


For a company like Slack that strives to be as data-driven as possible, understanding how our users use our product is essential.
The Data Engineering team at Slack works to provide an ecosystem to help people in the company quickly and easily answer questions about usage, so they can make better and data informed decisions: “Based on a team’s activity within its first week, what is the probability that it will upgrade to a paid team?” or “What is the performance impact of the newest release of the desktop app?”
The Dream
We knew when we started building this system that we would need flexibility in choosing the tools to process and analyze our data. Sometimes the questions being asked involve a small amount of data and we want a fast, interactive way to explore the results. Other times we are running large aggregations across longer time series and we need a system that can handle the sheer quantity of data and help distribute the computation across a cluster. Each of our tools would be optimized for a specific use case, and they all needed to work together as an integrated system.
We designed a system where all of our processing engines would have access to our data warehouse and be able to write back into it. Our plan seemed straightforward enough as long as we chose a shared data format, but as time went on we encountered more and more inconsistencies that challenged our assumptions.
The Setup
Our central data warehouse is hosted on Amazon S3 where data could be queried via three primary tools: Hive, Presto and Spark.
To help us track all the metrics that we want, we collect data from our MySQL database, our servers, clients, and job queues and push them all to S3. We use an in-house tool called Sqooper to scrape our daily MySQL backups and export the tables to our data warehouse. All of our other data is sent to Kafka, a scalable, append-only message log and then persisted on to S3 using a tool called Secor.
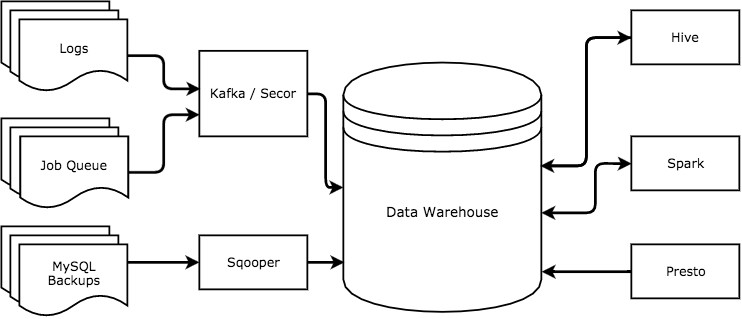
For computation, we use Amazon’s Elastic MapReduce (EMR) service to create ephemeral clusters that are preconfigured with all three of the services that we use.
Presto is a distributed SQL query engine optimized for interactive queries. It’s a fast way to answer ad-hoc questions, validate data assumptions, explore smaller datasets, create visualizations and use it for some internal tools, where we don’t need very low latency.
When dealing with larger datasets or longer time series data, we use Hive, because it implicitly converts SQL-like queries into MapReduce jobs. Hive can handle larger joins and is fault-tolerant to stage failures, and most of our jobs in our ETL pipelines are written this way.
Spark is a data processing framework that allows us to write batch and aggregation jobs that are more efficient and robust, since we can use a more expressive language, instead of SQL-like queries. Spark also allows us to cache data in memory to make computations more efficient. We write most of our Spark pipelines in Scala to do data deduplication and write all core pipelines.
Tying It All Together
How do we ensure that all of these tools can safely interact with each other?
To bind all of these analytics engines together, we define our data using Thrift, which allows us to enforce a typed schema and have structured data. We store our files using Parquet which formats and stores the data in a columnar format. All three of our processing engines support Parquet and it provides many advantages around query and space efficiency.
Since we process data in multiple places, we need to make sure that our systems always are aware of the latest schema, thus we rely on the Hive Metastore to be our ground truth for our data and its schema.
CREATE TABLE IF NOT EXISTS server_logs(
team_id BIGINT,
user_id BIGINT,
visitor_id STRING,
user_agent MAP<STRING, STRING>,
api_call_method STRING,
api_call_ok BOOLEAN
)
PARTITIONED BY (year INT, month INT, day INT, hour INT)
STORED AS PARQUET
LOCATION 's3://data/server_logs'Both Presto and Spark have Hive connectors that allow them to access the Hive Metastore to read tables and our Spark pipelines dynamically add partitions and modify the schema as our data evolves.
With a shared file format and a single source for table metadata, we should be able to pick any tool we want to read or write data from a common pool without any issues. In our dream, our data is well defined and structured and we can evolve our schemas as our data needs evolve. Unfortunately, our reality was a lot more nuanced than that.
Communication Breakdown
All three processing engines that we use ship with libraries that enable them to read and write Parquet format. Managing the interoperation of all three engines using a shared file format may sound relatively straightforward, but not everything handles Parquet the same way, and these tiny differences can make big trouble when trying to read your data.
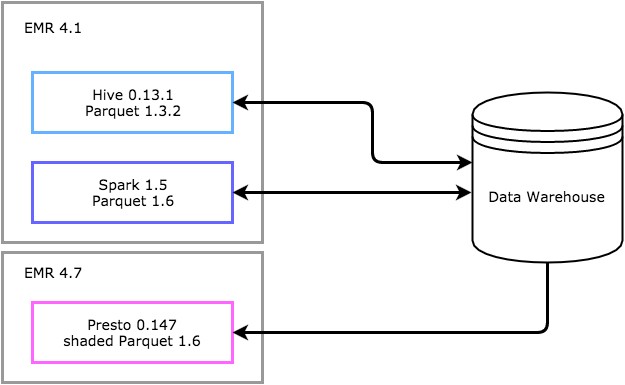
Under the hood, Hive, Spark, and Presto are actually using different versions of the Parquet library and patching different subsets of bugs, which does not necessarily keep backwards compatibility. One of our biggest struggles with EMR was that it shipped with a custom version of Hive that was forked from an older version that was missing important bug fixes.
What this means in practice is that the data you write with one of the tools might not be read by other tools, or worse, you can write data which is read by another tool in the wrong way. Here are some sample issues that we encountered:
Absence of Data
One of the biggest differences that we found between the different Parquet libraries was how each one handled the absence of data.
In Hive 0.13, when you use use Parquet, a null value in a field will throw a NullPointerException. But supporting optional fields is not the only issue. The way that data gets loaded can turn a block of nulls— harmless by themselves — into an error if no non-null values are also present (PARQUET-136).
In Presto 0.147, the complex structures were the ones that made us uncover a different set of issues — we saw exceptions being thrown when the keys of a map or list are null. The issue was fixed in Hive, but not ported in the Presto dependency (HIVE-11625).
To protect against these issues, we sanitize our data before writing to the Parquet files so that we can safely perform lookups.
Schema Evolution Troubles
Another major source of incompatibility is around schema and file format changes. The Parquet file format has a schema defined in each file based on the columns that are present. Each Hive table also has a schema and each partition in that table has its own schema. In order for data to be read correctly, all three schemas need to be in agreement.
This becomes an issue when we need to evolve custom data structures, because the old data files and partitions still have the original schema. Altering a data structure by adding or removing fields will cause old and new data partitions to have their columns appears with different offsets, resulting in an error being thrown. Doing a complete update will require re-serializing all of the old data files and updating all of the old partitions. To get around the time and computation costs of doing a complete rewrite for every schema update, we moved to a flattened data structure where new fields are appended to the end of the schema as individual columns.
These errors that will kill a running job are not as dangerous as invisible failures like data showing up in incorrect columns. By default, Presto settings use column location to access data in Parquet files while Hive uses column names. This means that Hive supports the creation of tables where the Parquet file schema and the table schema columns are in different order, but Presto will read those tables with the data appearing in different columns!
File schema:
"fields": [{"name":"user_id","type":"long"},
{"name":"server_name","type":"string"},
{"name":"experiment_name", "type":"string"}]
Table schema:
(user_id BIGINT, experiment_name STRING, server_name STRING)
----------------- Hive ------------------
user_id experiment_name server_name
1 test1 slack-1
2 test1 slack-2
---------------- Presto -----------------
user_id experiment_name server_name
1 slack-1 test1
2 slack-2 test1It’s a simple enough problem to avoid or fix with a configuration change, but easily something that can slip through undetected if not checked for.
Upgrading EMR
Upgrading versions is an opportunity to fix all of the workarounds that were put in earlier. But it’s very important to do this thoughtfully. As we upgrade EMR versions to resolve bugs or to get performance improvements, we also risk exchanging one set of incompatibilities with another. When libraries get upgraded, it’s expected that the new libraries are compatible with the older versions, but changes in implementation will not always allow older versions to read the upgraded versions.
When upgrading our cluster, we must always make sure that the Parquet libraries being used by the analytics engines we are using are compatible with each other and with every running version of those engines on our cluster. A recent test cluster to try out a newer version of Spark resulted in some data types being unreadable by Presto.
This leads to us being locked into certain versions until we implement workarounds for all of the compatibility issues and that makes cluster upgrades a very scary proposition. Even worse, when upgrades render our old workarounds unnecessary, we still have a difficult decision to make. For every workaround we remove, we have to decide if it’s more effective to backfill our data to remove the hack or perpetuate it to maintain backwards compatibility. How can we make that process easier?
A Common Language
To solve some of these issues and to enable us to safely perform upgrades, we wrote our own Hive InputFormat and Parquet OutputFormat to pin our encoding and decoding of files to a specific version. By bringing control of our serialization and deserialization in house, we can safely use out-of-the-box clusters to run our tooling without worrying about being unable to read our own data.
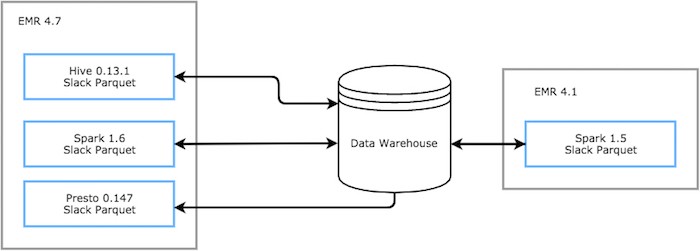
These formats are essentially forks of the official version which bring in the bug fixes across various builds.
Final Thoughts
Because the various analytics engines we use have subtly different requirements about serialization and deserialization of values, the data that we write has to fit all of those requirements in order for us to read and process it. To preserve the ability use all of those tools, we ended up limiting ourselves and building only for the shared subset of features.
Shifting control of these libraries into a package that we own and maintain allows us to eliminate many of the read/write errors, but it’s still important to make sure that we consider all of the common and uncommon ways that our files and schemas can evolve over time. Most of our biggest challenges on the data engineering team were not centered around writing code, but around understanding the discrepancies between the systems that we use. As you can see, those seemingly small differences can cause big headaches when it comes to interoperability. Our job on the data team is to build a deeper understanding of how our tools interact with each other, so we can better predict how to build for, test, and evolve our data pipelines.
If you want to help us make Slack a little bit better every day, please check out our job openings page and apply.
Apply now




