
Building load test infrastructure is tricky and poses many questions. How can we identify performance regressions in newly deployed builds, given the overhead of spinning up test clients? To gather the most representative results, should we load test at our peak hours or when there’s a lull? How do we incentivize engineers to invest time in load testing, especially when environment setup is time consuming? We realized that the solution to many of our problems was simple: load test all the time.
We’ve shared our journey of building load testing tools at Slack as our usage has scaled. Once we had a solid set of load testing tools (most notably, Koi Pond), we focused on our next goal: building a culture of performance at Slack. Rather than approach performance reactively, we wanted it to be ingrained in the development process and easy to consider. Concretely, we established these goals:
- Build a store of data that reflects the usage of our largest customers
- Enable product and infrastructure teams to load test easily and regularly
- Integrate load testing into our release cycles
Continuous load testing was a key step to unlocking all these goals and answering many of our questions around realistic testing and adoption. Having clients booted and running all the time removes the extra effort required by engineers to boot up clients and set up their custom environment. When we deploy builds to production, we can immediately run tests against a large organization with a high number of active users to ensure we didn’t introduce any performance regressions. Finally, continuous load testing means we don’t need to rally teams in preparation for a specific event. Performance issues are caught early and incrementally instead. This final point was an especially important consideration for us as we had a large upcoming launch: GovSlack, an instance of Slack run in GovCloud, designed to comply with the most stringent security and operational requirements of public sector customers.
Of course, this is easier said than done. Before flipping the switch, we needed to ensure that our continuous load testing platform was safe, resilient, and well-understood by our fellow engineers.
Technical Background
Koi Pond is our primary load testing tool at Slack. A koi is a slimmed down Slack client that makes two types of network requests: API requests and messages over a websocket connection. The specific requests that koi make are determined by a configuration file that is based on average user behavior, courtesy of our data warehouse.
Koi are spun up in Kubernetes pods, or Schools, with a maximum of 5,000 koi per School. The Keeper, the server of the Koi Pond service, keeps track of all the load test information (e.g. which organization or workspace we’re load testing against, how long the test runs for, etc.). Schools regularly poll the Keeper to get allocated more work or for a change in load test status.
Our previous blog post goes into detail about Koi Pond and its architecture, if you’re interested in learning more.
Safety
While our load test environment is largely isolated, some parts of our infrastructure are shared with the rest of production. Because of this, one of our priorities before enabling continuous koi was building solid safety features into the service.
One of the features we built was a service we call Automatic Shutdown. At a high level, this service polls metrics and sends a signal to stop any active load testing if the resulting value does not meet the defined threshold. To implement this, we used Trickster APIs to query certain metrics in Prometheus. The Automatic Shutdown service requires a list of Query objects which we defined to include the query string, time range to query, Prometheus cluster, value threshold, comparator, and label.
As an example, here’s the Query object for API success rate as reported by the Koi Pond service.

Simply put, if the web API success rate is ever sustained below 95% for five minutes, we’ll shut down any active load tests.
We implemented the Automatic Shutdown service in Slack’s shared Go repository because we believe it will be useful for our other load testing services as well. The format of input also makes it trivial to add extra queries as needed. Registering Koi Pond tests with Automatic Shutdown gave us confidence that if the load test’s health or Slack’s global health moved into an unhealthy state, the load test would no longer contribute to any extra strain on our services or corrupt any investigation into legitimate production issues. A bonus side effect of this safety feature is it reduces the likelihood of off-hours pages for our team and other infrastructure teams, since we don’t require manual intervention to stop problematic traffic.
In addition to the new service, we added the capability to partially shut down any load test via the Koi Pond UI. In the event that load test traffic was suspect, this allows us to remove a specific percentage of traffic to identify the source of any issues.
Finally, we made some updates to our Emergency Stop service. This is a service that every load test at Slack registers with — Koi Pond, API Blaster, you name it. When we initiate the Emergency Stop status, all currently running load tests are immediately stopped. On the Emergency Stop UI, you can see all the currently running tests and history of Emergency Stop usage.

Any engineer at Slack can use this, especially in case of high-severity incidents.
Resilience
Another key to releasing continuous load testing was adding resilience to Koi Pond. In the beginning, Koi Pond was built as an uber-lightweight application where all load test data was stored in-memory – great for reducing network overhead and initial development time, but problematic for scenarios where we were depending on reliable, persisted data.
Recall that Koi Pond is built with Kubernetes, where the Keeper pod acts as the main server that assigns work to (potentially many) School pods. At Slack, we have the option to configure a “minimum pod lifespan” of up to 7 days for Kubernetes pods that helps with the average uptime. However, when a pod requires a mandatory update or needs a critical security patch, it’s immediately terminated and another is started in its place. That means there are no guarantees of continuous uptime for Koi Pond pods. On top of that, whenever we deploy new code, the pods are restarted to pick up the changes. If the Keeper pod restarts, then all its memory about load tests is lost.
This is where adding a database to back Koi Pond becomes critical for running continuous load tests. Adding state to the service unlocks the ability to persist load test state between Keeper restarts. On top of that, we’re also able to view and query historical data about load tests.
We implemented the database with AWS’s DynamoDB – a NoSQL database service that supports key-value and document data structures. A key advantage of a NoSQL database is that it allows for a flexible, dynamic schema that we can iterate on as we continue to build out Koi Pond. It also enables us to store unstructured data like documents or JSON, which Koi Pond uses to store token configuration, formation scripts, and behavior files.
Besides backing Koi Pond with a database, another way we built resilience into our system was by automating processes that were previously manual, opaque, and error-prone. For example, Koi Pond relies on user tokens to mimic real human users taking actions within Slack. These user tokens need to be generated and stored in a file corresponding to the workspace the user is a member of.
We occasionally need to re-generate these tokens when they’re expired or otherwise unusable with the Slack APIs. Generating tokens was originally a manual process where an engineer would: modify a configuration file; kick off a long-running script (typically in the span in hours); export the output of that script to the base image of the Koi Pond pods; and finally deploy all those changes.
This implementation worked well when we first started running Koi Pond tests, since our load test organization had 15 workspaces and 500K users. Today, however, we’re now load testing with other organization shapes (e.g. an organization with thousands of workspaces) and much larger teams (e.g. millions of users). Koi Pond is also being increasingly used by our enterprise and authentication product teams, which creates scenarios where session expiration load tests require us to generate tokens more often.
As we scaled our load testing operations, we noticed there was an opportunity to automate token generation. The new process now requires minimal engineering intervention, since we use a cron job to run token generation periodically. The automated script sends a batch of users to the job queue for asynchronous token generation and storage. Instead of exporting load test tokens to the container base image, we now store the tokens in an encrypted s3 bucket. If any single job fails during the script, it’s automatically retried several times with exponential backoff. If there’s some sort of fatal error, an engineer can step in to debug and eventually retry the job via a UI. And finally, the script also has built-in logging to improve the visibility of any errors that may have occurred. By improving token generation—a key requirement for our load testing platform—we’ve also made continuous load tests more reliable as a result.
Release
Communication was paramount to a successful launch; it was important to us to maintain the credibility of our load test tool and the trust of the engineering organization. Noisy alerts and an unreliable platform could cause load testing to be viewed as a nuisance rather than a useful tool. Therefore, we planned a careful and slow rollout process, with a gradual ramp-up from 5,000 koi to 500,000 koi and a week of monitoring at each stage. However, our release plan began much earlier; collaboration with other infrastructure teams (asynchronous services, data stores, real time services, and Flannel) from the start of the project was essential. We requested core infrastructure teams to review our proposal before we started any technical work, to ensure that we were able to incorporate any feedback into our tech spec and so they were informed throughout our process. We wanted a smooth and transparent rollout with no surprises for any of our partner infrastructure teams.
One risk is that we weren’t certain of the cost of running a large number of clients continuously. Before the rollout began, we partnered with our Cloud Economics team to calculate projections based on our one-off tests and committed to monitoring this closely to ensure that we didn’t rack up an unreasonably high AWS bill. Ultimately, everything worked as expected: Koi Pond is lightweight and cheap to run (especially compared to our previous load testing tools) and this was reflected in the cost of our continuous tests, well within our expected spending.
Another challenge that we wanted to preempt was a potentially taxing on-call rotation for our small-but-mighty team of four. We wanted to ensure that the incident commanders and deploy commanders were well-equipped, as the first line of defense, to handle any serious issues that came up off-hours. We began communication with the incident command rotation early and added various metrics to the deploy health dashboard, including load test API success and latency, gateway server health, and percentage of 5xx errors on the load test tier. Finally, we wrote and shared comprehensive documentation about how to handle any potential issues related to continuous load testing.
At each phase of the release, we alerted all the relevant infrastructure teams and channels such as #deploys and #ops for visibility. To easily send out these notifications, we used workflows. Here’s what a typical rollout message looked like:
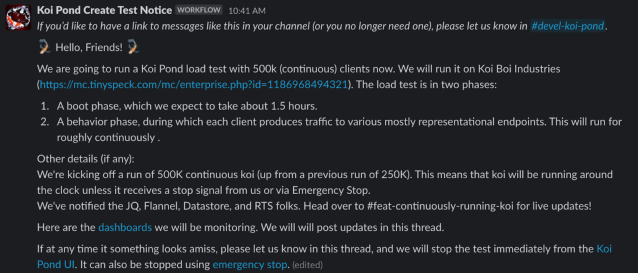
This ensured that all the right folks had eyes on this release and knew where to go in case anything looked amiss. We also wanted to include reminders about Emergency Stop and dashboards to look at in case of any issues. These efforts, combined with the safety features we added to Koi Pond itself, helped us with an ultimately smooth and anticlimactic launch. In the 6 months since releasing continuous load testing, our team hasn’t been paged off-hours once!
Wins
Reflecting on our initial goals, we have found continuous load testing to be an incredible investment for our organization.
Build a store of data that reflects the usage of our largest customers
By running clients 24/7 on an organization that is 4x the size of our largest customer, we have generated a large amount of data that provides baseline expectations for performance of a large organization. With this, we have been able to validate changes with widespread impact (including HHVM upgrades and auth changes that affect every API) against our load test organization, and deploy to production with the confidence that our customers won’t experience any performance impacts from those feature releases.
Enable product and infrastructure teams to load test easily and regularly
Product and infrastructure teams alike have used continuous load testing to verify the quality and performance of their features before release. One great example was our Cloud Infrastructure team using the continuous clients to see how our systems and monitoring respond to removal of traffic from a single availability zone, all without putting any customer traffic at risk. Another example is when our Messaging team created a set of new tables and then tested the efficiency of fetching cached user profiles at scale.
In addition to testing single features, preparing for large events, such as the launch of GovSlack, is much easier than it has been in the past. In contrast to the effort for onboarding a large customer a year ago, GovSlack Engineers are able to get realistic signals continuously. Previously, spinning up an ad-hoc load test of the size of our continuously running clients would take a day of engineering effort. Now, spinning up a continuous test against our GovSlack environment (once we added the ability to Koi Pond) took just a few minutes and immediately provided our team with valuable insights on performance as we prepare for GA.
Ideally, continuous load testing would preclude any incidents that stem from a large amount of load, but the occasional scenario does escape our testing. One such incident occurred when a large organization’s admin posted a message in an org-wide default channel, causing users to experience degraded performance. We were initially puzzled, since we had tested a similar scenario with 4x the traffic, but soon realized we didn’t account for the high number of reactions on previous posts that every user was fetching when navigating to the channel. In response to the incident, several fixes were implemented and deployed. In a world before continuous load testing, we would have either had to wait for the customer to take that action again or spend about a week’s worth of effort to spin up the exact environment and scenario. With continuous koi, we were able to recreate the exact scenario within about an hour (since we simply had to add a few lines to our configuration for all our already active clients to populate the channel as necessary) and verify that the fixes improved performance. The next time the customer posted an org-wide message, they had no issues either.
To increase the reach of our tool, we’ve organized several Koi Pond learning sessions where we go through the tool and also demo how to write different types of load tests. We’ve also created video tutorials to include as a part of engineering onboarding. The results have been encouraging — our feature coverage has increased by 10%. Through the learning opportunities our team provides, we hope to only improve with our goal to make performance an important consideration in feature development and release.
Integrate load testing into our release cycles
Load testing is now part of our release cycles and there is work underway to make the tests we run even more valuable and actionable to engineers. For example, we’ve been running automated QA tests focused on performance five times a day against our load test organization. While Koi Pond metrics identify regressions in our backend code, this framework allows us to find any bugs or issues on the client side as well. We plan to make these tests blocking as a part of our deploy pipeline, so that we can fix any performance bugs before they make it out to production. Beyond end-to-end testing, the Koi Pond alerting we’ve set up has caught several performance regressions (including experiments that had degraded performance specifically in large orgs, and problematic hot cache keys) and even shown early signals for incidents.
What’s next?
Of course, there’s always room for improvement. For our next steps, we’ll be iterating on some themes we discussed, such as automatically updating our behaviors from our data warehouse, adding more Koi Pond tests to our deploy pipeline, and improving the user experience for engineers who write load tests. If this work sounds interesting to you, please apply to the open roles on our team:





