


In 2021, we changed developer testing workflows for Webapp, Slack’s main monorepo, from predominantly testing before merging to a multi-tiered testing workflow after merging. This changed our previous definition of safety and developer workflows between testing and deploys. In this project, we aimed to ensure frequent, reliable, and high-quality releases to our customers for a simpler, more pleasant, and more productive Slack experience.
What happens when you discover that a one-line code change results in thousands of tests running in your pull request? And many of these tests are frustratingly flaky end-to-end tests executing complex workflows not related to your change? How do you refactor a development workflow consisting primarily of end-to-end tests, safely?
Slack engineers began asking these questions due to rising frustration over several years in Webapp, Slack’s main monorepo, where many engineers spend their time. Webapp contains the core application that powers the Slack user experiences of the backend API and asynchronous job queue written in Hacklang, and frontend client written in Typescript.
In 2020, Slack’s developer productivity metrics on velocity provided data for those frustrations:
- Test turnaround time (p95) was consistently above 30 minutes for individual commits. This measures the time between an engineer pushing a commit to our code repository and test executions completing.
- Test flakiness per pull request (PR) was consistently around 50%. This measures the percentage of any single flaky test—where re-running the same code results in a different result—across all commits in a PR.
In early 2021, engineers across multiple teams initiated a project to answer these questions by transforming our testing pipelines. This article shares how we designed a series of technical and social changes to make testing at Slack easier, faster, and more reliable. By using separate pipelines and contextual alerting, engineering velocity for Webapp improved significantly without compromising safety.
- Test turnaround time (p95) decreased over 40%. Today, this metric is consistently below 18 minutes and significantly more predictable.
- Test flakiness per PR decreased significantly by over 90%. Today, this metric is consistently less than 5%.
- There was no measurable increased rate of defects (measured by customer reports).
Problem statement
In the Core Development Engineering department, we provide developers with the ability to build, test, deploy, and release changes safely and efficiently, all while ensuring our users have a great experience using Slack.
Our group focuses on how to best scale infrastructure and human workflows for testing in Continuous Integration (CI) / Continuous Deployment (CD).
Slack introduced automated testing in 2017 for the Webapp repo. For three years, test execution count grew 10% month over month for this codebase. One way Slack engineers ensured code quality was by running most tests pre-merge in the CI workflow—that is, upon pushing commits, their changes would be tested by merging with mainline. If any one of these tests failed, developers would be unable to merge; these were referred to as blocking tests. After all tests passed and the code was reviewed, a developer could merge their PR. After merging, one last set of tests would run in the CD workflow, which tested basic functionality of Slack (e.g. sending a message).
At peak in 2020, we were executing one million test suites a day with up to 40,000 tests per suite. Also in 2020, most of these tests were executed before merging to mainline, and most of these tests were end-to-end tests. Since end-to-end test suites relied on many different moving parts across our CI infrastructure, they could sometimes be flaky, meaning they sometimes failed to produce the same result on the same code being tested. These end-to-end test suites could be flaky for a number of reasons:
- The tests themselves
- The test-running framework, e.g. automated tests could time out due to issues in the platform itself (too many retries lead to a timeout)
- The application or system under test (SUT) and the services and libraries that the SUT and testing framework depend upon, e.g. Cypress.io is not available
- The OS and hardware and network that the SUT and testing framework depend upon, e.g. DNS outages
Almost all testing is automated for the Webapp repo. Product and test engineers are expected to write automated tests for features. These engineers needed to manage the tests themselves, the infrastructure to power these types of tests, and a variety of backend services we required to run Slack end-to-end on our internal shared development infrastructure. As a result, engineers often had failures that were unrelated to their PRs, which blocked them from merging and led to flakes.
While all engineers wrote tests, these tests were typically not updated until they completely broke, and many tests had no clear escalation paths for owners. These intertwined problems led to developers struggling to figure out why their tests were failing, retries to resolve flaky tests, and an overall frustrating experience for developers. Our internal infrastructure struggled to process so many jobs and led to cascading internal service failures throughout 2019 and 2020. We tackled cascading internal service failures and cost increases in ‘Infrastructure Observability for Changing the Spend Curve’.
In PRs, engineers waited a long time for test results. At its worst, our time-to-test-results for a commit was 95 minutes, which meant developers had to wait a long time for the tests each commit pushed to pass or fail. Before this project, the median PR in Webapp had over 40 end-to-end test suites execute (p95 over 60 test suites). Earlier in 2020, our teams focused on executing end-to-end tests reliably (less than 1% flake rate per execution for many end-to-end test suites). However, when we zoom out to look at metrics and surveys, engineers still frequently encounter flaky tests, slow feedback loops, and complicated debugging. In evaluating the developer experience, we came to a few conclusions. Even with individual test suites having a low flake rate on pre-merge test suites (ideally 1% or less), the sheer number of end-to-end tests (more than 60 end-to-end test suites for most PRs) would have led to an unsatisfactory experience (99% not flaky for 60 suites would equal 55% of PRs would have at least one flaky test suite).
Workflow changes
Given the rate at which Slack was increasing its test coverage, it was not sustainable to keep all test suites at the pre-merge state. From an organizational point of view, it was not feasible to triage all failing suites and keep them up to standard. Moreover, the load in our infrastructure from running all tests pre-merge contributed to flakiness since not all of our downstream services and dependencies were guaranteed to be up. On the other hand, slashing the amount of tests pre-merge would greatly increase the risk of bugs slipping into production, but would greatly decrease time-to-merge for a developer’s PR, improving developer velocity. We needed to find a middle ground that would guarantee safe code while balancing developer velocity.
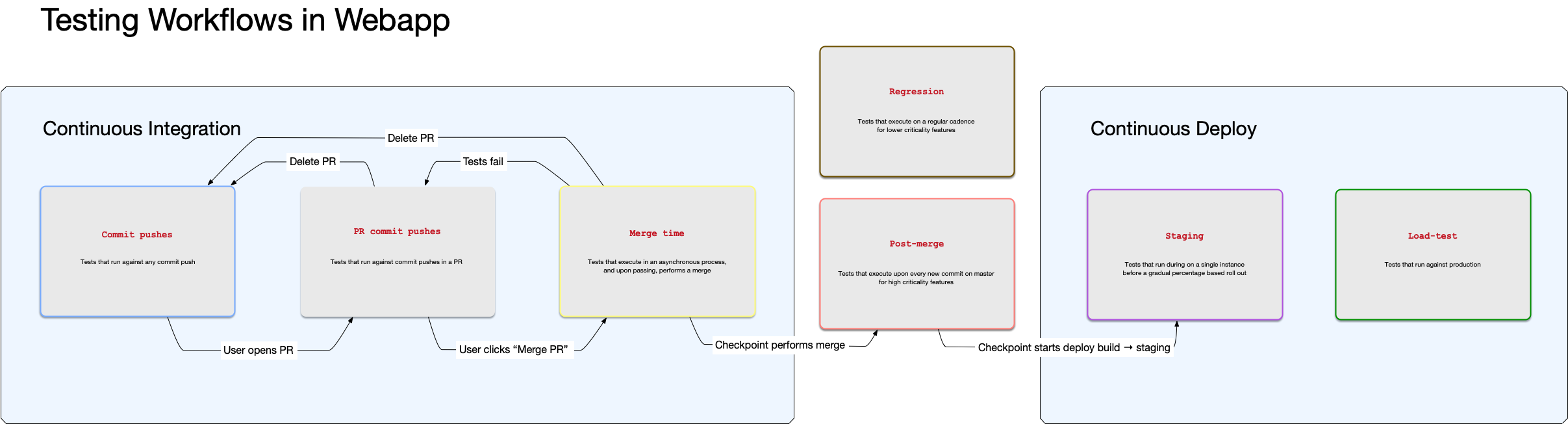
In many CI workflows, pre-merge end-to-end tests must all pass before a PR can be merged. With this project, we made the following workflow change to create two additional pipelines after merging:
- Pre-merge pipeline (existing): During development, a subset (<1%) of end-to-end tests execute and must pass to merge a user’s PR to mainline. These tests were selected for high criticality features that block merges and deploys.
- Post-merge pipeline (new): After merging to mainline, a larger subset (<10%) of end-to-end tests execute against each commit, and these tests give signal to the CD pipeline before deploy. These are medium-criticality features that block deploys.
- Regression pipeline (new): After merging to mainline, the remainder of end-to-end tests batch execute against batches of commits. These tests give signal to broken low-criticality features on each deploy, and run on a bi-hourly cadence. These tests batch execute to reduce false negative signal from flaky tests or a flaky test running framework.
Unlike before, where pre-merge tests gated merging, a user is alerted on failed test executions and their workflow is blocked when tests are flaky. The new pipelines also allow our groups to explicitly define escalation paths and owners for various tests. Users are now able to develop and test code with higher frequency feedback loops, and they are also able to fix-forward more quickly due to more accurate attribution to critical failures.
However, we needed additional changes for the triage process, since previously many tests for high-criticality features were gated pre-merge. We sought to close the loop and minimize bad code from making its way through CD to customers.
Here’s a simplified diagram of the updated code testing workflows for Webapp:
Triage changes
In order to get both test and product engineers on the same page about complex failures in CI, we created a self-driven course and documentation that explains the new alerts and integration with Slack. After this course, engineers are asked to shadow others, and they are given additional context on how to identify and prioritize each type of failure in our pipeline. The priority of identified issues escalates in response time from regression to pre-merge to post-merge to CD tests. We created a Slack channel (#alerts-ci-issue) to additionally provide awareness of decentralized issues in CI systems, and when there is a post-merge failure, engineers on triage are automatically alerted of this with a bit of Slack bot magic.
Engineers across teams identified high-priority tests and moved these to the post-merge pipeline. These tests aim to have low flakiness (<0.1% test flakiness) and generate high signal for important user experiences. Our team improved our test provenance tooling, and each test was assigned to a channel specific to the business area it belonged to (i.e. message-related tests map to #post-merge-messaging, with members of that team staffing the triage channel, typically in a rotation).
These efforts created organizational alignment through clear expectation setting. A wide range of engineering departments within Slack came together to decide which tests were important to maintaining a high-quality and performant CD pipeline.
Designing human-centric alerts
For the remainder of this article we will dive into our strategy of escalating post-merge failures and progressively escalating to different teams quickly and efficiently.
First, we created a mechanism that would alert in a Slack channel when we saw two or more consecutive failures. This ‘state’ is based on a finite state machine, where we could map out a failed state when a test suite failed twice in a row. We visualized this with our own analytics tools, as well as with Grafana alerting:
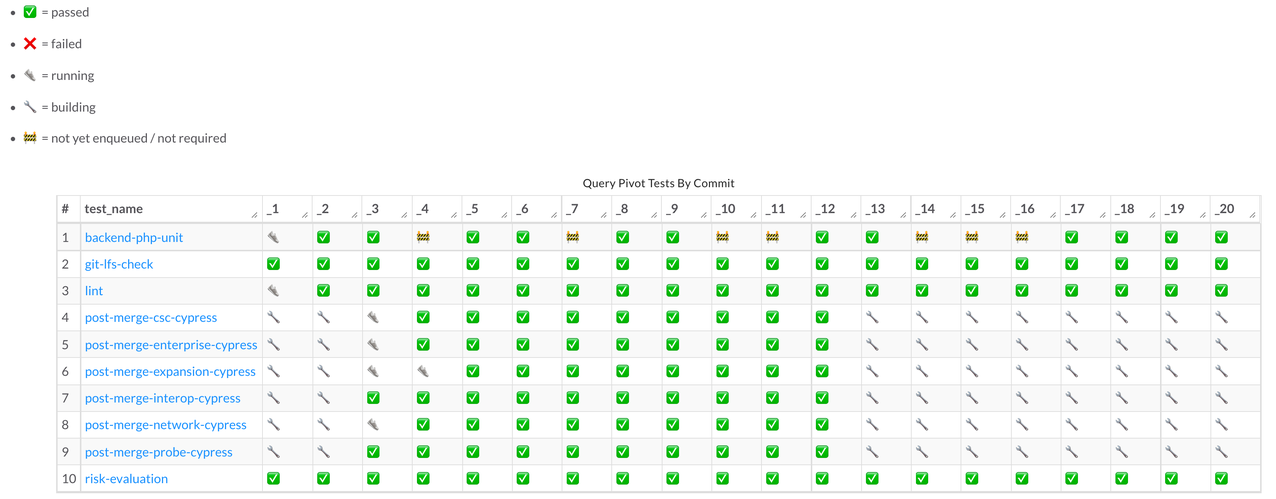 Having access to this state allowed us to pinpoint the specific commit at which the test suite began to fail, which allowed us to identify the faulty PR that caused this failure.
Having access to this state allowed us to pinpoint the specific commit at which the test suite began to fail, which allowed us to identify the faulty PR that caused this failure.
When the state is ❌ twice in a row, we send this message over to a Slack channel:

Next, we discovered we needed a much clearer process to follow.
Previously, our escalation process at this point was entirely manual for deploys. This meant we had a longer time-to-resolution (defined as post-merge failure state recovery), which increased the likelihood of bugs going out to our customers. When CI detected consecutive post-merge failures, we brought four liaisons to a single channel for escalation:
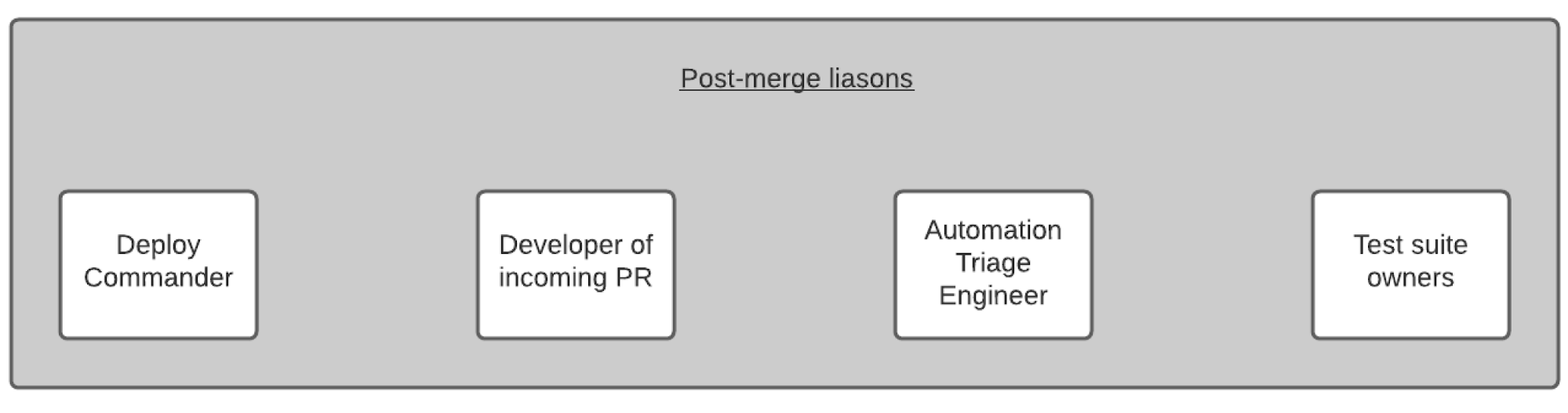
In the past, responses might be spread across many channels, and no one would be certain of which channel held the main thread: suite-owner channels, platform-owner channels, internal-tooling-teams channels, the deploys channel. Now, we invite engineers to a single channel and then let the engineers add other folks who might need to be involved. To do this, we changed our existing Slack bot to create channels based specifically on a certain post-merge failure. Our bot would dig through our alerts channel, and would then alert engineers on the triage schedule of this failure. Triage engineers then had the option to hit an escalation button which would create a brand new channel and add two of the corresponding liaisons into this channel, with the developer name exposed by the bot in case engineers needed to escalate further.
In this order, the test triage engineer was the first to be informed of a failure. The engineer would look into the failure, verify whether this looked like an infrastructure or test flakiness failure, and escalate further to the test suite owner who had more context into the test cases themselves. If both liaisons concluded that the issue at hand was not a result of test flakiness, service-level change, or infrastructure-level changes, they would then bring the Developer of the PR into the conversation, and begin debugging from there.
Lastly, if we need to remove the faulty PR, we will then need to loop in our deploy commander to stop that PR from reaching our customers. This lengthy escalation process is where Slack automation comes into play. The longer a faulty build goes undetected, the more expensive (in engineering time and in potential broken customer impact) it becomes to revert the faulty commit or fix-forward.
Adding this workflow for escalation in post-merge failures also allowed us to easily record time to resolution and time to triaging for failures in post-merge, and let us pinpoint suites that were failing often and get stakeholder attention on these. This workflow is important to escalate because a failure represents a customer problem which might require test engineers and product engineers to diagnose the failure from different perspectives.
We wanted to create a set of actionable escalation paths for humans that would minimize noise while also screening for false-positives. Since consecutive failures can be legitimate, we first ask test owners to verify the validity of the failure. For example, if there is an ongoing incident that affects CI infrastructure which then causes post-merge tests to fail, the platform engineer would quickly read failure logs and verify that the failure is not attributed to a bug in new code being shipped out to customers. During incidents, Slack stops all new code deployments until CI infrastructure is healthy again.
Test owners are the first line of defense when it comes to debugging the failures, and due to the way we’ve set up triage for our automated tests, onboarded new engineers, and explained our escalation process for post-merge tests, we’ve had a lot of success in first targeting this alert directly to the engineers assigned to triage. Moreover, there are always two engineers on triage, which helps quickly diagnose a failing test.
A flow diagram of the post-merge test-failure-alerting workflow, and the corresponding channel that was created:

Conclusion
Slack engineers have been using this tiered testing workflow for most of the last year and have experienced a faster, more reliable testing and deployment experience in Webapp. This change increased velocity and sentiment without sacrificing quality for our customers. Using a tiered testing pipeline and the socio-technical workflows described, we were able to identify bad code and quickly provide context to the right group to fix this code before it reaches customers.
Through improved feedback loops, we were able to shift many tests to execute after merging and greatly improve the test user experience.
This tiered testing workflow project helped us understand how different parts of Slack engineering have traditionally worked in silos and can better align on strategy and execution. Over the last six months, we have created a working group across departments (senior engineers from 12 teams) to define a north star document outlining goals, state of the business, and strategic priorities for testing and development. Each goal represents one part of a flywheel, that builds upon each other with incremental projects. We are now actively iterating on a shared roadmap toward an excellent CI experience. This roadmap includes investments in areas like improved observability (e.g. identification of the bottlenecks across CI workflows) and fewer end-to-end tests (e.g. models and tools to understand code being tested between test platforms).
We want to share a special thank you to Sid Sarao, Zack Weeden, Jaime Scheinblum, Peter Secor, Dave Harrington, Nick Matute, and Nolan Caudill for your help in shaping the trajectory of this project!
In Core Development Engineering, we care deeply about how engineers build, test, deploy and release Slack to our users. We’re constantly thinking of new ways to craft excellent development and infrastructure experiences. If you’re interested in working with us, we would love to have you join!





