


In the first post about the Duplo initiative, we discussed the reasons for launching a project to revamp Slack’s mobile codebases, and what we accomplished in Duplo’s initial Stabilization phase. This post will explore modularization, and then there will be a third post to describe how we modernized our codebase and the overall results of the project.
As we explained in the first post, after Stabilization the goals for the Duplo project were:
- Modularization: breaking apart our app target into smaller components to reduce interdependencies, decrease build times, and allow independent development
- Modernization: adopting more forward-looking technologies and design patterns, to keep us compatible with industry trends and prepare for other technologies we might be interested in using in future
We originally viewed Modularization and Modernization as two separate phases of the Duplo project, but as we got further into planning we realized that doing them sequentially would cause redundant work, as we would have to refactor much of the code twice. In addition, Android had a greater overall focus on Modularization and adoption of newer technologies, rather than an overall re-architecture, so having a separate Modernization phase didn’t make sense. We made the decision to combine these phases and make them a single effort. This second part of the project lasted a year, starting in February of 2021.
While we worked on Modularization and Modernization at the same time, we are going to discuss them in two separate posts, because there is much to be said about each effort.
As we began the second part of the project, it wasn’t possible for the smaller Duplo core team — which worked on Stabilization — to take on all the effort involved. We needed support and resourcing from across the product teams as well, to ensure we would be able to make a significant impact on all parts of the codebase. In each pillar (product team), we chose a lead who was responsible for planning their Duplo work. These pillar leads worked with the managers and engineers on their teams to determine how best to modernize their part of the codebase, which features to tackle first, and how to share resources between Duplo and regular feature work.
Involving all the feature teams allowed them to maintain ownership of their code, and ensured developers learned the new design patterns we were adopting with Duplo. There was still a core group of Duplo leads to coordinate the project, help the pillar teams to set goals, and provide advice and help. We held weekly syncs, and of course we also had dedicated Slack channels where we could discuss any issues which came up. The Infrastructure teams on both platforms, in addition to handling their own code, also helped provide extra resources to update other areas of the codebase.
Modularization
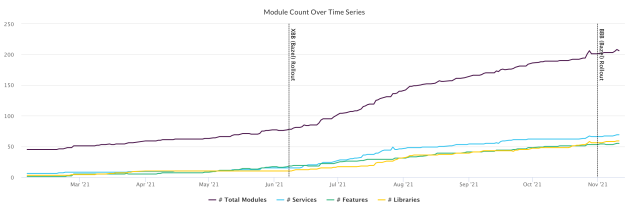
We use the word ‘module’ to describe a subproject — generally a static or dynamic framework linked into the app. Prior to Duplo, we had split off some of our infrastructure code into subprojects on both platforms, but most of the code was still in the main app target, and all feature development was happening there. During Duplo, modularization was a key focus of the project, and we made a concerted push to move code out of the app target.
Modularizing the codebase had many benefits:
- Improving build times, both locally and in CI. On iOS, we found that the overhead of compiling in our large app target meant that just moving a file into a module, with no other changes, could improve the compile time by seconds.
- Allowing developers to build and test their code in smaller targets and reducing the number of files which needed to be rebuilt with any change.
- Improving the overall structure of our codebase through clearer separation of responsibilities and disentangling dependencies.
- Making it easier for our developers to work independently from one another.
Finally, modularization of our codebase made code ownership clearer. Prior to Duplo, we had a large amount of ‘unowned’ code, or code whose ownership was shared by multiple product teams. As we modularized our codebase, we required that each module have a clear owner — one of the product or infrastructure teams on each platform. By doing this, as we modularized we drove down the amount of unowned code and clarified feature ownership. This also made it easier to track progress of our migration efforts, by clarifying how many lines of code each team was responsible for, and would need to update.
iOS Modularization
In addition to moving code out of the app target into modules, on iOS we wanted to make stricter definitions around how these modules should be structured and what types of code should go in them. We decided to define three different types of modules: Features, Services, and Libraries.
- Feature modules contain code related to presenting a feature in the app — generally a screen, a part of a screen, or a series of screens, depending on scope. Feature modules implement the new Feature architecture we defined during Duplo (discussed below). Each Feature module has separate Interface and Implementation modules — the Interface module contains protocols and concrete data classes, and the Implementation module contains the implementations of those protocols and any internal helpers or data structures. Features can link against the Interface module of other Features, but not against their Implementations. This prevents Features from becoming tightly coupled, and also means that changing the implementation of one feature should not invalidate the dependencies for another.
- Service modules contain code to perform some specific function, like making API calls, handling persistence, or any other common component which might be used by the app. Services generally do not contain UI code. Services are also split into Interface and Implementation modules, and again we imposed linking rules, so Service Implementations cannot be linked by other Service & Feature modules.
- Library modules are collections of concrete data structures, simpler classes, and functions which don’t require the separation between Interface and Implementation. An example of this could be a Library of extensions for built-in system APIs, or simple data models. Libraries live at the bottom of the dependency graph, and generally should only depend on other Libraries.
Bazel adoption
A key part of the Duplo initiative, and a big contributor to its overall success on iOS, was adopting Bazel as our build system. This was especially important to our modularization effort. Before adopting Bazel, we were using XCode to build both locally and in CI. Our app project file was checked into GitHub and edited manually by developers. The process for adding a new framework was complicated, and any project edits often led to merge conflicts which were painful to resolve. After switching to Bazel, we used Bazel build files to define our various targets, modules, and their dependencies. We could generate XcodeGen definitions from the Bazel build graph and then build with XCode, or build with Bazel itself.
This was a huge improvement to our development process. Creating new modules, which was painful and complicated with XCode, became simple and easy with Bazel (with tooling help from our Developer Experience team). Merge conflicts in project files became rare and much easier to fix. Prior to Bazel we were linking our frameworks as dynamic libraries, which as the number of modules grew started to cause performance issues with increased pre-main time when launching the app. When we switched to Bazel, we moved to linking these libraries statically instead, which gave us a big performance boost in pre-main times.
Because Bazel supports a shared build cache, breaking our app target down into separate modules is also necessary to fully realize its benefits. If most of our code still lived in a monolithic app target, there would be little benefit to caching it, and any change in the app target would require a lengthy rebuild. But the more we can break down our codebase into smaller modules and clean up our dependency graph, the more benefit the Bazel cache can give us. There is much more to say about our adoption of Bazel, and we will have a follow up blog post going into more depth!
Code generation
Increasing our use of code generation was not one of our initial Duplo goals on iOS, but it ended up being an important outcome of the project. It helped us improve developer experience and productivity, increase consistency, and reduce the need to write boilerplate code. Bazel also made it easier for us to modify build targets programmatically, and add new files to the project just by creating them in the right location. Some of our key use cases were:
- Using scripts and file templates to generate new modules. Developers can run a script to create a new module, only needing to specify the name and type. The script generates the necessary Bazel project definitions and, using templates, creates initial files for the module which can be updated by the developer.
- Using scripts to update our CoreData models and the rest of our low level data frameworks. In order to add a new property, or even an entirely new data model to our data repository, developers can edit a simple Swift file to define the model and run a script, and all of the boilerplate to read and write it to the data layer will be generated for them.
- Creating and modifying feature flags. These used to be a constant source of merge conflicts on PRs as developers added or removed feature flags from a few common files. Once we had scripts to generate the flags, they enforced consistency in feature flag definitions, making it easy to add or remove flags. And there are no more merge conflicts.
There is a lot more we would like to do to adopt code generation more extensively across our codebase going forward, and as we complete Bazel adoption we can take advantage of its more powerful capabilities in this area.
Android Modularization
The Android modularization framework is very similar to iOS. We have Features, Services, and Libraries modules. How each of these types are allowed to depend on others is similar to our approach in iOS. However, there are some differences.
Features
We do not specifically prescribe interface and implementation subproject pairs for each module, in part because it would double the number of subprojects for Gradle to evaluate during project configuration (although a solution is nearly here!). However, we have found API and implementation project pairs very helpful to unwind circular dependencies that arose as code was modularized.
Services
Our guidance for services is that they should implement business logic that spans one or more features and also should generally not contain UI.
Libraries
Libraries modules are intended for very highly reusable pieces of code that don’t necessarily include Slack logic. They could include things like I/O utils, database utils, and internal telemetry libraries.
Dependency injection strategy
At Slack we use Dagger as our dependency injection library of choice. Its compile-time safety, flexibility, and performance are just some of the reasons we love it. Initially, we planned on breaking apart our application’s dependency graph into graphs per subproject module (not to be confused with a Dagger Module) and then stitching them together at the app target level. This would mean every subproject module would declare their own Dagger Components that could ingest any external graph dependency as a component dependency. At the app target level these feature, service, and library components could each be viewed as a factory for a given subproject module’s types and providers written to supply them elsewhere.
If that sounds complicated, it is because it was. While we had hoped this “dependency injection graph of dependency injection graphs” approach would make our application easier to reason about by having smaller graphs to work in, it had the opposite effect. The boilerplate was quite intimidating for all but the Dagger experts. Not only that, but it meant nearly every project compiled more slowly because the Kotlin Annotation Processing Tool (KAPT) had to run for every project. Another problem was how difficult it was to support multibound collections with members contributed from across multiple projects.
Ultimately we discovered the solution lay in Square’s Anvil, and we abandoned our graph-of-graphs approach. Anvil is a library that extends the functionality of Dagger. One of the most important characteristics of Anvil, when it comes to modularization, is that it helps to break apart Dagger definitions that can become huge (e.g. a component with hundreds of modules registered in it, or accessor functions declared to support many different areas).
For us this means any subproject module could contribute a Dagger module, type binding, multibound member, or component interface to the top-level component by simply declaring the scope it wants to contribute to. Not only did this prevent a lot of boilerplate code, but it also saved us lots of compilation time through Anvil’s clever use of Kotlin compiler plugins.
We could go on about how much we love Anvil, but we’ve already written a little bit here.
Gradle optimizations
We chose to continue to invest in our existing build tool, Gradle. We made many investments focused on improving tooling to assist our engineers in modularizing their code and many others in areas to address known build performance issues.
The tooling we created was focused on making it easier to bootstrap new Gradle modules (aka subprojects); instrumenting how well we were modularizing our code, custom DSLs, and plugins to support our standard configurations; and enforcing our project dependency rules.
When it came to improving build times, we took advantage of many new Gradle features. As we created more and more modules, the configuration time of our project grew. This is a pretty well-known Gradle problem. Knowing that configuration caching is an incubating feature, we chose to try it out, helped to troubleshoot some issues, and ultimately enabled it in our project. Currently it is saving us 20-45s on successive builds after a configuration change, and we highly recommend giving it a try in your project.
Another performance improvement we made was reducing our reliance on KAPT. Generally this involved migrating away from many Java-based libraries to their Kotlin successors that utilized Kotlin Symbol Processing (KSP). We removed AutoValue and AutoValueGson in favor of Kotlin data classes, Moshi, and Moshi-IR (experimental). Utilizing Anvil, we were able to eliminate Dagger’s KAPT step in Gradle modules that contributed to our Dagger dependency graph.
All throughout this process, we utilized Gradle Enterprise not only as our distributed build cache, but to inspect where our developers were running into delays. This tool helped us identify caching issues, identify build bottlenecks, and visualize opportunities and progress in our builds.
Conclusion
We started the Duplo project thinking that modularization of our codebases would provide tremendous benefits and should be one of the main focuses of Duplo, and as the initiative progressed it only increased in importance. No other part of the project had a bigger impact on our goals to speed up mobile development and to clean up our codebases.
On both platforms, defining types of modules, enforcing dependency rules, investing in build tooling (Bazel adoption and Gradle investments), and code generation were all key to the success of the modularization effort. In several of these areas, like improvements in build tools and code generation, we will continue to invest more going forward and expect to see further benefit.
There is a final post about the Duplo initiative to discuss Modernization, the overall results of the project, and some next steps!





