

At Slack, we use Terraform for managing our Infrastructure, which runs on AWS, DigitalOcean, NS1, and GCP. Even though most of our infrastructure is running on AWS, we have chosen to use Terraform as opposed to using an AWS-native service such as CloudFormation so that we can use a single tool across all of our infrastructure service providers. This keeps the infrastructure-as-code syntax and deployment mechanism universal. In this post, we’ll have a look at how we deploy our infrastructure using Terraform at Slack.
Evolution of our Terraform state files

Slack started with a single AWS account; all of our services were located in it. In the early days, our Terraform state file structure was very simple: We had a single state file per AWS region and a separate state file for global services, such as IAM and CloudFront.
├── aws-global
│ └── cloudfront
│ ├── services.tf
│ ├── terraform_state.tf
│ ├── variables.tf
│ └── versions.tf
├── us-east-1
│ ├── services.tf
│ ├── terraform.tfvars
│ ├── terraform_state.tf
│ ├── variables.tf
│ └── versions.tf
├── us-west-2
│ ├── services.tf
│ ├── terraform.tfvars
│ ├── terraform_state.tf
│ ├── variables.tf
│ └── versions.tf
├── ap-southest-2
│ ├── services.tf
│ ├── terraform.tfvars
│ ├── terraform_state.tf
│ ├── variables.tf
│ └── versions.tf
└── digitalocean-sfo1
├── services.tf
├── terraform.tfvars
├── terraform_state.tf
├── variables.tf
└── versions.tf
There were identical setups for both production and development environments, however as we started to grow, having all our AWS services in a single account was no longer feasible. Tens of thousands of EC2 instances got built, and we started to run into various AWS rate limits. The AWS EC2 console was unusable in `us-east-1` where a bulk of our workload is located. Also due to the sheer number of teams we have, it was very difficult to manage access control in a single AWS account. This is when we decided to build dedicated AWS accounts for certain teams and services. I have written two other blog posts detailing this progress in Building the Next Evolution of Cloud Networks at Slack and Building the Next Evolution of Cloud Networks at Slack – A Retrospective.
Using Jenkins as a deployment mechanism, once a change is merged to a given state file, we could trigger the corresponding Jenkins pipeline to deploy the change. These pipelines have two stages: one for planning and the other for applying. The planning stage is used to help us validate what the application stage is going to do. We also chain these state files, so we must apply changes in the sandbox and the development environment before proceeding to production environments.

Back in the day, managing the underlying Infrastructure, the Terraform code base, and the state files was the responsibility of the central Ops team. As we started building more child accounts for teams at Slack, the number of Terraform state files grew significantly. Today we no longer have a centralized Ops team. The Cloud Foundations team which I am part of is responsible for managing the Terraform platform, and the Terraform states and pipelines have become the responsibility of service owners. Today we have close to 1,400 Terraform state files owned by different teams. The Cloud Foundations team manages the Terraform versions, provider versions, a set of tools for managing Terraform, and a number of modules that provide basic functionality.
Today we have a state file per region in each child account, and a separate state file for global services such as IAM and CloudFront. However we also tend to build separate isolated state files for larger services, so we can keep the number of resources managed by a single state file to a minimum. This speeds up the deployment time and is safer to make changes to smaller state files as the number of impacted resources is lower.
We use Terraform’s AWS S3 backend to store all our Terraform states in a version-controlled S3 bucket under different paths. We also make use of the state-locking and consistency-checking feature backed by DynamoDB. Having the S3 bucket object versioning enabled on this bucket allows us to roll back to an older version of the state easily.
Where do we run Terraform?

All of our Terraform pipelines run on a set of dedicated Jenkins workers. These workers have IAM roles attached to them with sufficient access to our child accounts so that they can build the necessary resources. However, engineers at Slack also needed a place to test their Terraform changes or prototype new modules. This place has to have an identical environment to the Jenkins workers without the same level of access to enable the modification or creation of resources. Therefore we created a type of box called “Ops” boxes at Slack, where engineers can launch their own “Ops” box using a web interface.

They can choose the instance size, region, and disk capacity before launching the instance. These instances are automatically terminated if they sit idle for an extended period. During the provisioning of these boxes, all our Terraform binaries, providers, wrappers, and related tools are set up on these boxes so that they have an identical environment to our Jenkins workers. However these boxes only have read-only access to our AWS accounts. Therefore they allow our engineers to plan any Terraform changes and validate the plan outputs but are unable to apply them directly via their “Ops” boxes.
How do we deal with Terraform versions?

We started off by supporting one Terraform version. We deployed the Terraform binary and plugins to our Jenkins workers and other places where we run Terraform, via a Chef configuration management system, and we sourced the binaries from an S3 bucket.
Back in 2019, we upgraded our state files from Terraform 0.11 to 0.12. This was a major version upgrade, as there were syntax changes between these two versions. At the time, we spent an entire quarter doing this upgrade. Modules had to be copied with an `-v2` suffix to support the new version of Terraform. We wrote a wrapper for the Terraform binaries which would check the `version.tf` file in each Terraform state file and choose the correct binary. Once all our state files were upgraded, we cleaned up the 0.11 binary and the wrapper changes that were made. Overall this was a very painful and lengthy process.
We stuck with Terraform 0.12 for almost two years before considering upgrading to 0.13. This time around, we wanted to put tooling in place to make any future changes easier. However, to make matters more complicated, the AWS provider version 4.x was also released around the same time, and we were using version 3.74.1. There were many breaking changes between the AWS provider 3.74.1 and 4.x versions. We decided to take up the challenge and upgrade the Terraform binary and the AWS provider at the same time.
Even though there were newer versions of Terraform available (0.14 and 1.x), the recommended upgrade path was to upgrade to version 0.13 and then upwards. We wanted to implement a system to deploy multiple versions of Terraform binaries and plugins and choose the versions we needed based on the state file. Therefore we introduced a Terraform version config file that was deployed to each box.
{
"terraform_versions":
[
"X.X.X",
"X.X.X"
],
"package_plugins":
[
{
"name": "aws",
"namespace": "hashicorp",
"versions" : [
"X.X.X",
"X.X.X"
],
"registry_url": "registry.terraform.io/hashicorp/aws"
},
{
"name": "azurerm",
"namespace": "hashicorp",
"versions" : [
"X.X.X"
],
"registry_url": "registry.terraform.io/hashicorp/azurerm"
},
We started deploying multiple versions of the Terraform binary and the providers. The Terraform wrapper was updated to read the `versions.tf` file in each state file and choose which version of the Terraform binary to use.
Since Terraform 0.13+ allows us to have multiple versions of the same provider under the plugin directory, we deployed all the versions used by our state files to the plugin directory.
└── bin
├── registry.terraform.io
│ ├── hashicorp
│ │ ├── archive
│ │ │ └── X.X.X
│ │ │ └── linux_amd64
│ │ │ └── terraform-provider-archive
│ │ ├── aws
│ │ │ ├── X.X.X
│ │ │ │ └── linux_amd64
│ │ │ │ └── terraform-provider-aws
│ │ │ └── X.X.X
│ │ │ └── linux_amd64
│ │ │ └── terraform-provider-aws
│ │ ├── azuread
│ │ │ └── X.X.X
│ │ │ └── linux_amd64
│ │ │ └── terraform-provider-azuread
│ │ ├── azurerm
│ │ │ └── X.X.X
│ │ │ └── linux_amd64
│ │ │ └── terraform-provider-azurerm
This allowed us to upgrade our Terraform binary version and the AWS provider versions at the same time. If there were any breaking changes with the later version of the provider, we could pin the provider back to the previous version for a given state file. Then we were able to slowly upgrade these specific state files to the latest version of the provider.
Once all the state files were upgraded to the latest versions of the providers, we removed all the pined versions. This allowed the state files to use the latest version of a provider available. We encouraged service teams to avoid pinning to a specific version of a provider unless there was a compelling reason to do so. As new versions of providers become available, the Cloud Foundations team deploy these new versions and remove any out-of-date versions.
This time around, we built a tool to help us manage our Terraform upgrades. We were able to run this tool for a given state; it does the following:
- Checks the current version
- Checks for any unapplied changes
- Checks if there are any other state files that have remote-state lookups to the state file (Terraform 0.12 is unable to do remote-state lookups to Terraform 0.13+ state files and this can potentially break some state files)
- Checks if the state file is able to run a Terraform plan after the upgrade
The initial version of the tool was a simple Bash script. However as we added more checks and logic into the script, it started to get very complex and hard to follow. Reading Terraform syntax with Bash is not fun, and involves a lot of string matching and `grep` commands.
We eventually ended up replacing this script with a Golang binary. Golang’s hclsyntx and gohcl libraries made it so much easier to read our Terraform configuration and load items into Go data structures. Golang’s terraform-exec library made it easier to run Terraform plans and check for errors. We also built in state file analysis capabilities to this binary, such as being able to check module dependency trees.
agunasekara@ops-box:service_dev (branch_name) >> terraform-upgrade-tool -show-deps
INFO[0000] welcome to Terraform upgrade tool
INFO[0000] dependency tree for this state file as follows
terraform/accnt-cloudeng-dev/us-east-1/service_dev
└── terraform/modules/aws/whitecastle-lookup
│ ├── terraform/modules/aws/aws_partition
└── terraform/modules/slack/service
└── terraform/modules/aws/alb
│ ├── terraform/modules/aws/aws_partition
└── terraform/modules/aws/aws_partition
└── terraform/modules/aws/ami
│ ├── terraform/modules/aws/aws_partition
└── terraform/modules/aws/autoscaling
This made it easier to see which modules are impacted by a given state file upgrade.
Once we gained confidence in the tool, we added the ability to upgrade a percentage of our Terraform state files in a single run. To build the tooling and perform the 0.13 upgrade was a time-consuming project but it was worth it as now we are in the process of upgrading our Terraform version again and this time it has been smooth sailing.
How do we manage modules?

We have our Terraform state files and modules in a single repository and use GitHub’s CODEOWNERS functionality to assign reviews of a given state file to the relevant team.
For our modules, we used to have the relative directory path as the module path.
module "service_dev" {
source = "../../../modules/slack/service"
whitecastle = true
vpc_id = local.vpc_id
subnets = local.public_subnets
pvt_subnets = local.private_subnetsEven though this approach makes testing module changes very easy, it is also quite risky as it can break other state files using the same module.
Then we also looked at using the GitHub path approach.
module "network" {
source = "git::git@github-url.com:slack/repo-name//module_path?ref=COMMIT_HASH"
network_cidr_ranges = var.network_cidr_ranges
Private_subnets_cidr_blocks = var.private_subnets_cidr_blocks
public_subnets_cidr_blocks = var.public_subnets_cidr_blocksWith this approach, we were able to pin a state file to a specific version of a module; however, there was a big disadvantage. Each Terraform Plan/Apply has to clone the entire repository (remember, we have all our Terraform code in a single repository) and this was very time consuming. Also Git hashes are not very friendly to read and compare.
Our own module catalog
We wanted a better and simpler way to manage our modules and therefore developed some internal tooling to manage this. Now we have a pipeline that gets triggered every time a change is merged to the Terraform repository. This pipeline checks any module changes, and if it finds one, it will create a new Tarball of the module and upload it to a S3 bucket with a new version.
agunasekara@ops-box:~ >> aws s3 ls s3://terraform-registry-bucket-name/terraform/modules/aws/vpc/
2021-12-20 17:04:35 5777 0.0.1.tgz
2021-12-23 12:08:23 5778 0.0.2.tgz
2022-01-10 16:00:13 5754 0.0.3.tgz
2022-01-12 14:32:54 5756 0.0.4.tgz
2022-01-19 20:34:16 5755 0.0.5.tgz
2022-06-01 05:16:03 5756 0.0.6.tgz
2022-06-01 05:34:27 5756 0.0.7.tgz
2022-06-01 19:38:21 5756 0.0.8.tgz
2022-06-27 07:47:21 5756 0.0.9.tgz
2022-09-07 18:54:53 5754 0.1.0.tgz
2022-09-07 18:54:54 2348 versions.jsonIt also uploads a file called `versions.json`, which contains a history for a given module.
agunasekara@ops-box:~ >> jq < versions.json
{
"name": "aws/vpc",
"path": "terraform/modules/aws/vpc",
"latest": "0.1.0",
"history": [
{
"commithash": "xxxxxxxxxxxxxxxxxxxxxxxxx",
"signature": {
"Name": "Archie Gunasekara",
"Email": "agunasekara@email.com",
"When": "2021-12-21T12:04:08+11:00"
},
"version": "0.0.1"
},
{
"commithash": "xxxxxxxxxxxxxxxxxxxxxxxxx",
"signature": {
"Name": "Archie Gunasekara",
"Email": "agunasekara@email.com",
"When": "2022-09-08T11:26:17+10:00"
},
"version": "0.1.0"
}
]
}
We also built a tool called `tf-module-viewer` that makes it easy for teams to list versions of a module.
agunasekara@ops-box:~ >> tf-module-viewer module-catalogue
Search: █
? Select a Module:
aws/alb
aws/ami
aws/aurora
↓ aws/autoscaling
With this new module catalog approach, we can now pin our modules with the path `vendored_modules` and our Terraform binary wrappers will copy these modules from the catalog S3 path when Terraform init is run.
module "service_dev" {
source = "../../../vendored_modules/slack/service"
whitecastle = true
vpc_id = local.vpc_id
subnets = []
pvt_subnets = local.private_subnetsThe Terraform binary wrapper reads the required version of the module from a configuration file. Then it downloads the required versions of the modules to the `vendored_modules` path before init-ing Terraform.
modules:
aws/alb: 0.1.0
aws/ami: 0.1.9
aws/aurora: 0.0.6
aws/eip: 0.0.7Is this perfect? No…

Not all our state files use this approach. It’s only implemented for the ones with tight compliance requirements. The other state files still reference the modules directly using a relative path in the repository. In addition, the module catalog approach makes it harder to test changes quickly, as the module change must be made first and uploaded to the catalog before a state file can reference it.
Terraform modules can have multiple outputs and conditional resources and configurations. When a module is updated and uploaded to the catalog, there is a tool called Terraform Smart Planner (we will talk more about this later) that will prompt the user to test all state files that are using this module by unpinning it. However this is not enforced, and a change may break certain state files, but may work for others. Users of this module would not find out about these issues until they update the pinned module version to use the latest. Even though the rollback is as easy as reverting back to an earlier version, this is still an inconvenience and a patched version of the module would then need to be uploaded to the catalog before attempting to make use of this newer version.
How do we build pipelines for our Terraform state files?

As I mentioned above, we use Jenkins for our Terraform deployments. With hundreds of state files, we have hundreds of pipelines and stages. We use an in-house Groovy library with Jenkins Job DSL plugins to create these pipelines. When a team is building a new state file, they either create a brand new pipeline or add this as a stage to an existing pipeline. This was accomplished by adding a DSL script to a directory that Jenkins reads on a schedule and builds all our pipelines. However this is not a very user-friendly experience, as writing Groovy to build a new pipeline is time consuming and error prone.
However an awesome engineer in my team named Andrew Martin used his innovation day to solve this problem. He built a small program that reads a simple YAML file and builds these complex DSL scripts that Jenkins can use to build its pipelines. This new approach made creating new Terraform state pipelines a breeze.
pipelinename: Terraform-Deployment-rosi-org-root
steps:
- path: accnt-rosi-org-root/env-global
- path: accnt-rosi-org-root/us-east-1
- path: accnt-rosi-org-root/env-global/organizational-units-and-scps/sandbox
next:
- path: accnt-rosi-org-root/env-global/organizational-units-and-scps/dev
next:
- path: accnt-rosi-org-root/env-global/organizational-units-and-scps/prod-staging
next:
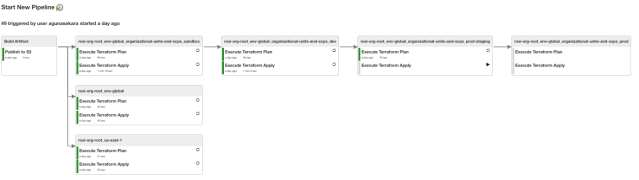
- path: accnt-rosi-org-root/env-global/organizational-units-and-scps/prodThe configuration above will create a pipeline like below in Jenkins.
How do we test Terraform changes?

As I mentioned before, each Terraform state file has a planning stage in their pipeline. This stage must be able to successfully compete before proceeding to the apply stage. However for this to happen changes must already be merged to the master branch of the Terraform repository, and unfortunately, if a bad change gets merged, the pipeline is broken and blocked. Also if a bad change to a widely used module gets merged, several state files may be impacted.
To fix this, we introduced a tool called Terraform Smart Planner. Once a change is made to the Terraform repository, we can execute this tool. Terraform Smart Planner will look for all impacted state files by this change, run plans against each one, and post the output to the pull request. The Terraform Smart Planner works in a similar fashion when a module is updated as well. However it will prompt the user to unpin any modules that are pinned using the module catalog as we discussed earlier, if those modules have any changes made to them.
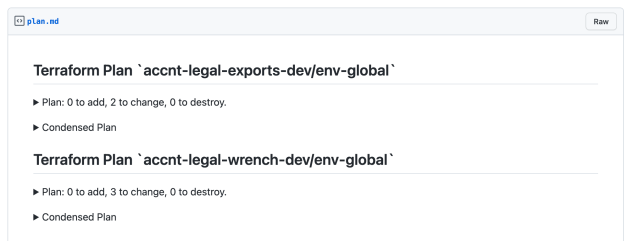
Having this output on a pull request body is incredibly helpful for the reviewers as they can see what resources are impacted by a given change. It also helps to discover any indirectly impacted state files and any changes to the resources in them. This allows us to confidently approve a pull request and request further changes.
We also run a similar CI check for each pull request and block merges to anything with broken Terraform plans.
Some final words

Our Terraform usage is far from perfect, and there are a lot of improvements we can make to improve the user experience. The Cloud Foundations team is working closely with service teams across Slack to collect feedback and make improvements to the processes and tools that manage our infrastructure. We have also written our own Terraform providers to manage our unique services while making contributions to open-source providers. There is a lot of exciting work going on in this space right now and if you feel like this is something you’d be interested in, please keep an eye on our careers page.





