network link experienced the same intermittent faults. At 5:31pm PDT on 2021-06-30, the cloud provider permanently removed the network link from service, restoring full service to our customers.
At first glance, this appears to be pretty unremarkable; a piece of physical hardware upon which we were reliant failed, so we served some errors until it was removed from service. However, as we went through the reflective process of incident review, we were led to wonder why, in fact, this outage was visible to our users at all.
Slack operates a global, multi-regional edge network, but most of our core computational infrastructure resides in multiple Availability Zones within a single region, us-east-1. Availability Zones (AZs) are isolated datacenters within a single region; in addition to the physical isolation they offer, components of cloud services upon which we rely (virtualization, storage, networking, etc.) are blast-radius limited such that they should not fail simultaneously across multiple AZs. This enables builders of services hosted in the cloud (such as Slack) to architect services in such a way that the availability of the entire service in a region is greater than the availability of any one underlying AZ. So to restate the question above — why didn’t this strategy work out for us on June 30? Why did one failed AZ result in user-visible errors?
As it turns out, detecting failure in distributed systems is a hard problem. A single Slack API request from a user (for example, loading messages in a channel) may fan out into hundreds of RPCs to service backends, each of which must complete to return a correct response to the user. Our service frontends are continuously attempting to detect and exclude failed backends, but we’ve got to record some failures before we can exclude a failed server! To make things even harder, some of our key datastores (including our main datastore Vitess) offer strongly consistent semantics. This is enormously useful to us as application developers but also requires that there be a single backend available for any given write. If a shard primary is unavailable to an application frontend, writes to that shard will fail until the primary returns or a secondary is promoted to take its place.
We might class the outage above as a gray failure. In a gray failure, different components have different views of the availability of the system. In our incident, systems within the impacted AZ saw complete availability of backends within their AZ, but backends outside the AZ were unavailable, and vice versa systems in unimpacted AZs saw the impacted AZ as unavailable. Even clients within the same AZ would have different views of backends in the impacted AZ, depending on whether their network flows happened to traverse the failed equipment. Informally, it seems that this is quite a lot of complexity to ask a distributed system to deal with along the way to doing its real job of serving messages and cat GIFs to our customers.
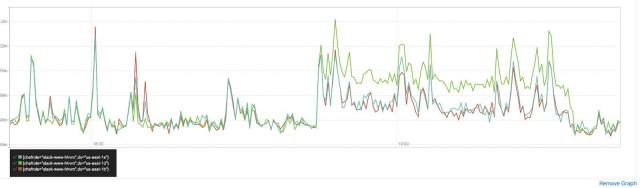
Rather than try to solve automatic remediation of gray failures, our solution to this conundrum was to make the computers’ job easier by tapping the power of human judgment. During the outage, it was quite clear to engineers responding that the impact was largely due to one AZ being unreachable — nearly every graph we had aggregated by target AZ looked similar to the retransmits graph above. If we had a button that told all our systems “This AZ is bad; avoid it.” we would absolutely have smashed it! So we set out to build a button that would drain traffic from an AZ.
Our solution: AZs are cells, and cells may be drained
Like a lot of satisfying infrastructure work, an AZ drain button is conceptually simple yet complicated in practice. The design goals we chose are:
- Remove as much traffic as possible from an AZ within 5 minutes. Slack’s 99.99% availability SLA allows us less than 1 hour per year of total unavailability, and so to support it effectively we need tools that work quickly.
- Drains must not result in user-visible errors. An important quality of draining is that it is a generic mitigation: as long as a failure is contained within a single AZ, a drain may be effectively used to mitigate even if the root cause is not yet understood. This lends itself to an experimental approach wherein, during in an incident, an operator may try draining an AZ to see if it enables recovery, then undrain if it does not. If draining results in additional errors this approach is not useful.
- Drains and undrains must be incremental. When undraining, an operator should be able to assign as little as 1% of traffic to an AZ to test whether it has truly recovered.
- The draining mechanism must not rely on resources in the AZ being drained. For example, it’s not OK to activate a drain by just SSHing to every server and forcing it to healthcheck down. This ensures that drains may be put in place even if an AZ is completely offline.
A naive implementation that fits these requirements would have us plumb a signal into each of our RPC clients that, when received, causes them to fail a specified percentage of traffic away from a particular AZ. This turns out to have a lot of complexity lurking within. Slack does not share a common codebase or even runtime; services in the user-facing request path are written in Hack, Go, Java, and C++. This would necessitate a separate implementation in each language. Beyond that concern, we support a number of internal service discovery interfaces including the Envoy xDS API, the Consul API, and even DNS. Notably, DNS does not offer an abstraction for something like an AZ or partial draining; clients expect to resolve a DNS address and receive a list of IPs and no more. Finally, we rely heavily on open-source systems like Vitess, for which code-level changes present an unpleasant choice between maintaining an internal fork and doing the additional work to get changes merged into upstream.
The main strategy we settled on is called siloing. Services may be said to be siloed if they only receive traffic from within their AZ and only send traffic upstream to servers in their AZ. The overall architectural effect of this is that each service appears to be N virtual services, one per AZ. Importantly, we may effectively remove traffic from all siloed services in an AZ simply by redirecting user requests away from that AZ. If no new requests from users are arriving in a siloed AZ, internal services in that AZ will naturally quiesce as they have no new work to do.
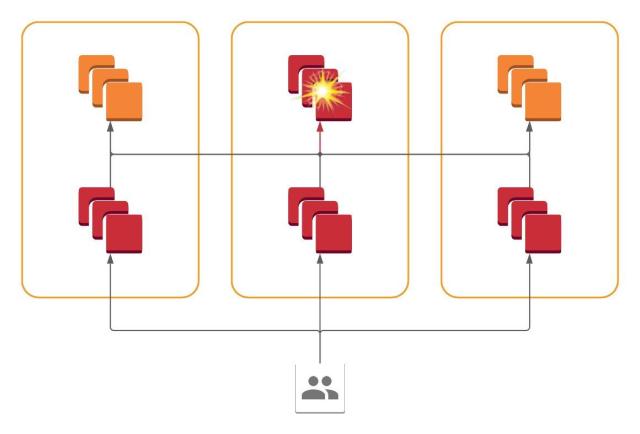
And so we finally arrive at our cellular architecture. All services are present in all AZs, but each service only communicates with services within its AZ. Failure of a system within one AZ is contained within that AZ, and we may dynamically route traffic away to avoid those failures simply by redirecting at the frontend.
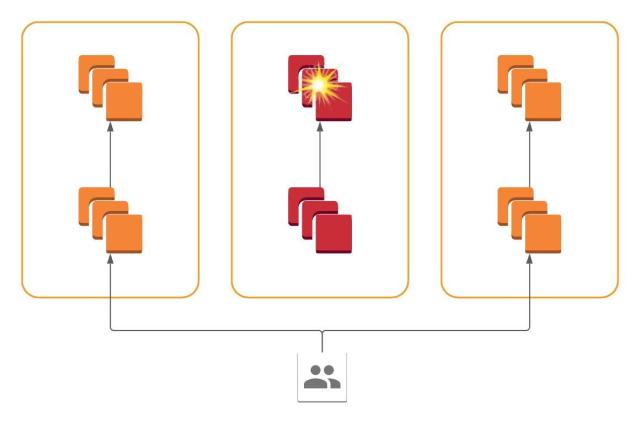
Siloing allows us to concentrate our efforts on the traffic-shifting implementation in one place: the systems that route queries from users into the core services in us-east-1. Over the last several years we have invested heavily in migrating from HAProxy to the Envoy / xDS ecosystem, and so all our edge load balancers are now running Envoy and receive configuration from Rotor, our in-house xDS control plane. This enabled us to power AZ draining by simply using two out-of-the-box Envoy features: weighted clusters and dynamic weight assignment via RTDS. When we drain an AZ, we simply send a signal through Rotor to the edge Envoy load balancers instructing them to reweight their per-AZ target clusters at us-east-1. If an AZ at us-east-1 is reweighted to zero, Envoy will continue handling in-flight requests but assign all new requests to another AZ, and thus the AZ is drained. Let’s see how this satisfies our goals:
- Propagation through the control plane is on the order of seconds; Envoy load balancers will apply new weights immediately.
- Drains are graceful; no queries to a drained AZ will be abandoned by the load balancing layer.
- Weights provide gradual drains with a granularity of 1%.
- Edge load balancers are located in different regions entirely, and the control plane is replicated regionally and resilient against the failure of any single AZ.
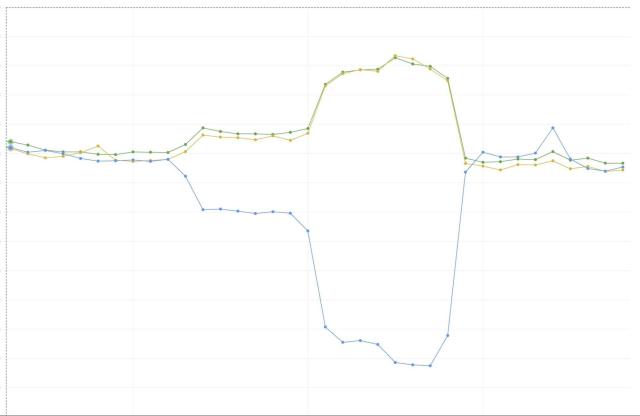
Here is a graph showing bandwidth per AZ as we gradually drain traffic from one AZ into two others. Note how pronounced the “knees” in the graph are; this reflects the low propagation time and high granularity afforded us by the Envoy/xDS implementation.
In our next post we’ll dive deeper into the details of our technical implementation. We’ll discuss how siloing is implemented for internal services, and which services can’t be siloed and what we do about them. We’ll also discuss how we’ve changed the way we operate and build services at Slack now that we have this powerful new tool at our disposal. Stay tuned!





