






Slack Data Engineering recently underwent data workload migration from AWS EMR 5 (Spark 2/Hive 2 processing engine) to EMR 6 (Spark 3 processing engine). In this blog, we will share our migration journey, challenges, and the performance gains we observed in the process. This blog aims to assist Data Engineers, Data Infrastructure Engineers, and Product Managers who may be considering migrating to EMR 6/Spark 3.
In Data Engineering, our primary objective is to support internal teams—such as Product Engineering, Machine Learning, and Data Science—by providing essential datasets and a reliable data infrastructure to facilitate the creation of their own datasets. We ensure the reliability and timeliness of critical billing and usage data for our clients. Maintaining Landing Time SLAs (Service Level Agreements) serves as a measure to keep up these promises.
Over time, the rapid expansion of our data volume frequently led to the violation of our critical data pipeline’s SLAs. As we sought alternatives to Spark 2 and Hive 2, Spark 3 emerged as a compelling solution for all our data processing needs, notably due to its Adaptive Query Execution (AQE) feature that could improve performance for some of our skewed datasets. We embarked on this EMR 6/Spark 3 migration due to enhanced performance, enhanced security—with updated log4j libraries—and the potential for significant cost savings.
This year-long project consisted of two major phases:
- Phase 1: Upgrade EMR from 5.3x to 6.x.
- Phase 2: Upgrade from Hive 2.x/Spark 2.x to Spark 3.x.
Migration journey

Current landscape
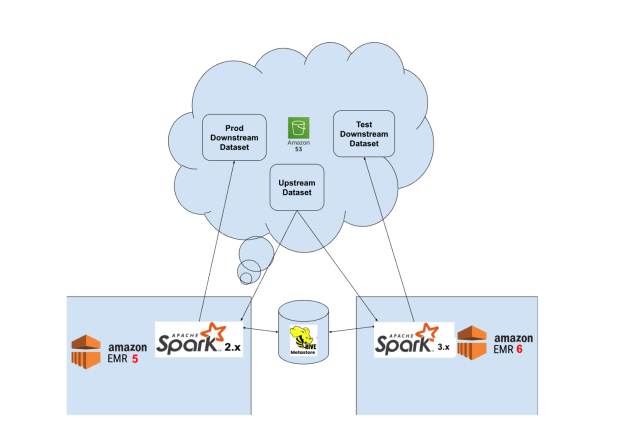
We at Slack Data Engineering use a federated AWS EMR cluster model to manage all data analytics requirements. The data that lives in the data warehouse is physically stored in S3 and its metadata is stored in Hive Metastore schema on an RDS database. SQL handles most of our use cases. Additionally, we rely on Scala/PySpark for certain complex workloads. We use Apache Airflow to orchestrate our workflows and have designed custom Spark Airflow operators for submitting SparkSQL, PySpark and Scala jobs to the EMR cluster via Livy Batches API using authenticated HTTP requests.
Here is an example of our hierarchical custom Airflow Spark operators:
BaseAirflowOperator → SparkBaseAirflowOperator → CustomPySparkAirflowOperator or CustomSparkSqlAirflowOperator
Here is an example of how we use CustomSparkSqlAirflowOperator to schedule Airflow task:

Below is a pictorial representation of all the components working together: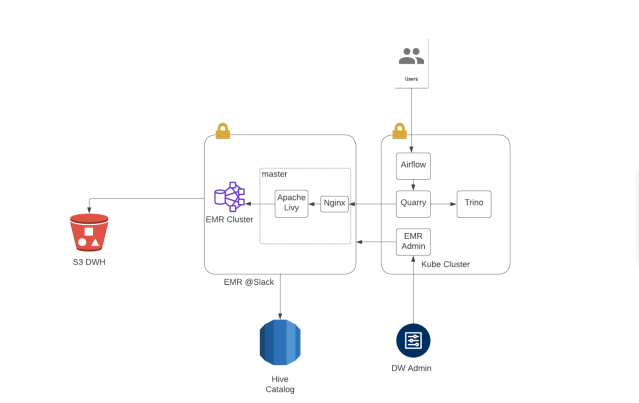
Our data warehouse infrastructure comprises over 60 EMR clusters, catering to the needs of over 40 teams and supporting thousands of Airflow Directed Acyclic Graphs (DAGs). Prior to this migration, all workloads were executed on EMR 5.36, Spark 2.4.8, and Hive 2.3.9.
Migration challenges
As the majority of our workloads were managed by Hive 2, making the transition to Hive 3 in EMR 6 was the preferred choice for our internal customers due to minimal changes required in the codebase. However, we opted to consolidate into a single compute engine, Spark 3. This strategic decision was made to leverage Spark 3 Adaptive Query Execution (AQE) feature, develop expertise in Spark 3 across our teams, and fine-tune Hadoop clusters exclusively for Spark operations for efficiency.
Given the scale of this migration, a phased approach was essential. Thus, we decided to support both AWS EMR 5 and EMR 6 versions until the migration was complete, allowing us to transition workloads without disrupting roadmaps for existing teams.
However, maintaining two different cluster settings (Hive 2.x/Spark 2.x in EMR 5.x and Spark 3.x in EMR 6) presented several challenges for us:
- How can we support the same Hive catalog across Spark 2/Spark 3 workloads?
- How can we provision different versions of EMR clusters?
- How can we control cost?
- How can we support different versions of our job libraries across these clusters?
- How can we submit and route jobs across these different versions of clusters?
Pre-migration planning
Hive catalog migration
How can we support the same Hive catalog across Spark 2/Spark 3 workloads?
We needed to use the same Hive Metastore catalog for our workloads across EMR 5/Spark 2 and EMR 6/Spark 3 as migration of our pipelines from Spark 2 to Spark 3 would take multiple quarters. We solved this problem by migrating our existing HMS 2.3.0 catalog to HMS 3.1.0 catalog, using Hive Schema Tool. We executed the following commands on the EMR 5 master host connected to the catalog database.
<img class="alignnone wp-image-16842" src="https://slack.engineering/wp-content/uploads/sites/7/2024/06/26.png?w=640" alt="" width="665" height="88" />
Before migration we took backups of our Hive Metastore database, and also took some downtime on job processing during migration for schema upgrade.
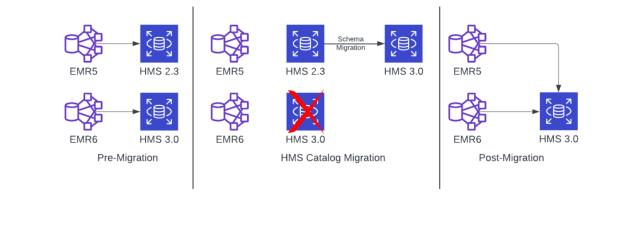
Post schema upgrade both our EMR 5 and EMR 6 clusters could talk to the same upgraded HMS 3 catalog DB as it was backward compatible with Hive 2 and Spark 2 applications.
EMR cluster provisioning
How can we provision different versions of EMR clusters? How can we control cost?
We use EMR’s golang SDK to launch EMR clusters via the RunJobFlow api. This API accepts a JSON-based launch configuration for an EMR cluster. We maintain a base JSON config for all clusters and override custom parameters like InstanceFleets, Capacity, and Release Label at the cluster configuration level. We created specific EMR 6 configurations for new EMR 6 clusters with auto-scaling enabled and low minimum capacity to keep costs under control. During the process of migration, we created more such EMR 6 cluster configurations for each new cluster. We regulated the capacity and overall cluster usage costs by gradually reducing EMR 5 fleet size and increasing EMR 6 fleets based on usage.
Job builds across different Spark versions
How can we support different versions of our job libraries across these clusters?
We use Bazel as the primary tool to build our codebase. Using Bazel, we implemented parallel build streams for Spark JARs across versions 2.x and 3.x. We propagated all ongoing config changes to both Spark 2 and Spark 3 JARs for consistency. Enabling the build --config=spark3 flag in the .bazelrc file allowed building local JARs with the required version for testing. In our airflow pipelines, as we migrated jobs to EMR 6, the airflow operator would pick Spark 3 jars automatically based on the flag approach described below.
Airflow operators enhancement
How can we submit and route jobs across these different versions of clusters?
We enhanced our custom Airflow Spark operator to route jobs to different versions of clusters by using a boolean flag. This flag offered the convenience of submitting jobs to either pre-migration and post-migration cluster by a simple toggle.
Additionally we introduced four logical groups of Spark config sizing options (SMALL, DEFAULT, LARGE and EXTRA_LARGE) embedded in the Airflow Spark operator. Each option has its own executor memory, driver memory, and executor ranges. Sizing options helped some of our end users to migrate existing Hive jobs with minimal understanding of Spark configurations.

This is an example of our enhanced CustomSparkSqlAirflowOperator:

Code changes
For most cases, the existing Hive and Spark 2 code ran fine in Spark 3. There were few cases where we had to make changes to the code to make it Spark 3 compatible.
One example of a code change from Hive to Spark 3 would be the use of a salting function for skewed joins. While some code used bulky subqueries to generate salt keys, others used RAND() in the joining key as a workaround for handling skew. While RAND() in the joining key works in Hive, it throws an error in Spark 3: org.apache.spark.sql.AnalysisException: nondeterministic expressions are only allowed in Project, Filter, Aggregate, or Window. We removed all skew-handling code and let Spark 3’s Adaptive Query Execution (AQE) take care of the data skew. More about AQE in the ‘Migration gain and impact’ section.
Additionally, Spark 3 threw errors for certain data type casting scenarios that worked well in Spark 2. We had to change the default value of a few Spark 3 configurations. One example is setting spark.sql.storeAssignmentPolicy to ‘Legacy’ instead of default Spark 3 value ‘ANSI’.
We faced a few instances where the Spark 3 job inferred the schema from the Hive Metastore but failed to consolidate schemas, erroring with java.lang.StackOverflowError. This occurred due to a lack of synchronization between the underlying Parquet data and the Hive metastore schema. By setting spark.sql.hive.convertMetastoreParquet to False, we successfully resolved the issue.
Post-migration data validation
We compared two tables:
- prod_table_hive2_or_spark2 (EMR 5 table)
- test_table_spark3 (EMR 6 table)
We aimed for an exact data match between the tables rather than relying on sampling, particularly because some of our data, such as customer billing data, is mission-critical.
We used config files and macros to enable our SQL script to read from the production schema and write to the test schema in the test environment. This helped us to populate the exact prod data in the test schema using Spark 3 for easy comparison. We then ran except and count SQL queries between prod_table_hive2_or_spark2 and test_table_spark3 in Trino to speed up the validation process.
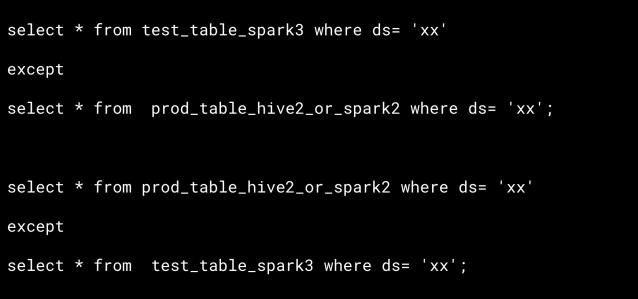
In case of mismatch in except or count query output, we used our in-house Python framework with the Trino engine for detailed analysis. We continuously monitored post migration production runtime of our pipelines using Airflow metadata DB tables and tuned pipelines as required.
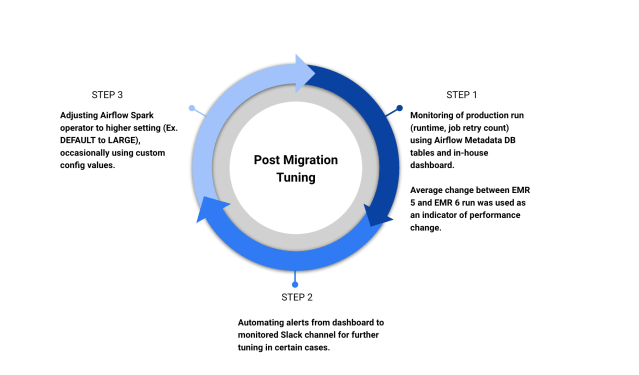
There were few sources of uncertainties in the validation process. For example:
- When the code relied on the current timestamp, it caused variations between production and development runs. We excluded timestamp related columns while validating those tables.
- Random rows appeared when there’s no differentiable
order byclause in the code to resolve ties. We fixed the code to have a differentiableorder byclause for future. - Discrepancies appeared in the behavior of certain built-in functions between Hive and Spark. For instance, functions like Greatest, which is used to return the greatest value of the list of arguments, exhibit different behavior when one of the arguments is
NULL. We made code changes to adhere to the correct business logic.
Migration gain and impact
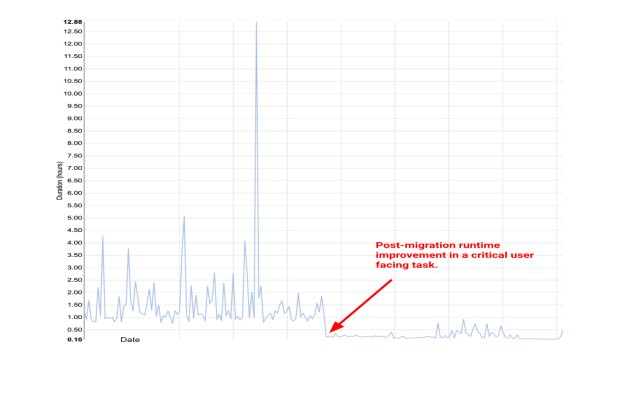
After migration, we observed substantial runtime performance improvements across the majority of our pipeline tasks. Most of our Airflow tasks showed improvements ranging from 30% to 60%, with some jobs experiencing an impressive 90% boost in runtime efficiency. We used Airflow metadata DB tables (duration column in task_instance table) to get runtime comparison numbers. Here is an example of how the runtime of one of our critical tasks improved significantly post migration:
EMR 6 EMRFS S3-optimized committer fixed the problem of incomplete writes and misleading SUCCESS statuses for some of our Spark jobs that handled text-based input and output format. It also improves application performance by avoiding list and rename operations done in S3 during job and task commit phases. Prior to EMR 6.4.0, this feature was only available for Apache Parquet file format. From EMR 6.4.0 it was extended to all common formats, including parquet, ORC, and text-based formats (including CSV and JSON).
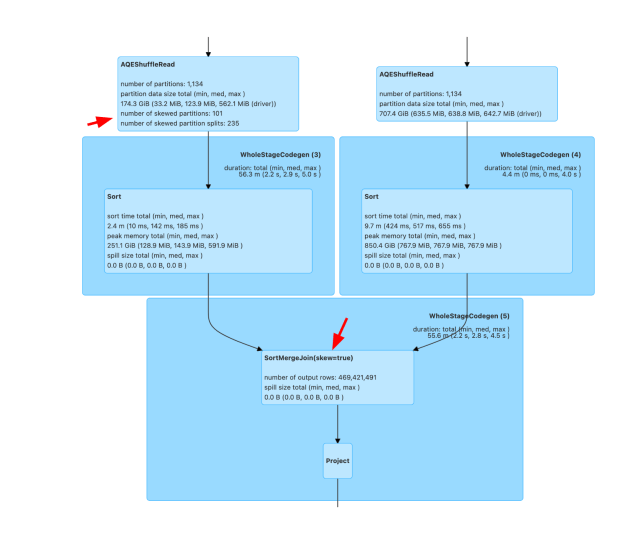
As expected, we noticed several Adaptive Query Execution(AQE) improvements in the query execution plan. One of the key improvements was dynamically optimizing skew join. This helped us to remove several lines of skew handling logic from our codebase and replace them by simple join condition between the keys. Below is an example which shows AQE (skew=true) hint in the query plan.
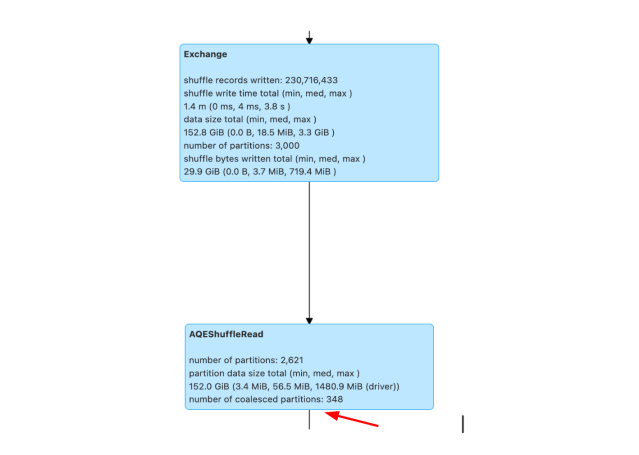
Another improvement was in dynamically coalescing shuffle partitions. This feature simplified the tuning of the shuffle partition number by selecting the correct shuffle partition number at runtime. We only had to provide a large enough initial shuffle partition number using spark.sql.adaptive.coalescePartitions.initialPartitionNum configuration. Below is a query plan which shows partition count going from 3000 to 348 using AQE.
Conclusion
The migration to EMR 6 has resulted in significant improvement in the runtime performance, efficiency, and reliability of our data processing pipelines.
AQE improvements, such as dynamically optimizing skew joins and coalescing shuffle partitions, have simplified query optimization and reduced the need for manual intervention in tuning parameters. S3-optimized committer has addressed issues related to incomplete writes and misleading statuses in Spark jobs, leading to improved stability. The entire process of migration described here ran quite smoothly and did not cause any incidents in any of the steps! We improved our pipeline codebase along the way, making it easier for new engineers to onboard on a clean foundation and work entirely off Spark 3 engine. The migration has also laid the foundation for a more scalable lakehouse with availability of modern table formats like Iceberg and Hudi in EMR 6. We recommend data organizations to invest in such long-term modernization projects as it brings efficiencies across the board.
Interested in joining our Data Engineering team?
Apply now




