


On September 30th 2021, Slack had an outage that impacted less than 1% of our online user base, and lasted for 24 hours. This outage was the result of our attempt to enable DNSSEC — an extension intended to secure the DNS protocol, required for FedRAMP Moderate — but which ultimately led to a series of unfortunate events.
The internet relies very heavily on the Domain Name System (DNS) protocol. DNS is like a phone book for the entire internet. Web sites are accessed through domain names, but web browsers interact using IP addresses. DNS translates domain names to IP addresses, so that browsers can load the sites you need. Refer to ‘What is DNS?’ by Cloudflare to read more about how DNS works and all the necessary steps to do a domain name lookup.

DNS as a protocol is insecure by default, and anyone in transit between the client and the authoritative DNS name server for a given domain name can tamper with the response, directing the client elsewhere. DNS has a security extension commonly referred to as DNSSEC, which prevents tampering with responses between the authoritative DNS server of the domain name (i.e. slack.com.) and the client’s DNS recursive resolver of choice. DNSSEC will not protect the last mile of DNS — which is the communication between the client and their DNS recursor — from a MiTM attack. While we are aware of the debate around the utility of DNSSEC among the DNS community, we are still committed to securing Slack for our customers.
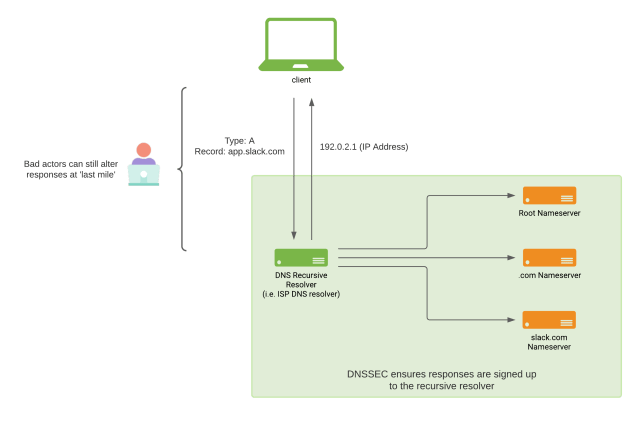
At Slack, we use Amazon Route 53 as our authoritative DNS server for all our public domains, delegating some subzones to NS1. We do this to make use of NS1’s advanced traffic management features. All these zones are operated by the Traffic Engineering team at Slack.
For the last four months, the team has been working on enabling DNSSEC signing on all domains used by Slack. At the time of the incident, all critical Slack domains, other than slack.com, already had DNSSEC enabled for at least one month.
By design, DNSSEC can only be enabled on a per-domain basis, making it impossible to enable DNSSEC per subdomain (i.e. example.slack.com) or subzone (i.e. wss-backup.slack.com, which is delegated from the slack.com Route53 zone to NS1). This design choice significantly increases the risk of DNSSEC rollouts.
Accordingly, we were careful about testing that our domains were still resolving correctly. For each domain that we enabled DNSSEC on we did the following validation:
- We created external monitoring and alerting for DNS and DNSSEC resolution from multiple locations around the globe using many resolvers (including Cloudflare, Comodo, Google, OpenDNS, Quad9, and Verisign).
- We created multiple dnsviz.net and Verisign DNSSEC Debugger tests to make sure that our zones were set up correctly, and that the chain of trust between authoritative and delegated zones was successful.
- We created multiple dnschecker.org tests to ensure resolution against slack.com and it’s sub-delegated records resolved as expected after applying the zone changes.
- We created several hand-crafted dig tests using multiple resolvers.
Prior to enabling DNSSEC for slack.com, we rolled out DNSSEC to all other Slack public domains successfully, with no internal or customer impact. The incident on September 30th 2021 was the third unsuccessful attempt to enable DNSSEC on slack.com.
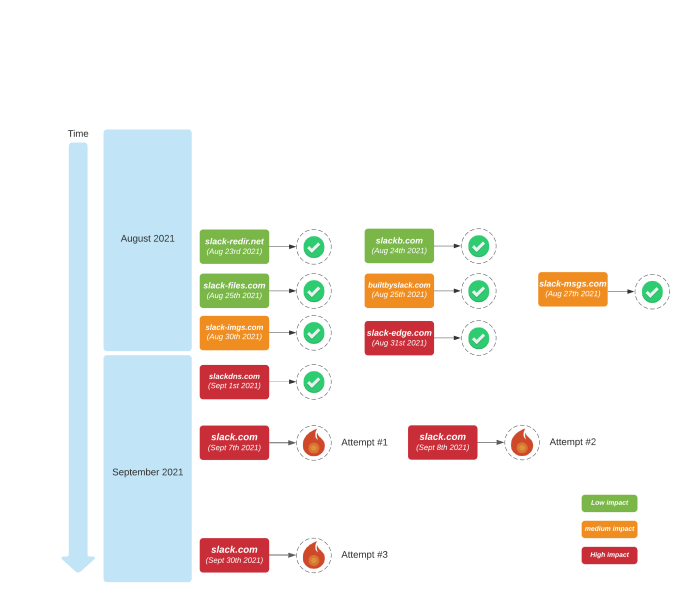
Unsuccessful attempt one 😟
On September 7th, 2021, we enabled DNSSEC signing on slack.com. However, prior to publishing the DS record at our DNS registrar, a large ISP in the US had an outage and many of our customers reported being unable to access Slack as a result. Early in that incident — before we were aware of the ISP issue — the slack.com zone changes were rolled back as a precaution.
Unsuccessful attempt two 😢
On September 8th, 2021, we enabled DNSSEC signing on slack.com following the same procedure as on our previous attempt. Prior to publishing the DS record at the DNS registrar, our Customer Experience team noticed a small number of users reporting DNS resolution problems. Most of the affected users were accessing Slack through a VPN provider.
It turned out that some resolvers become more strict when DNSSEC signing is enabled at the authoritative name servers, even while signing was not enabled at the root name servers (i.e. before DS records were published to COM nameservers). This strict DNS spec enforcement will reject a CNAME record at the apex of a zone (as per RFC-2181), including the APEX of a sub-delegated subdomain. This was the reason that customers using VPN providers were disproportionately affected — many VPN providers use resolvers with this behavior.
We stopped signing the slack.com zone in Route53 and NS1. Shortly afterwards, this fixed the DNS resolution issues for users that had reported problems. After this attempt, our sub-delegated zones were updated to ALIAS records.
Unsuccessful attempt three 😭
On September 30th 2021 and after careful planning, the Traffic Engineering team made their third attempt to enable DNSSEC signing on slack.com. We started by enabling DNSSEC signing on all NS1 slack.com sub-delegated zones and the Route53 authoritative zone for slack.com, which also provisioned the necessary DS records from the delegated zones to maintain chain of trust between Authoritative and delegated zones.
Immediately after, we followed all the validation steps listed above to ensure that slack.com was still resolving correctly.
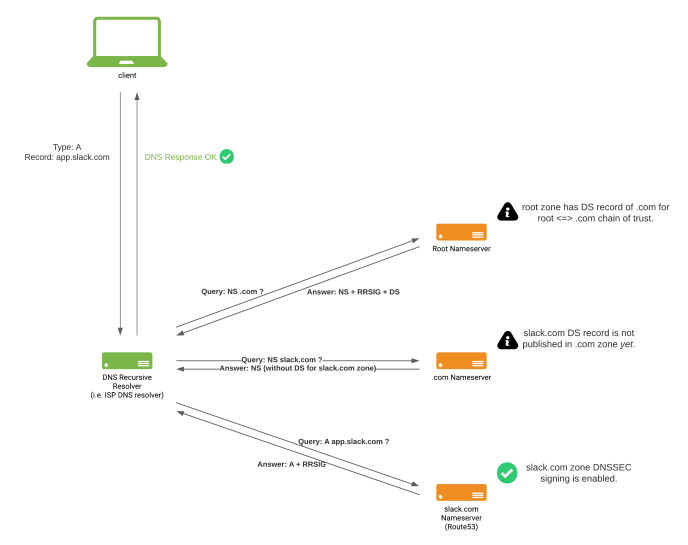 State of slack.com DNS when DNSSEC signing was enabled at slack.com zone, but not yet published DS record at .com zone.
State of slack.com DNS when DNSSEC signing was enabled at slack.com zone, but not yet published DS record at .com zone.
After a three hour ‘soak time’ and successful validations, we were confident to publish the slack.com DS record at the DNS registrar, which instructed DNSSEC validating resolvers to start validating DNS requests for slack.com (unless the cd flag is specified).
After publishing the DS record at the DNS registrar, we ran the same validation steps again and confirmed everything was working as intended. Our DNS resolution monitoring that enforced DNSSEC checking corroborated a successful rollout.
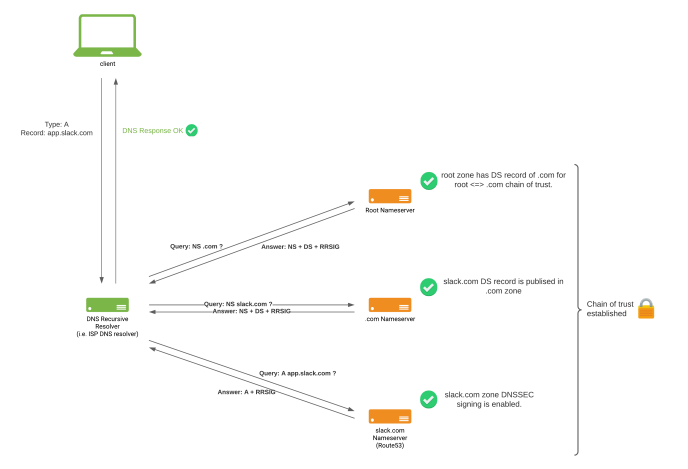 State of slack.com DNS chain after DNSSEC was fully enabled.
State of slack.com DNS chain after DNSSEC was fully enabled.
Our DNSSEC probes went green after publishing the DS record at the DNS registrar as well. Success!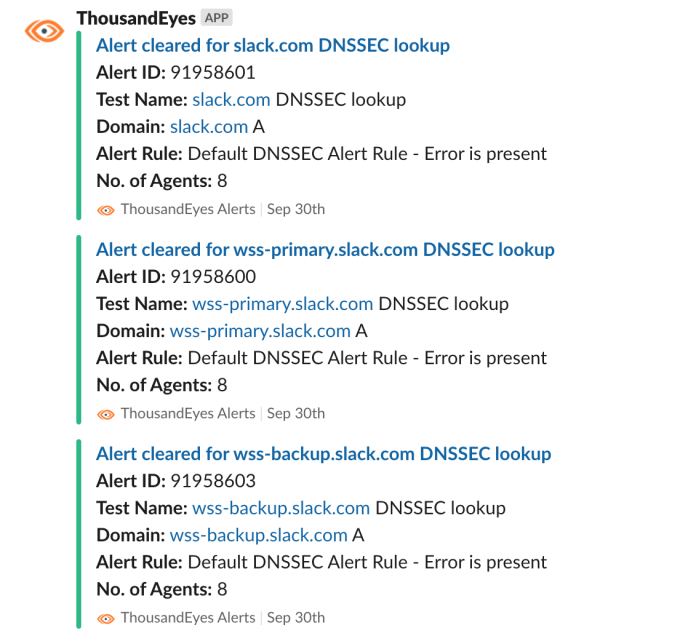
Soon afterwards, Customer Experience started getting reports from users seeing “ERR_NAME_NOT_RESOLVED” errors in Slack clients. Slack applications are based on Chromium and integrate a way to export a NetLog capture, which is incredibly helpful when debugging network problems and analyzing performance. NetLogs are extensively used by Customer Experience and Engineering at Slack.
‘ERR_NAME_NOT_RESOLVED’ type errors can have multiple causes. In this specific case, it was caused by NODATA DNS responses from some DNS recursive resolvers. Our engineering teams started to investigate.
During our initial investigation we saw most reports were from a private (corporate) DNS recursive resolver and Google’s Public Resolver (8.8.8.8). This was surprising, as impact to Google DNS should mean a much larger impact than our monitoring and customer reports indicated.
At this point we decided to pull the DS record from the DNS registrar, effectively removing the slack.com DS record at the ‘.com.’ zone to ‘stop the bleeding’, and later focus on the ‘NODATA’ DNS responses reported by customers.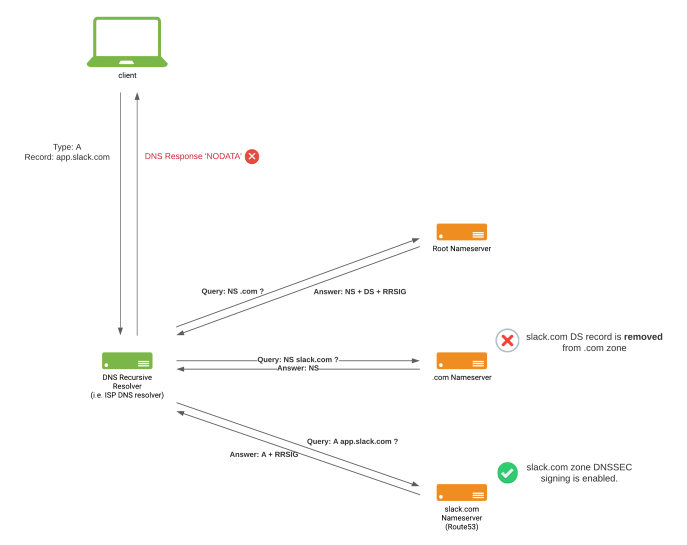 State of Slack.com DNS after removing the slack.com DS record from the .com zone
State of Slack.com DNS after removing the slack.com DS record from the .com zone
After nearly an hour, there were no signs of improvement and error rates remained stable, trending neither upwards nor downwards.
Our Traffic team was confident that reverting the DS record published in MarkMonitor was sufficient to eventually resolve DNS resolution problems. As things were not getting any better, and given the severity of the incident, we decided to rollback DNSSEC signing in our slack.com authoritative and delegated zones, wanting to recover our DNS configuration to the last previous healthy state, allowing us to completely rule out DNSSEC as a problem.
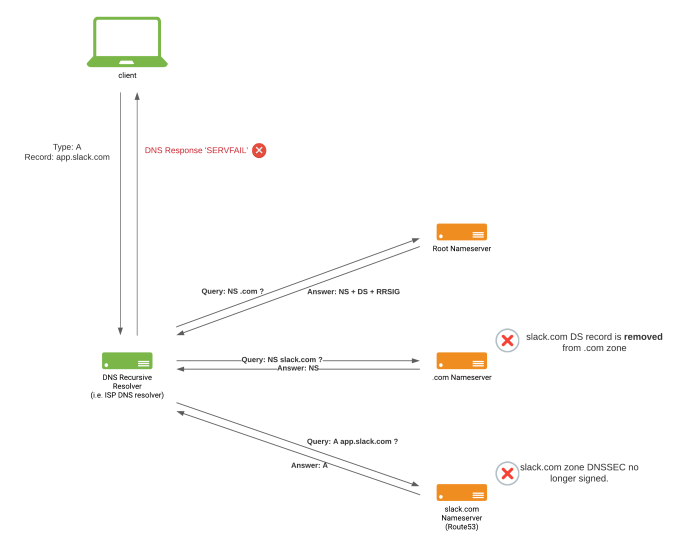 State of slack.com DNS after un-signing DNSSEC at slack.com zone
State of slack.com DNS after un-signing DNSSEC at slack.com zone
As soon as the rollback was pushed out things got much worse; our Traffic team was paged due to DNS resolution issues for slack.com from multiple resolvers across the world.
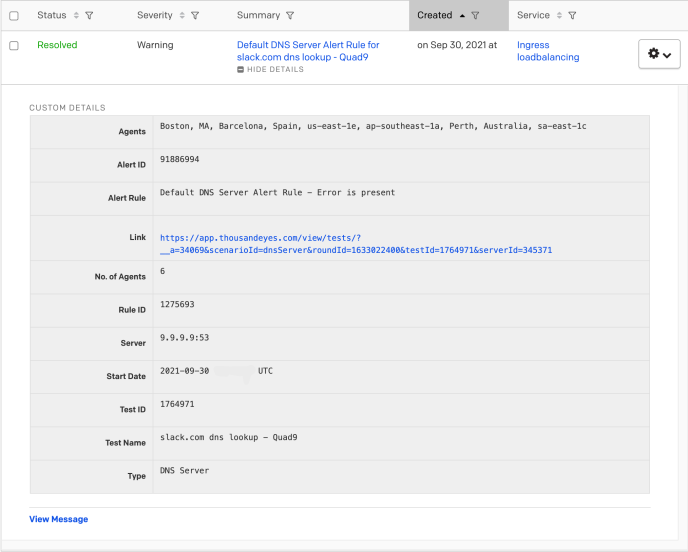 Example DNS resolution alert for 9.9.9.9 DNS resolver received by our Traffic team after the rollback.
Example DNS resolution alert for 9.9.9.9 DNS resolver received by our Traffic team after the rollback.
Based on expert advice, our understanding at the time was that DS records at the .com zone were never cached, so pulling it from the registrar would cause resolvers to immediately stop performing DNSSEC validation. This assumption turned out to be untrue. The ‘.com.’ zone will ask resolvers to cache the slack.com DS record for 24h by default (non modifiable by zone owners). Luckily, some resolvers cap that TTL with a lower value (i.e. Google’s 8.8.8.8 has a 6h TTL on DS records).
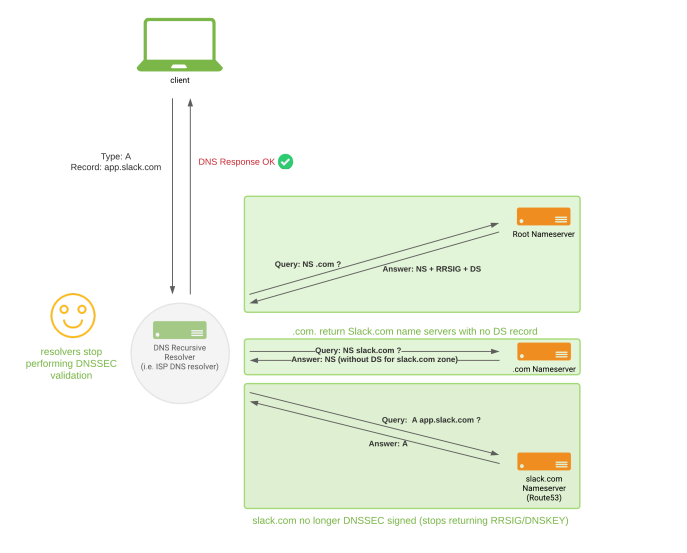 How we thought recursive resolvers would behave after disabling DNSSEC signing in slack.com zone
How we thought recursive resolvers would behave after disabling DNSSEC signing in slack.com zone
The team knew removing the DNSKEY from the authoritative zone is a high-risk operation unless the DS record is not published anymore. However, the assumption of no cached DS records at the ‘.com.’ zone made us believe we were in the same state as in the previous two rollbacks, and that the result would be the same. However, unlike with our previous attempt, this time resolvers had cached DS records with up to 24 TTL remaining.
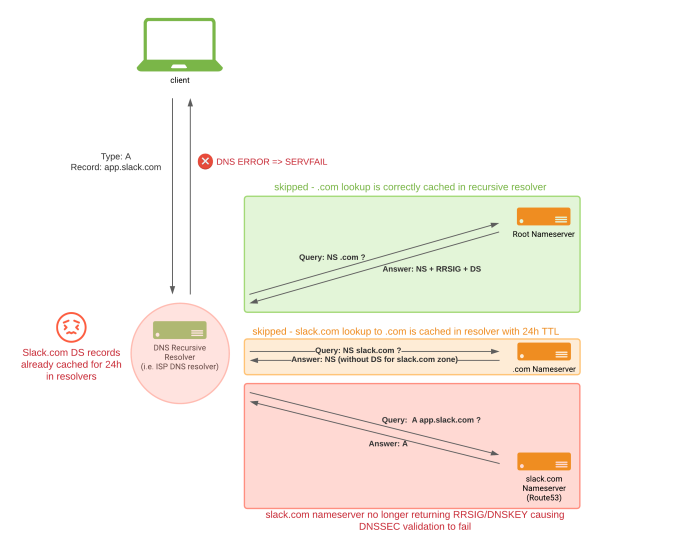 How recursive resolvers actually behaved: they had cached the slack.com DS record for 24h. DNSSEC validations started to fail after disabling signing on slack.com zone.
How recursive resolvers actually behaved: they had cached the slack.com DS record for 24h. DNSSEC validations started to fail after disabling signing on slack.com zone.
All our DNS configuration is managed in Terraform. Terraform is great for managing infrastructure as code, but in this case it made us miss a critical warning when trying to disable DNSSEC signing in Route53:
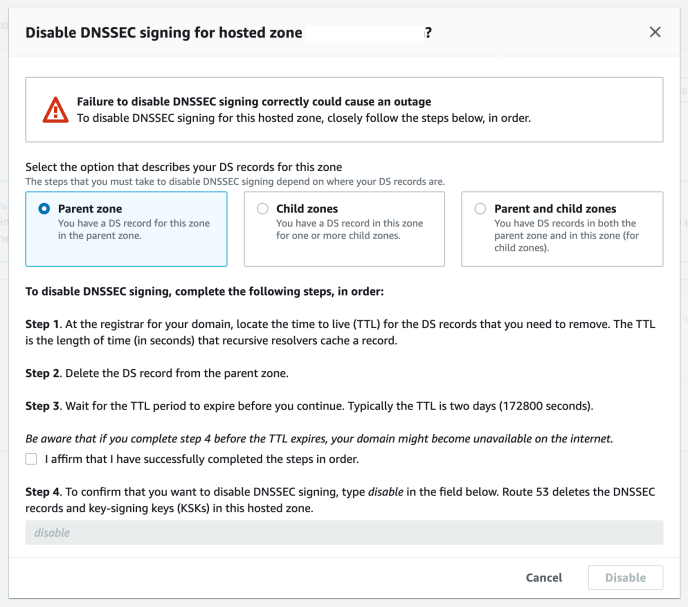 Disable DNSSEC warning window in Route53 Console.
Disable DNSSEC warning window in Route53 Console.
Once the rollback was complete, all DNSSEC validating resolvers that had recently cached the DS record for slack.com started returning a SERVFAIL on all slack.com lookups. We were immediately alerted by our external monitoring on DNS/DNSSEC resolution probes.
Our team quickly started contacting major ISPs and operators that run public DNS resolvers, with the request to flush all cached records for slack.com. Additionally, we flushed caches for resolvers that offer a public site (i.e. Google’s 8.8.8.8 and Cloudflare’s 1.1.1.1).
As resolvers flushed their caches, we slowly saw signs of improvement on our internal monitoring. Slack clients send telemetry to slackb.com and thanks to this isolation, we were still able to receive client metrics that helped us quantify the impact of this outage. Ironically, slackb.com had DNSSEC enabled successfully prior to this incident.
Throughout the incident, we considered re-signing DNSSEC on the slack.com zone (without publishing the DS at the DNS registrar). Restoring the DNSKEY would slightly improve the situation for some users, but it would not have solved the issue with all users that were initially getting ‘NODATA’ on their responses after DNSSEC signing was enabled. With hindsight this might have been better, but at this point we still did not understand the root cause of the original ‘NODATA’ responses.
For us to restore signing, we would have had to recover some keys which had been deleted when we rolled back the changes to the slack.com zone. In Route53 the DNSSEC KSK (Key Signing Key) is managed via an AWS KMS key. The KMS key was recoverable as per our configuration and the KSK was going to be the same, but we were uncertain if the ZSK (Zone Signing Key) would have been the same or different, as the ZSK is fully managed by AWS and we have no visibility into it. After the incident, Amazon’s Route53 team confirmed that the ZSK would have been different. When re-enabling signing on a zone, the ZSK will be generated with a new key pair. The Route53 team intends to design a mechanism for customers to quickly recover from this situation in the future.
At this point, some hours into the incident, we were in a situation where Slack was resolving correctly for the vast majority of customers, but a long tail of users of smaller DNS resolvers — which had not flushed the slack.com records — were still impacted.
We decided not to restore signing due to a lack of confidence. At the time, our understanding was that the DS record TTL might have been set by the slack.com zone in Route53, so a failed attempt to re-enable signing on the zone would ‘reset the clock’ on the DS record TTL, so we would have to request flushing of the slack.com DNS records for a second time and prolong the impact of the incident.
We know now signing a zone has no impact on the DS record TTL as it comes from the .com zone directly. Re-enabling signing would have had no impact as the ZSK would be different, so all DNSSEC validating resolvers would have continued failing to validate. So this action would have neither made things better nor made them worse.
As public resolver caches were flushed and as the 24h TTL on the DS record at the ‘.com’ zone expired, the error rates went back to normal.
Solving the mystery 🕵️
Once impact to Slack customers was mitigated, we aimed to determine the root cause of this outage. Prior to attempting DNSSEC on slack.com, our team had successfully enabled DNSSEC on all other Slack public domains. So how was slack.com different? Why had we not seen issues with any of the previous domains? Why did it only impact some corporate internal DNS resolvers and some of Google’s Public DNS lookups, but not all?
To understand what had happened, we replicated the rollout steps using a test zone setup identical to slack.com and used a resolver that we knew had problems during the rollout. Surprisingly, all our attempts to reproduce the behavior were unsuccessful.
At this point we went back to the NetLogs that we had received from customers during the outage.
| Side Note: How do we get access to NetLogs from our customers? These were voluntarily provided by some customers after they opened support cases during this incident, so a huge thank you to those of you that did that! It really helps us out when debugging incidents like this one. |
This is where we found an extremely interesting clue: clients were able to resolve slack.com successfully but failed to resolve app.slack.com. Why?
The following screenshot shows an attempt to resolve the slack.com domain successfully at “At 12:32:59.120”: 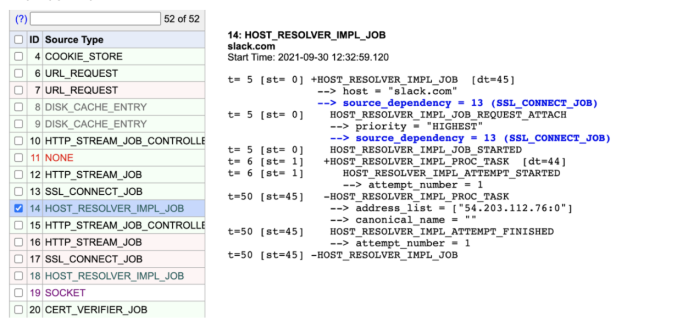
One microsecond later, app.slack.com fails to resolve with a ‘ERR_NAME_NOT_RESOLVED’ error:
This indicated there was likely a problem with the ‘*.slack.com’ wildcard record since we didn’t have a wildcard record in any of the other domains where we had rolled out DNSSEC on. Yes, it was an oversight that we did not test a domain with a wildcard record before attempting slack.com — learn from our mistakes!
We collected evidence and reached out to the Amazon Route 53 team, who jumped on a call with us to figure it out. After walking them through the evidence we had, they quickly correlated this behavior to an issue with NSEC responses that Route 53 generated on wildcard records. Aha! 💡
When a request is made to a DNSSEC-enabled domain for a wildcard record which type does not exist, the answer is a signed NSEC record confirming that while the domain name exists, the requested type does not. This signed NSEC response can include some additional information (specifically designed to keep wildcard records from breaking, among other things), but Route53 was not returning this additional information.
What this means is that a request for a record at the same level, say an AAAA lookup for app.slack.com would correctly return a signed NSEC saying “there is no record for that”. This is correct since we don’t publish any AAAA records. The expected client behaviour is to fall back to requesting an A record. BUT — since Route53 isn’t returning that extra information — some public resolvers (including Google Public DNS, 8.8.8.8) take that response to mean that nothing exists at that level so there’s no need to query for an A record.
This NSEC response is cached. This effectively meant that impacted DNS resolvers were unintentionally being “cache poisoned” (by clients innocently checking for the existence of AAAA records) when DNSSEC was enabled in a Route53 zone with a wildcard record. Luckily, this cache poisoning would only affect the regional cache. This meant that one regional cache backing a larger impacted resolver could be temporarily poisoned, and anyone else hitting that same cache would see the failure, but those hitting other regional caches on the same resolver would not.
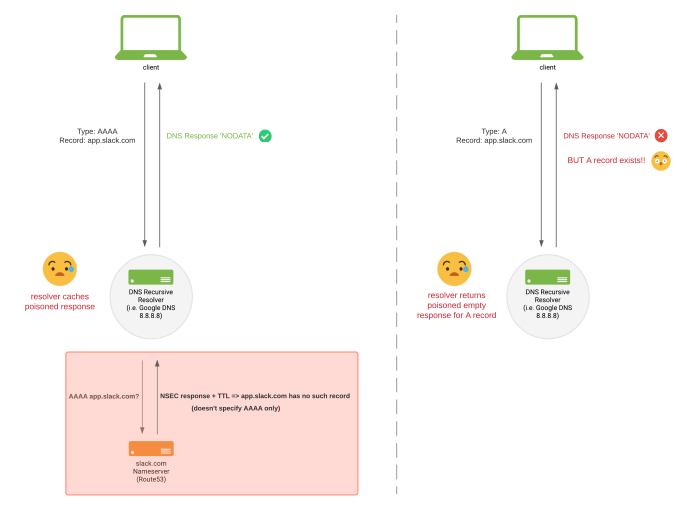 Recursive resolvers caches are poisoned by incorrect NSEC response from Route53.
Recursive resolvers caches are poisoned by incorrect NSEC response from Route53.
Interestingly, at this point we were able to reproduce this issue with our DNSSEC-enabled test zone against Google Public DNS (8.8.8.8) but not against Cloudflare Public DNS (1.1.1.1). A second mystery was whether or not one of these major public resolvers was out of spec. We investigated this and decided it is protocol compliant to reuse a cached NSEC record to decide a subsequent response. In fact, that’s what Aggressive NSEC (RFC 8198) does, an optional spec, which Google implements. Some implementations only infer non-existence of “names” within the NSEC span. Some also do RR “type” inference from the NSEC-type bitmap. It seems that Google does both and perhaps Cloudflare does neither (or only the first). In the end we concluded that both options were “acceptable” and the only real way to avoid being in this ambiguous situation is for your Authoritative Nameserver to correctly return existing record types in the NSEC type bitmap (which was exactly what the AWS Route53 team was fixing).
Lookup of existing A wildcard record ‘*.slackexperts.com‘:
dig A qqq.slackexperts.com @8.8.8.8 +dnssec ; <<>> DiG 9.10.6 <<>> A qqq.slackexperts.com @8.8.8.8 +dnssec ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 48704 ;; flags: qr rd ra ad; QUERY: 1, ANSWER: 2, AUTHORITY: 0, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 512 ;; QUESTION SECTION: ;qqq.slackexperts.com. IN A ;; ANSWER SECTION: qqq.slackexperts.com. 300 IN A 54.211.89.16 qqq.slackexperts.com. 300 IN RRSIG A 13 3 300 20211105130720 20211105110220 28453 slackexperts.com. zksghNF9JTx4mRXjkoEGP6C5zCPb5JjX2MzeihENzx3JIjnZLZyokvdd /dnxcA5Qjl3sc3eC0bkryoGATb4ghw== ;; Query time: 66 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Wed Oct 13 15:40:32 EDT 2021 ;; MSG SIZE rcvd: 177
Lookup of non existent AAAA wildcard record ‘*.slackexperts.com’ – no A specified in NSEC response:
dig AAAA qqq.slackexperts.com @8.8.8.8 +dnssec ; <<>> DiG 9.10.6 <<>> AAAA qqq.slackexperts.com @8.8.8.8 +dnssec ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 63101 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 512 ;; QUESTION SECTION: ;qqq.slackexperts.com. IN AAAA ;; AUTHORITY SECTION: slackexperts.com. 2370 IN SOA ns-869.awsdns-44.net. awsdns-hostmaster.amazon.com. 1 7200 900 1209600 86400 slackexperts.com. 2370 IN RRSIG SOA 13 2 900 20211013205618 20211013184118 30624 slackexperts.com. iBn8JmsuVq+F5zD+cm6C1Ypr25TtpKAIduCUZ80+sbuCbMQh0beC7RFc 2MctSnC9tf1RuCQHUxa/sEVVyHw6xQ== qqq.slackexperts.com. 2370 IN NSEC \000.qqq.slackexperts.com. RRSIG NSEC qqq.slackexperts.com. 2370 IN RRSIG NSEC 13 3 86400 20211014204118 20211013184118 30624 slackexperts.com. yB7d/Fl15M0z6zEHuE4XDvdxBT91DPiV38vhvI/42piqA1YI9ibb178E X0L82AaIaxcvSXKsdrWD8bAxJGVVyw== ;; Query time: 40 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Wed Oct 13 15:41:47 EDT 2021 ;; MSG SIZE rcvd: 398
Lookup of existing A wildcard record after cache is poisoned (no ANSWER SECTION – It’s empty!):
dig A qqq.slackexperts.com @8.8.8.8 +dnssec ; <<>> DiG 9.10.6 <<>> A qqq.slackexperts.com @8.8.8.8 +dnssec ;; global options: +cmd ;; Got answer: ;; ->>HEADER<<- opcode: QUERY, status: NOERROR, id: 17738 ;; flags: qr rd ra; QUERY: 1, ANSWER: 0, AUTHORITY: 4, ADDITIONAL: 1 ;; OPT PSEUDOSECTION: ; EDNS: version: 0, flags: do; udp: 512 ;; QUESTION SECTION: ;qqq.slackexperts.com. IN A ;; AUTHORITY SECTION: slackexperts.com. 2382 IN SOA ns-869.awsdns-44.net. awsdns-hostmaster.amazon.com. 1 7200 900 1209600 86400 slackexperts.com. 2382 IN RRSIG SOA 13 2 900 20211013205618 20211013184118 30624 slackexperts.com. iBn8JmsuVq+F5zD+cm6C1Ypr25TtpKAIduCUZ80+sbuCbMQh0beC7RFc 2MctSnC9tf1RuCQHUxa/sEVVyHw6xQ== qqq.slackexperts.com. 2382 IN NSEC \000.qqq.slackexperts.com. RRSIG NSEC qqq.slackexperts.com. 2382 IN RRSIG NSEC 13 3 86400 20211014204118 20211013184118 30624 slackexperts.com. yB7d/Fl15M0z6zEHuE4XDvdxBT91DPiV38vhvI/42piqA1YI9ibb178E X0L82AaIaxcvSXKsdrWD8bAxJGVVyw== ;; Query time: 10 msec ;; SERVER: 8.8.8.8#53(8.8.8.8) ;; WHEN: Wed Oct 13 15:42:12 EDT 2021 ;; MSG SIZE rcvd: 398
Ta-da! 🎉
Our mystery was definitively solved. At the time of the writing of this blog post, the Route53 team has rolled out a fix to the NSEC-type bug described above.
We are very sorry for the impact this outage had on everyone who uses Slack and hope that this write-up will shed some light on some of the corner cases with DNSSEC (circa 2021). Maybe, just maybe, this will prevent someone else from having a similar issue.
Acknowledgements 🙏
We’d like to thank the Amazon Route 53 team for confirming the issue and for their rapid fix, Salesforce DNS team for their kindness, support, and DNSSEC expertise, and all of the DNS community for their invaluable help in rapidly flushing caches to bring Slack back to everyone affected by this problem. Last but not least, a huge thank you to our Customer Experience team, who are the ones on the front lines every day, connecting the dots between our customers and our engineering teams — we could not have done it without you! 🌟





