

And now we welcome the new year. Full of things that have never been.
— Rainer Maria Rilke
January 4th 2021 was the first working day of the year for many around the globe, and for most of us at Slack too (except of course for our on-callers and our customer experience team, who never sleep). The day in APAC and the morning in EMEA went by quietly. During the Americas’ morning we got paged by an external monitoring service: Error rates were creeping up. We began to investigate. As initial triage showed the errors getting worse, we started our incident process (see Ryan Katkov’s article All Hands on Deck for more about how we manage incidents).
As if this was not already an inauspicious start to the New Year, while we were in the early stages of investigating, our dashboarding and alerting service became unavailable. We immediately paged in our monitoring team to try and get our dashboard and alerting service back up.
To narrow down the list of possible causes we quickly rolled back some changes that had been pushed out that day (turned out they weren’t the issue). We pulled in several more people from our infrastructure teams because all debugging and investigation was now hampered by the lack of our usual dashboards and alerts. We still had various internal consoles and status pages available, some command line tools, and our logging infrastructure. Our metrics backends were still up, meaning that we were able to query them directly — however this is nowhere near as efficient as using our dashboards with their pre-built queries. While our infrastructure seemed to generally be up and running, we observed signs that we were seeing widespread network degradation, which we escalated to AWS, our main cloud provider. At this point Slack itself was still up — at 6.57am PST 99% of Slack messages were being sent successfully (but our success rate for message sending is usually over 99.999%, so this was not normal).
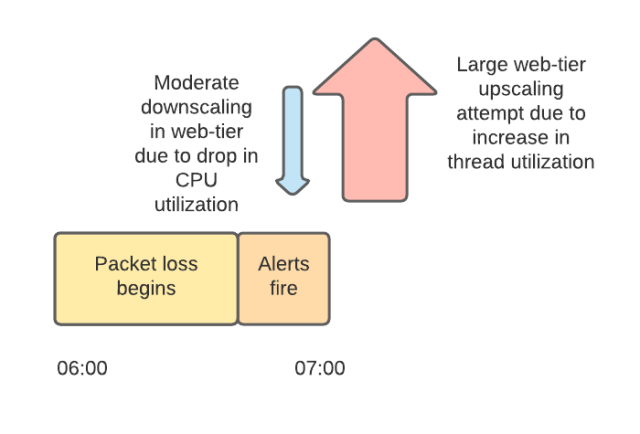
Slack has a traffic pattern of mini-peaks at the top of each hour and half hour, as reminders and other kinds of automation trigger and send messages (much of this is external — cronjobs from all over the world). We manage the scaling of our web tier and backends to accommodate these mini-peaks. However, the mini-peak at 7am PST — combined with the underlying network problems — led to saturation of our web tier. As load increased so did the widespread packet loss. The increased packet loss led to much higher latency for calls from the web tier to its backends, which saturated system resources in our web tier. Slack became unavailable.
Around this time two things happened independently. Some of our instances were marked unhealthy by our automation because they couldn’t reach the backends that they depended on. Our systems attempted to replace these unhealthy instances with new instances. Secondly, our autoscaling system downscaled our web tier. Because we were working without our monitoring dashboards, several engineers were logged into production instances investigating problems at this point. Many of the incident responders on our call had their SSH sessions ended abruptly as the instances they were working on were deprovisioned. This made investigating the widespread production issues even more difficult. We disabled the downscaling to facilitate investigation and to preserve our serving capacity.
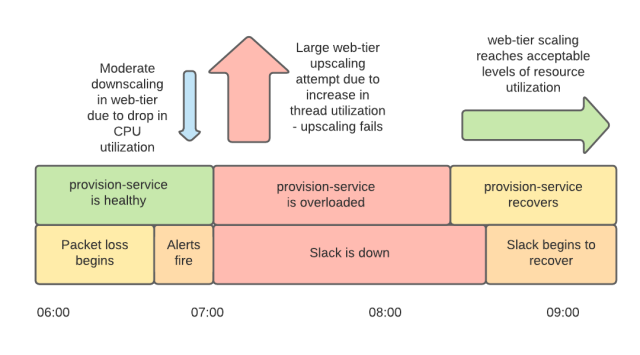
We scale our web tier based on two signals. One is CPU utilization (which is almost universally a useful scaling metric) and the other is utilization of available Apache worker threads. The network problems prior to 7:00am PST meant that the threads were spending more time waiting, which caused CPU utilization to drop. This drop in CPU utilization initially triggered some automated downscaling. However, this was very quickly followed by significant automated upscaling as a result of increased utilization of threads as network conditions worsened and the web tier waited longer for responses from its backends. We attempted to add 1,200 servers to our web tier between 7:01am PST and 7:15am PST.
Unfortunately, our scale-up did not work as intended. We run a service, aptly named ‘provision-service’, which does exactly what it says on the tin. It is responsible for configuring and testing new instances, and performing various infrastructural housekeeping tasks. Provision-service needs to talk to other internal Slack systems and to some AWS APIs. It was communicating with those dependencies over the same degraded network, and like most of Slack’s systems at the time, it was seeing longer connection and response times, and therefore was using more system resources than usual. The spike of load from the simultaneous provisioning of so many instances under suboptimal network conditions meant that provision-service hit two separate resource bottlenecks (the most significant one was the Linux open files limit, but we also exceeded an AWS quota limit).
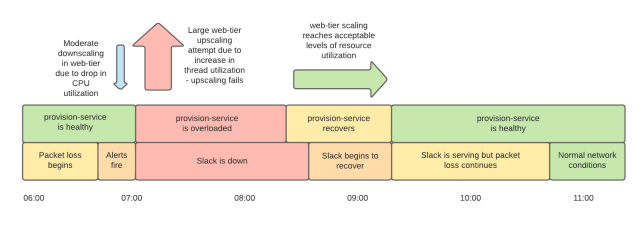
While we were repairing provision-service, we were still under-capacity for our web tier because the scale-up was not working as expected. We had created a large number of instances, but most of them were not fully provisioned and were not serving. The large number of broken instances caused us to hit our pre-configured autoscaling-group size limits, which determine the maximum number of instances in our web tier. These size limits are multiples of the number of instances that we normally require to serve our peak traffic. Some responders cleared these broken instances up while others continued to investigate the widespread connectivity problems. Throughout all this, we were still without our monitoring dashboards — we couldn’t provision new dashboard service instances because provision-service was overloaded.
Once provision-service was back in operation (around 8:15am PST) we began to see an improvement as healthy instances entered service. We still had some less-critical production issues which were mitigated or being worked on, and we still had increased packet loss in our network. However, by 9:15am PST our web tier had a sufficient number of functioning hosts to serve traffic. Our load balancing tier was still showing an extremely high rate of health check failures to our web application instances due to network problems, but luckily, our load balancers have a feature called ‘panic mode’ which balances requests across all instances when many are failing health checks. This — plus retries and circuit breaking — got us back to serving. Slack was slower than normal and error rates were higher, but by around 9:15am PST Slack was degraded, not down. It took an hour to provision enough instances to reduce our error rates to a low level for two reasons. Firstly, because the network still wasn’t completely healthy, we needed more instances than we normally do to serve traffic. Secondly, it took longer than usual to complete that provisioning process, again because the network was not healthy.
By the time Slack had recovered, engineers at AWS had found the trigger for our problems: Part of our AWS networking infrastructure had indeed become saturated and was dropping packets.
A little architectural background is needed here: Slack started life, not so many years ago, with everything running in one AWS account. As we’ve grown in size, complexity, and number of engineers we’ve moved away from that architecture towards running services in separate accounts and in dedicated Virtual Private Clouds (VPCs). This gives us more isolation between different services, and means that we can control operator privileges with much more granularity. We use AWS Transit Gateways (TGWs) as hubs to link our VPCs.
On January 4th, one of our Transit Gateways became overloaded. The TGWs are managed by AWS and are intended to scale transparently to us. However, Slack’s annual traffic pattern is a little unusual: Traffic is lower over the holidays, as everyone disconnects from work (good job on the work-life balance, Slack users!). On the first Monday back, client caches are cold and clients pull down more data than usual on their first connection to Slack. We go from our quietest time of the whole year to one of our biggest days quite literally overnight.
Our own serving systems scale quickly to meet these kinds of peaks in demand (and have always done so successfully after the holidays in previous years). However, our TGWs did not scale fast enough. During the incident, AWS engineers were alerted to our packet drops by their own internal monitoring, and increased our TGW capacity manually. By 10:40am PST that change had rolled out across all Availability Zones and our network returned to normal, as did our error rates and latency.
AWS assures us that they are reviewing the TGW scaling algorithms for large packet-per-second increases as part of their post-incident process. We’ve also set ourselves a reminder (a Slack reminder, of course) to request a preemptive upscaling of our TGWs at the end of the next holiday season.
Monitoring is one of our most critical services — it’s how we know whether our user-facing services are healthy or not — and it is one of our most important tools for diagnosis of problems. We make efforts to keep our monitoring tools as independent of Slack’s infrastructure as possible, so that they don’t fail us when we need them the most. In this case, our dashboard and alerting services failed because they were running in a different VPC from their backend databases, creating a dependency on the TGWs. Running the dashboard service instances in the same VPC as their database will remove this dependency.
Finally, we’ll make sure to regularly load test provision-service to make sure there aren’t any more scaling problems in store (we’ve load tested it in the past but this event exceeded our previous scale-ups). We will also reevaluate our health-checking and autoscaling configurations to prevent inadvertently overloading provision-service again, even in extreme circumstances such as this significant network disruption.
We deeply regret the disruption in service. Every incident is an opportunity to learn, and an unplanned investment in future reliability. We learned a lot from this incident and, as always, we intend to make the most of this unplanned investment to make our infrastructure better in 2021 and beyond.





