


At Slack, the goal of the Mobile Developer Experience Team (DevXp) is to empower developers to ship code with confidence while enjoying a pleasant and productive engineering experience. We use metrics and surveys to measure productivity and developer experience, such as developer sentiment, CI stability, time to merge (TTM), and test failure rate.
We have gotten a lot of value out of our focus on mobile developer experience, and we think most companies under-invest in this area. In this post we will discuss why having a DevXp team improves efficiency and happiness, the cost of not having a team, and how the team identified and resolved some common developer pain points to optimize the developer experience.
How it all started
A few mobile engineers realized early on that engineers who were hired to write native mobile code might not necessarily have expertise in the technical areas around their developer experience. They thought that if they could make the developer experience for all mobile engineers better, they could not only help engineers be more productive, but also delight our customers with faster, higher-quality releases. They got together and formed an ad-hoc team to address the most common developer pain points. The mobile developer experience team has grown from three people in 2017 to eight people today. In our five years as a team, we have focused on these areas:
- Local development experience and IDE usability
- Our growing codebase. Ensuring visibility into problematic areas of the codebase that require attention
- Continuous Integration usability and extensibility
- Automation test infrastructure and automated test flakiness
- Keeping the main branch green. Making sure the latest main is always buildable and shippable
The cost of not investing in a mobile developer experience team
A mobile engineer usually starts a feature by creating a branch on their local machine and committing their code to GitHub. When they are ready, they create a pull request and assign it to a reviewer. Once a pull request is opened or a subsequent commit has been added to the branch, the following CI jobs get kicked off:
- Jobs that build artifacts
- Jobs that run tests
- Jobs that run static analysis
Once the reviewer approves the pull request and all checks pass on CI, the engineer could merge the pull request in the main branch. Here is the visualization of the developer flow and the flow interruptions associated with each area.
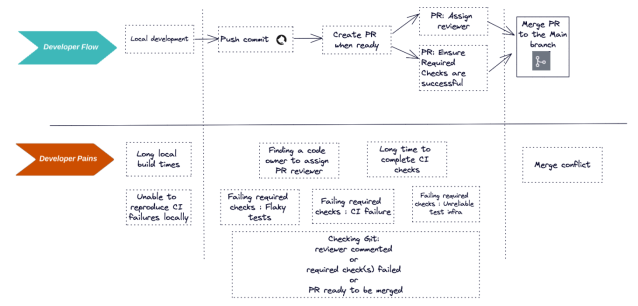
Here is a rough estimate of the cost of some developer pain points and the cost to the company for not addressing these pain points as the team grows:
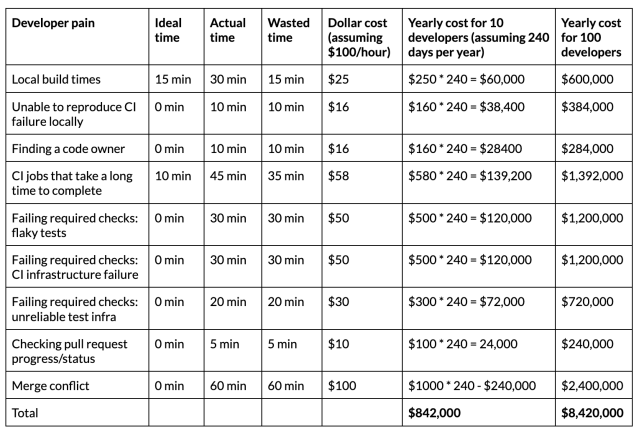 While developers can learn to resolve some of these issues, the time spent and the cost incurred is not justifiable as the team grows. Having a dedicated team that can focus on these problem areas and identifying ways to make the developer teams more efficient will ensure that developers can maintain an intense product focus.
While developers can learn to resolve some of these issues, the time spent and the cost incurred is not justifiable as the team grows. Having a dedicated team that can focus on these problem areas and identifying ways to make the developer teams more efficient will ensure that developers can maintain an intense product focus.
Approach
Our team partners with the mobile engineering teams to prioritize which developer pain points to focus on, using the following approach:
- Listen to customers and work alongside them. We will partner with a mobile engineer as they are working on a feature and observe their challenges.
- Survey the developers. We conduct a quarterly survey of our mobile engineers where we track general Net Promoter Score (NPS) around mobile development.
- Summarize developer pain points. We distill the feedback into working areas that we can split up as a team and tackle.
- Gather metrics. It is important that we measure before we start addressing a pain point to ensure that a solution we deploy actually fixes the issue, and to know the exact impact our solution had on the problem area. We come up with metrics to track that correlate with the problem areas developers have and track them on dashboards. This allows us to see the metrics change over time.
- Invest in experiments that improve developer pain points. We will think of solutions to the problems by either consulting with other companies that also develop at this scale, or by coming up with a unique solution ourselves.
- Consider using third-party tools. We evaluate whether it makes more sense to use existing solutions or to build out our own solutions.
- Repeat this process. Once we launch a solution, we look at the metrics to ensure that it moves the needle in the right direction; only then do we move onto the next problem area.
Developer pains
Let’s dive into some developer pain points in order of severity and examine how the mobile developer experience team addressed them. For each pain point, we will start with some quotes from our developers and then outline the steps we took.
CI test jobs that take a long time to complete
When a developer has to wait a long time for tests to run on their pull requests, they switch to working on a different task and lose context on the original pull request. When the test results return, if there is an issue they need to address, they have to re-orient themselves with the original task they were working on. This context switching takes a toll on developer productivity. The following are two quotes from our quarterly mobile engineering survey in 2018.
Faster CI time! I think this is requested a lot, but it would be amazing to have this improved
Jenkins build times are pretty high and it would be great if we can reduce those
From 1 to 10 developers, we had a couple of hundred tests and ran all of them serially using Xcodebuild for iOS and Firebase Test lab for Android.
Running the tests serially worked for many years, until the test job time started to take almost an hour. One of the solutions we considered was introducing parallelization to the test suites. Instead of running all of the tests serially, we could split them into shards and run them in parallel. Here is how we solved this problem on the iOS and Android platforms.
iOS
We considered writing our own tool to achieve this, but then discovered a tool called Bluepill that was open sourced by Linkedin. It uses Xcodebuild under the hood, but added the ability to shard and execute tests in parallel. Integrating Bluepill decreased our total test execution time to about 20 minutes.
Using Bluepill worked for a few more years until our unit test job started to once again take almost 50 minutes. Slack iOS engineers were adding more test suites to run, and we could no longer simply rely only on parallelization to lower TTM.
How moving to a modern build system helped drive down CI job times
Our next strategy was to implement a caching layer for our test suites. The goal was to only run the tests that needed to be run on a specific pull request, and return the remaining test results from cache. The problem was that Xcodebuild does not support caching. To implement test caching we needed to move to a different build system:s Bazel. We utilized Bazel’s disk cache on CI machines so builds from different pull requests can reuse build outputs from another user’s build rather than building each new output locally.
In addition to the Bazel disk cache, we use the bazel-diff tool that allows us to determine the exact affected set of impacted targets between two Git revisions. The two revisions we compare are the tip of the main branch, and the last commit on the developers branch. Once we have the list of targets that were impacted, we only test those targets.
With the Bazel build system and bazel-diff, we were able to decrease TTM to an average of 9 minutes, with a minimum TTM of 4.5 minutes. This means developers can get the feedback they need on their pull request faster, and more quickly get back to collaborating with others and working on their features.
Android
In the early days, TTM was around 50 minutes, and Firebase Test Lab (FTL) did not have test sharding. We built an in-house test sharder on top of FTL called Fuel to break tests into multiple shards and call FTL APIs to run each test shard in parallel. This brought TTM from 50+ minutes to under 20 minutes. Here is the high level overview:
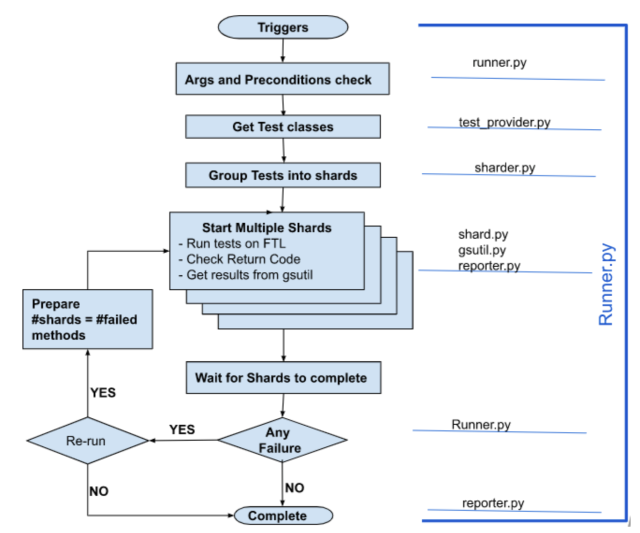
We continued using Fuel for two and a half years, and then moved to an open source test sharder called Flank. We continue to use Flank today to run Android functional and end-to-end UI tests.
Test-related failures
When a check fails on a pull request because of flaky or unrelated test failures, it has the potential to take the developer out of flow, and possibly impact other developers as well. Let’s take a look at a few culprits causing non-related pull request failures and how we have addressed them.
Fragile automation frameworks
From 2015 to early 2017, we used the Calabash testing framework that interacted with the UI and wrapped that logic in Cucumber to make the steps human readable. Calabash is a “blackbox” test automation framework and needs a dedicated automation team to write and manage tests. We saw that the more tests that were added, the more fragile the test suites became. When a test failed on a pull request, the developer would reach out to an Automation Engineer to understand the failure, attempt to fix it, then rerun it again and hope that another fragile test doesn’t fail their build. This resulted in a longer feedback loop and increased TTM.
As the team grew we decided to move away from Calabash and switched to Espresso because Espresso was tightly coupled with the Android OS and is also written in the native language (Java or Kotlin). Espresso is powerful because it is aware of the inner workings of the Android OS and could interface with it easily. This also meant that Android developers could easily write and modify tests because they were written in the language they were most comfortable with. A few benefits to highlight with migrations:
- This helped to shift testing responsibility from our dedicated automation team to developers, so they can write tests as needed to test the logic in the code
- Testing time went from ~350 mins to ~60 mins when we moved from Calabash to Espresso and FTL
Flaky tests
In early 2018 the developer sentiment towards testing was poor and caused a lot of developer pain. Here are couple of quotes from our developer survey:
Flimsy tests are still a bottleneck sometimes. We should have a better way tracking them and ping the owner to fix before it causes too much friction
Flaky tests slow me down to a halt – there should be a more streamlined process in place for proceeding with PR's once flaky tests are found (instead of blocking a merge as it happens now)
At one point, 57% of the test failures in our main branch were due to flaky tests and the percentage was even higher on developer pull requests. We spent some time learning about flaky tests and managed to get them under control in recent years by building a system to auto-detect and suppress flaky tests to ensure developer experience and flow is uninterrupted. Here is a detailed article outlining our approach and how we reduced test failures rate from 57% to 4%
CI-related failures
For many years we used Jenkins to power the mobile CI infrastructure, using Groovy-based .jenkinsfiles. While it worked, it was also the source of a lot of frustration for developers. These problems were the most impactful:
- Frequent downtime
- Reduced performance of the system
- Failure to pick up Git webhooks, and therefore not starting pull request CI jobs
- Failure to update the pull request when a job fails
- Difficulty in debugging failures due to poor UX
After flaky tests, CI downtime was the biggest bottleneck negatively impacting the mobile team’s productivity. Here are some quotes from our developers regarding Jenkins:
Need more reliable hooks between the jenkins CI and GitHub. When things do go wrong, there are sometimes no links in GH to go to the right place. Also, sometimes CI passes but doesn't report back to GH so PR is stuck in limbo until I manually rebuild stuff
Jenkins is a pain. Remove the Blue Ocean jenkins UI that is confusing and everyone hates
Jenkins is a mess to me. There are too many links and I only care about what broke and what button/link do I need to click on to retry. Everything else is noise
After using Jenkins for more than six years, we migrated away from it to BuildKite, which has had 99.96% uptime so far. Webhook-related issues have completely disappeared, and the UX is simple enough for developers to navigate without needing our team’s help. This has not only improved developer experience but also decreased the triage load for our team.
The immediate impact of the migration was an 8% increase in CI stability from ~87% to 95% and reduced Time to Merge by 41% from ~34 mins to ~20 mins.
Merge conflicts
Conflict while adding new modules or files to the Xcode project for iOS
As the number of iOS engineers at Slack grew past 20, one area of constant frustration was the checked in Xcode project file. The Xcode project file is an XML file that defines all of the Xcode project’s targets, build configurations, preprocessor macros, schemes, and much more. As a small team, it is easy to make changes to this file and commit them to the main branch without causing any issues, but as the number of engineers increases, the chances of causing a conflict by making a change in this file also increases.
I think the concern is more so the xcode project file, resolving conflicts on that thing is painful and error prone. I’m not sure what the best approach is to alleviating this possible pain point, especially if they have added new code files.
I had a dozen or so conflicts in the project file that I had to manually resolve. Not a huge issue in itself but when you’re expecting to merge a PR it can be a surprise
The solution we implemented was to use a tool called Xcodegen. Xcodegen allowed us to delete the checked in .xcodeproj file and create an Xcode project dynamically using a YAML file that contained definitions of all of our Xcode targets. We connected this tool to a command line interface so that iOS engineers could create an Xcode project from the command line. Another benefit was that all of the project and target level settings are defined in code, not in the Xcode GUI, which made the settings easier to find and edit.
After adopting Bazel we took it a step further and created the YAML file dynamically from our Bazel build descriptions.
Multiple concurrent merges to main have the potential to break main
So far we have talked about different issues that developers can experience when writing code locally and opening a pull request. But what happens when multiple developers are trying to land their pull requests to the main branch simultaneously? With a large team, multiple merges to main happen throughout the day which can make a developer’s pull requests stale quickly. The longer a developer waits to merge, the larger the chance of a merge conflict.
An increasing number of merge conflicts started causing the main branch to fail due to concurrent merges and started to negatively affect developer productivity. Until the merge conflict is resolved, the main branch would remain broken and pause all productivity. At one point merge conflicts were breaking the main branch multiple times a day. More developers started requesting a merge queue.
We keep breaking the main branch. We need a merge queue.
We brainstormed different solutions and ultimately landed on using a third party solution called Aviator, and combined it with our in-house tool Mergebot. We felt that building and maintaining a merge queue would be too much work for us and that the best solution was to rely on a company that was spending all of their time working on this problem. With Aviator, developers add their pull request to a queue instead of directly merging to the main branch, and once in the queue, Aviator will merge main into the developer branches and run all of the required checks. If a pull request was found to break main, then the merge queue rejects it and the developer is notified via Slack. This system helps avoid any merge conflicts.

Way better now with Aviator. Only pain point is I can't merge my pull requests and have to rely on Aviator. Aviator takes hours to merge my PR to master. Which makes me anxious.
Being an early adopter means you get some benefits but also some pain. We worked closely with the Aviator team to identify and address developer pains such as increased time to merge a pull request in the main branch and failure reporting on a pull request when it is dropped out of queue due to a conflict.
Checking pull request progress/status
This is a request we received in 2017 in one of our developer surveys:
Would really love timely alerts for PR assignments, comments, approvals etc. Also would be nice if we could get a DM if our builds pass (rather than only the alert for when they fail) with the option to merge it right there from slack if we have all the needed approvals.
Later in the year we created a service which monitors Git events and sends Slack notifications to the pull request author and pull request reviewer accordingly. The bot is named “Mergebot” and will notify the pull request author when a comment is added to their pull request or its status changes. It will also notify the pull request reviewer when a pull request is assigned to them. Mergebot has helped shorten the pull request review process and keep developers in flow. This is yet another example of how saving just five minutes of developer time saved ~$240,000 for a 100-developer team in a year.

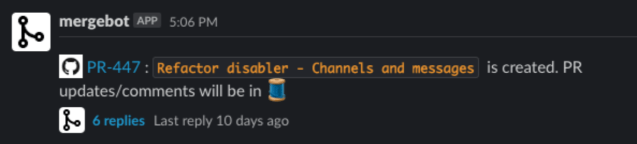
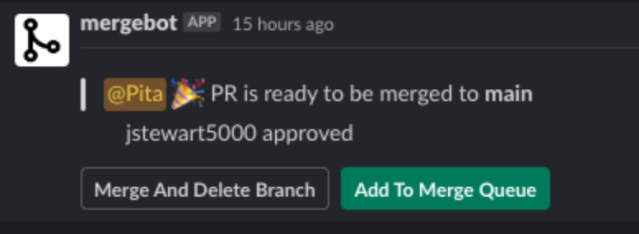 Recently github rolled out a similar feature called “github scheduled reminder” which, once opted into, notifies a developer of any PR update through Slack notification. While it covers the basic reminder part, Mergebot is still our developer’s preferred bot as it doesn’t require explicit opt-in and also allows pull requests to be merged through a click of the button through Slack.
Recently github rolled out a similar feature called “github scheduled reminder” which, once opted into, notifies a developer of any PR update through Slack notification. While it covers the basic reminder part, Mergebot is still our developer’s preferred bot as it doesn’t require explicit opt-in and also allows pull requests to be merged through a click of the button through Slack.
Conclusion
We want Slack to be the best place in the world to make software, and one way that we are doing that is by investing in the mobile developer experience. Our team’s mission is to keep developers in the flow and make their working lives easier, more pleasant, and more productive. Here are some direct quotes from our mobile developers:
Dev XP is great. Thanks for always taking feedback from the mobile development teams! I know you care 💪
We are using modern practices. Bazel is great. I feel highly supported by DevXP and their hard work.
The tools work well. The code is modularized well. Devxp is responsive and helpful and continues to iterate and improve.
Are these types of developer experience challenges interesting to you? If so, join us!





