

In a previous blog post—A Simple Kubernetes Admission Webhook—I discussed the process of creating a Kubernetes webhook without relying on Kubebuilder. At Slack, we use this webhook for various tasks, like helping us support long-lived Pods (see Supporting Long-Lived Pods), and today, I delve once more into the topic of long-lived Pods, focusing on our approach to deploying stateful applications through custom resources managed by Kubebuilder.
Lack of control
Many of our teams at Slack use StatefulSets to run their applications with stateful storage, so StatefulSets are naturally a good fit for distributed caches, databases, and other stateful services that rely on unique Pod identity and persistent external volumes.
Natively in Kubernetes, there are two ways of rolling out StatefulSets, two update strategies, set via the .spec.updateStrategy field:
OnDelete
- When a StatefulSet's .spec.updateStrategy.type is set to OnDelete, the StatefulSet controller will not automatically update the Pods in a StatefulSet. Users must manually delete Pods to cause the controller to create new Pods that reflect modifications made to a StatefulSet's .spec.template.
RollingUpdate
- The RollingUpdate update strategy implements automated, rolling updates for the Pods in a StatefulSet. This is the default update strategy.
RollingUpdate comes packed with features like Partitions (percent-based rollouts) and .spec.minReadySeconds to slow down the pace of the rollouts. Unfortunately the maxUnavailable field for StatefulSet is still alpha and gated by the MaxUnavailableStatefulSet api-server feature flag, making it unavailable for use in AWS EKS at the time of this writing.
This means that using RollingUpdate only lets us roll out one Pod at a time, which can be excruciatingly slow to deploy applications with hundreds of Pods.
OnDelete however lets the user control the rollout by deleting the Pods themselves, but does not come with RollingUpdate’s bells and whistles like percent-based rollouts.
Our internal teams at Slack were asking us for more controlled rollouts: they wanted faster percent-based rollouts, faster rollbacks, the ability to pause rollouts, an integration with our internal service discovery (Consul), and of course, an integration with Slack to update teams on rollout status.
Bedrock rollout operator
So we built the Bedrock Rollout Operator: a Kubernetes operator that manages StatefulSet rollouts. Bedrock is our internal platform; it provides Slack engineers opinionated configuration for Kubernetes deployments via a simple config interface and powerful, easy-to-use integrations with the rest of Slack, such as:
- Consul for service discovery
- Consul-Template / Vault for rendering secrets
- Nebula for secure internal traffic (encryption and firewall)
- Envoy for fine-grained level-7 routing
…and it has nothing to do with AWS’ new generative AI service of the same name!
We built this operator with Kubebuilder, and it manages a custom resource named StatefulsetRollout. The StatefulsetRollout resource contains the StatefulSet Spec as well as extra parameters to provide various extra features, like pause and Slack notifications. We’ll look at an example in a later section in this post.
Architecture
At Slack, engineers deploy their applications to Kubernetes by using our internal Bedrock tooling. As of this writing, Slack has over 200 Kubernetes clusters, over 50 stateless services (Deployments) and nearly 100 stateful services (StatefulSets). The operator is deployed to each cluster, which lets us control who can deploy where. The diagram below is a simplification showing how the pieces fit together:
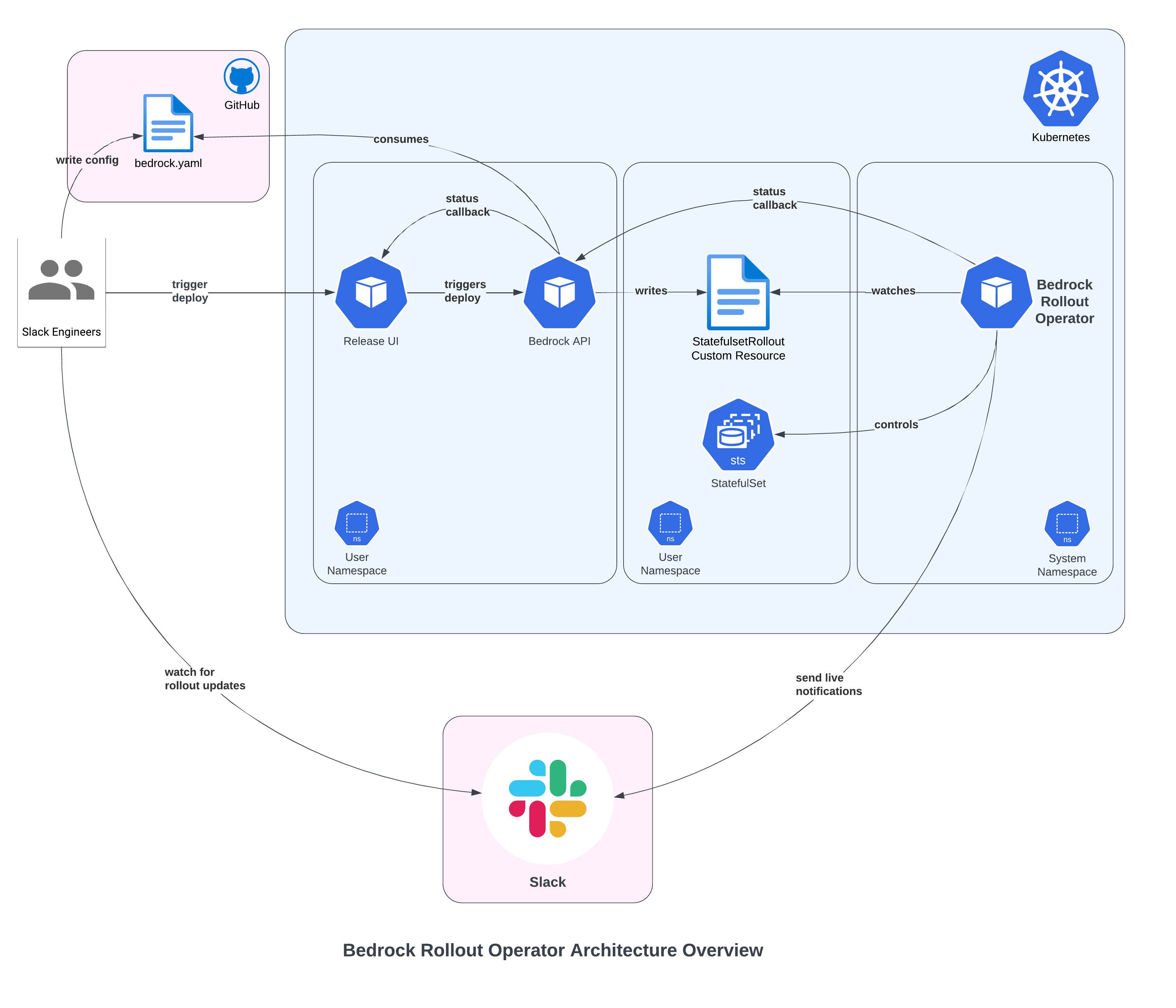
Rollout flow
Following the diagram above, here’s an end-to-end example of a StatefulSet rollout.
1. bedrock.yaml
First, Slack engineers write their intentions in a `bedrock.yaml` config file stored in their app repository on our internal Github. Here’s an example:
images:
bedrock-tester:
dockerfile: Dockerfile
services:
bedrock-tester-sts:
notify_settings:
launch:
level: "debug"
channel: "#devel-rollout-operator-notifications"
kind: StatefulSet
disruption_policy:
max_unavailable: 50%
containers:
- image: bedrock-tester
stages:
dev:
strategy: OnDelete
orchestration:
min_pod_eviction_interval_seconds: 10
phases:
- 1
- 50
- 100
clusters:
- playground
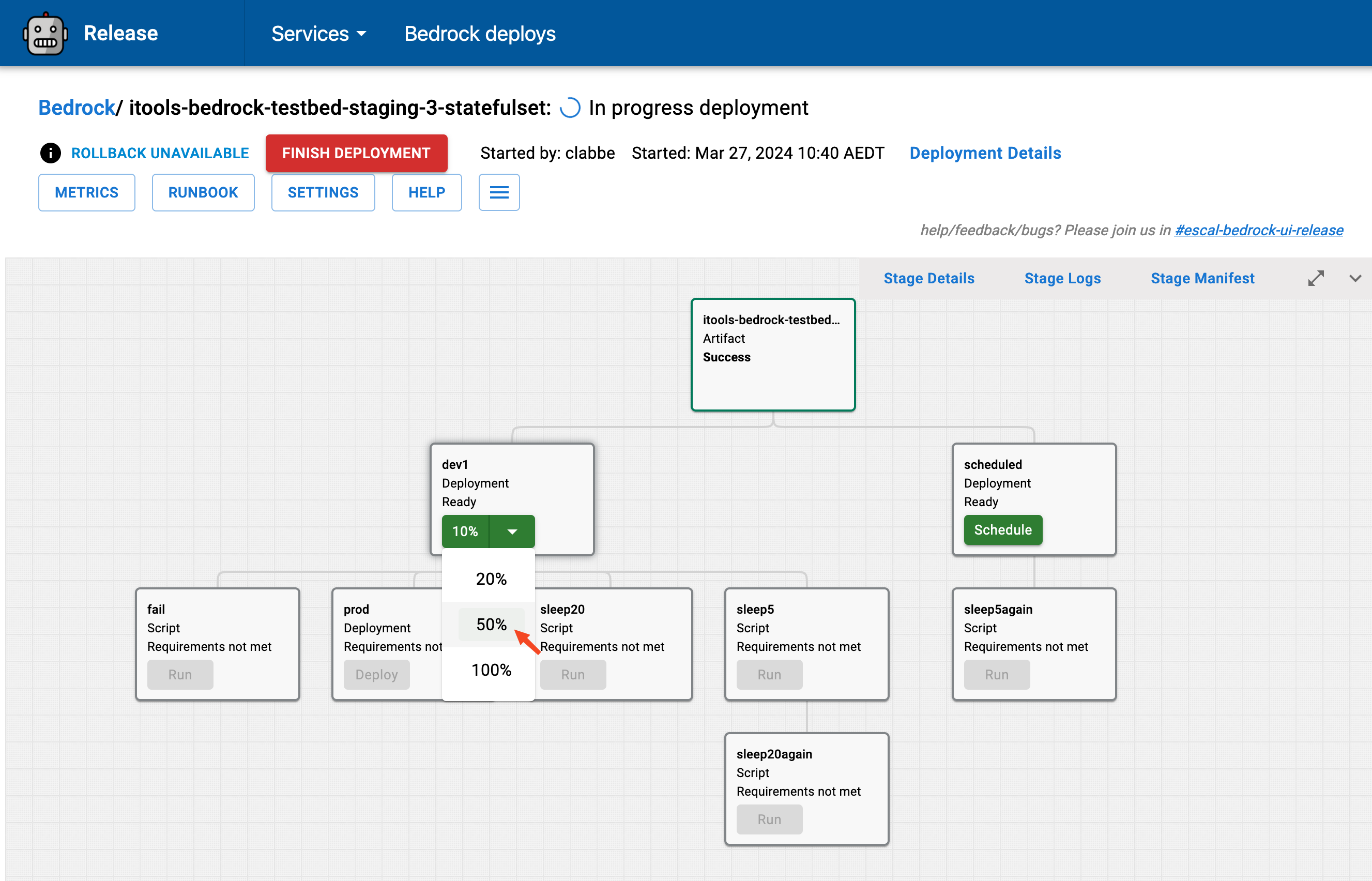
replicas: 22. Release UI
Then, they go to our internal deploy UI to effect a deployment:
3. Bedrock API
The Release platform then calls to the Bedrock API, which parses the user bedrock.yaml and generates a StatefulsetRollout resource:
apiVersion: bedrock.operator.slack.com/v1
kind: StatefulsetRollout
metadata:
annotations:
slack.com/bedrock.git.branch: master
slack.com/bedrock.git.origin: git@internal-github.com:slack/bedrock-tester.git
labels:
app: bedrock-tester-sts-dev
app.kubernetes.io/version: v1.custom-1709074522
name: bedrock-tester-sts-dev
namespace: default
spec:
bapi:
bapiUrl: http://bedrock-api.internal.url
stageId: 2dD2a0GTleDCxkfFXD3n0q9msql
channel: '#devel-rollout-operator-notifications'
minPodEvictionIntervalSeconds: 10
pauseRequested: false
percent: 25
rolloutIdentity: GbTdWjQYgiiToKdoWDLN
serviceDiscovery:
dc: cloud1
serviceNames:
- bedrock-tester-sts
statefulset:
apiVersion: apps/v1
kind: StatefulSet
metadata:
annotations:
slack.com/bedrock.git.origin: git@internal-github.com:slack/bedrock-tester.git
labels:
app: bedrock-tester-sts-dev
name: bedrock-tester-sts-dev
namespace: default
spec:
replicas: 4
selector:
matchLabels:
app: bedrock-tester-sts-dev
template:
metadata:
annotations:
slack.com/bedrock.git.origin: git@internal-github.com:slack/bedrock-tester.git
labels:
app: bedrock-tester-sts-dev
spec:
containers:
image: account-id.dkr.ecr.us-east-1.amazonaws.com/bedrock-tester@sha256:SHA
name: bedrock-tester
updateStrategy:
type: OnDeleteLet’s look at the fields in the top level of the StatefulsetRollout spec, which provide the extra functionalities:
bapi: This section contains the details needed to call back to the Bedrock API once a rollout is complete or has failedchannel: The Slack channel to send notifications tominPodEvictionIntervalSeconds: Optional; the time to wait between each Pod rotationpauseRequested: Optional; will pause an ongoing rollout if set to truepercent: Set to 100 to roll out all Pods, or less for a percent-based deployrolloutIdentity: We pass a randomly generated string to this rollout as a way to enable retries when a rollout has failed but the issue was transient.serviceDiscovery: This section contains the details related to the service Consul registration. This is needed to query Consul for the health of the service as part of the rollout.
Note that the disruption_policy.max_unavailable that was present in the bedrock.yaml does not show up in the custom resource. Instead, it is used to create a Pod disruption policy. At run-time, the operator reads the Pod disruption policy of the managed service to decide how many Pods it can roll out in parallel.
4. Bedrock Rollout Operator
Then, the Bedrock Rollout Operator takes over and converges the existing state of the cluster to the desired state defined in the StatefulsetRollout. See “The Reconcile Loop” section below for more details.
5. Slack notifications
We used Block Kit Builder to design rich Slack notifications that inform users in real time of the status of the ongoing rollout, providing details like the version number and the list of Pods being rolled out:
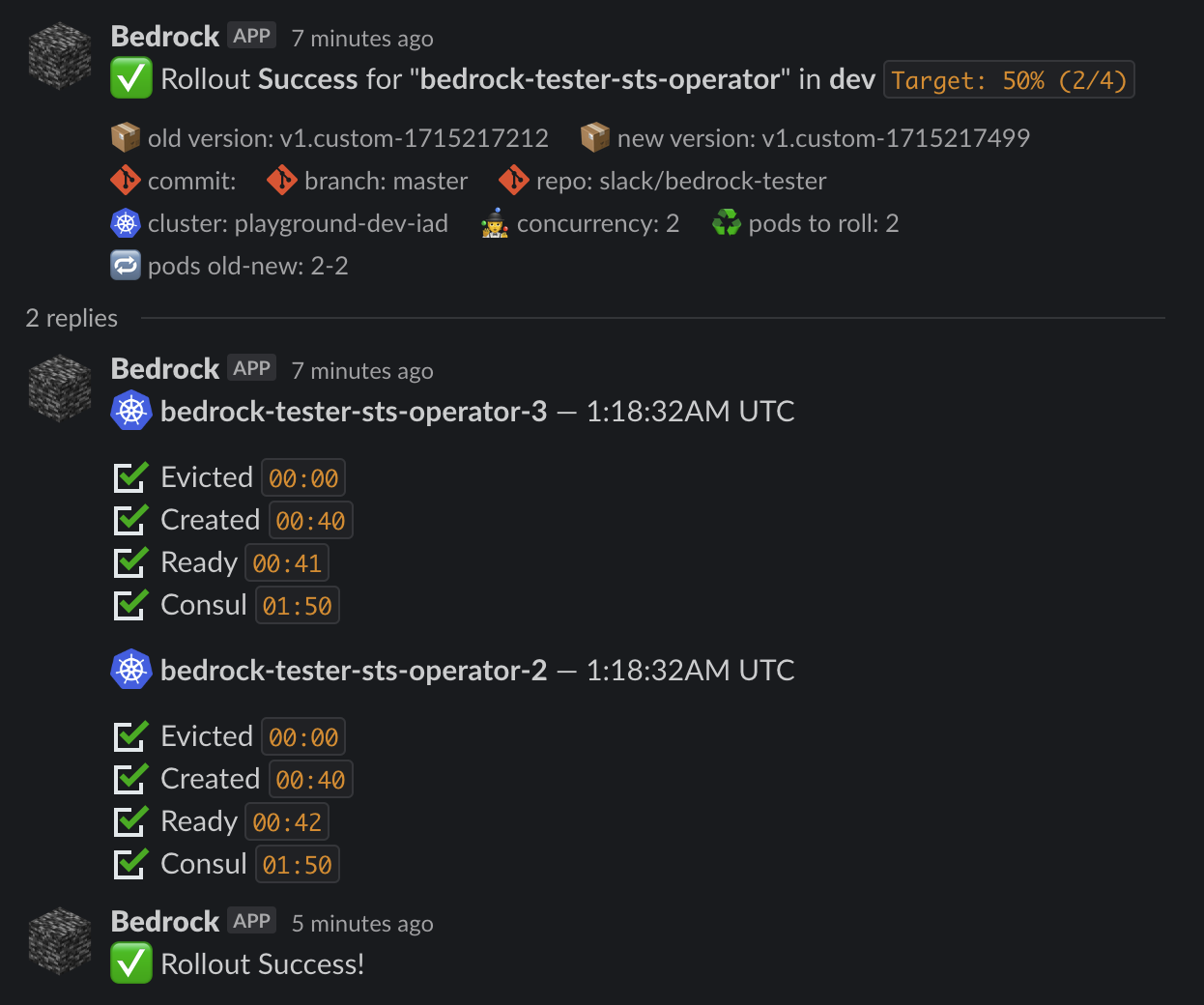
6. Callbacks
While Slack notifications are good for the end users, our systems also need to know the state of the rollout. Once finished converging a StatefulsetRollout resource, the Operator calls back to the Bedrock API to inform it of the success or failure of the rollout. Bedrock API then sends a callback to Release for the status of rollout to be reflected in the UI.
The reconcile loop
The Bedrock Rollout Operator watches the StatefulsetRollout resource representing the desired state of the world, and reconciles it against the real world. This means, for example, creating a new StatefulSet if there isn’t one, or triggering a new rollout. A typical rollout is done by applying a new StatefulSet spec and then terminating a desired amount of Pods (half of them in our percent: 50 example).
The core functionality of the operator lies within the reconcile loop in which it:
- Looks at the expected state: the spec of the custom resource
- Looks at the state of the world: the spec of the StatefulSet and of its Pods
- Takes actions to move the world closer to the expected state, for example by:
- Updating the StatefulSet with the latest spec provided by the user; or by
- Evicting Pods to get them replaced by Pods running the newer version of the application being rolled out
When the custom resource is updated, we begin the reconciliation loop process. Typically after that, Kubernetes controllers watch the resources they look after and work in an event-driven fashion. Here, this would mean watching the StatefulSets and its Pods. Each time one of them gets updated, the reconcile loop would run.
But instead of working in this event-driven way, we decided to work by enqueuing the next reconcile loop ourselves: as long as we’re expecting change, we re-enqueue a request in the future. Once we reach a final state like RolloutDone or RolloutFailed, we simply exit without re-enqueueing. Working in this fashion has a few advantages and leads to a lot less reconciliations. It also enforces reconciliations being done sequentially for a given custom resource, which dodges race conditions brought by mutating a given custom resource in reconcile loops running in parallel.
Here’s a non-exhaustive flow chart illustrating how it works for our StatefulsetRollout (Sroll for short) custom resource:
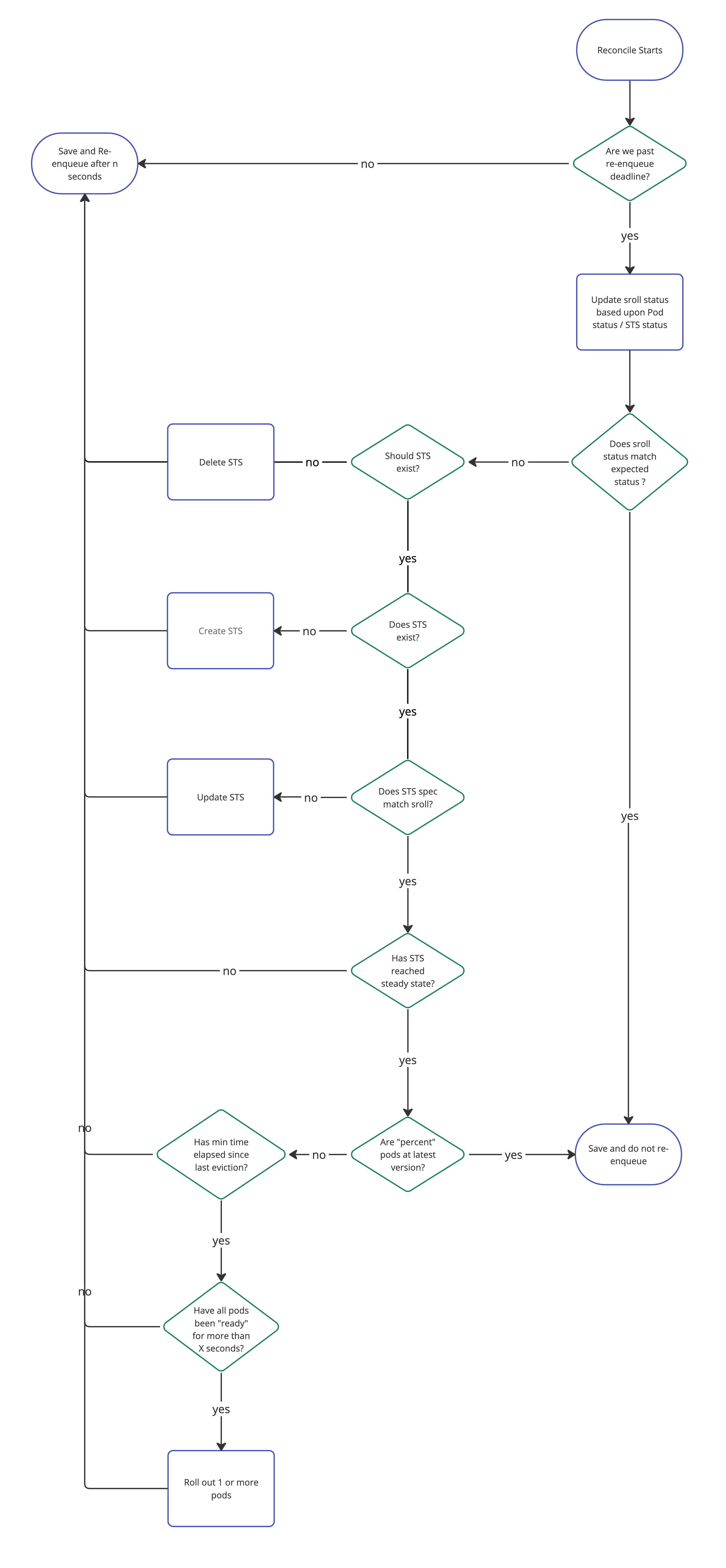
As you can see, we’re trying to do as little as we can in each reconciliation loop: we take one action and re-enqueue a request a few seconds in the future. This works well because it keeps each loop fast and as simple as possible, which makes the operator resilient to disruptions. We achieve this by saving the last decision the loop took, namely the `Phase` information, in the status of the custom resource. Here’s what the StatefulsetRollout status struct looks like:
// StatefulsetRolloutStatus defines the observed state of StatefulsetRollout
type StatefulsetRolloutStatus struct {
// The Phase is a high level summary of where the StatefulsetRollout is in its lifecycle.
Phase RolloutPhase `json:"phase,omitempty"`
// PercentRequested should match Spec.Percent at the end of a rollout
PercentRequested int `json:"percentDeployed,omitempty"`
// A human readable message indicating details about why the StatefulsetRollout is in this phase.
Reason string `json:"reason,omitempty"`
// The number of Pods currently showing ready in kube
ReadyReplicas int `json:"readyReplicas"`
// The number of Pods currently showing ready in service discovery
ReadyReplicasServiceDiscovey int `json:"readyReplicasRotor,omitempty"`
// Paused indicates that the rollout has been paused
Paused bool `json:"paused,omitempty"`
// Deleted indicates that the statefulset under management has been deleted
Deleted bool `json:"deleted,omitempty"`
// The list of Pods owned by the managed sts
Pods []Pod `json:"Pods,omitempty"`
// ReconcileAfter indicates if the controller should enqueue a reconcile for a future time
ReconcileAfter *metav1.Time `json:"reconcileAfter,omitempty"`
// LastUpdated is the time at which the status was last updated
LastUpdated *metav1.Time `json:"lastUpdated"`
// LastCallbackStageId is the BAPI stage ID of the last callback sent
//+kubebuilder:validation:Optional
LastCallbackStageId string `json:"lastCallbackStageId,omitempty"`
// BuildMetadata like branch and commit sha
BuildMetadata BuildMetadata `json:"buildMetadata,omitempty"`
// SlackMessage is used to update an existing message in Slack
SlackMessage *SlackMessage `json:"slackMessage,omitempty"`
// ConsulServices tracks if the consul services specified in spec.ServiceDiscovery exists
// will be nil if no services exist in service discovery
ConsulServices []string `json:"consulServices,omitempty"`
// StatefulsetName tracks the name of the statefulset under management.
// If no statefulset exists that matches the expected metadata, this field is left blank
StatefulsetName string `json:"statefulsetName,omitempty"`
// True if the statefulset under management's spec matches the sts Spec in StatefulsetRolloutSpec.sts.spec
StatefulsetSpecCurrent bool `json:"statefulsetSpecCurrent,omitempty"`
// RolloutIdentity is the identity of the rollout requested by the user
RolloutIdentity string `json:"rolloutIdentity,omitempty"`
}
This status struct is how we keep track of everything and so we save a lot of metadata here —everything from the Slack message ID, to a list of managed Pods that includes which version each is currently running.
Limitations and learning
Supporting large apps
Slack manages a significant amount of traffic, which we back with robust services operating on our Bedrock platform built on Kubernetes:
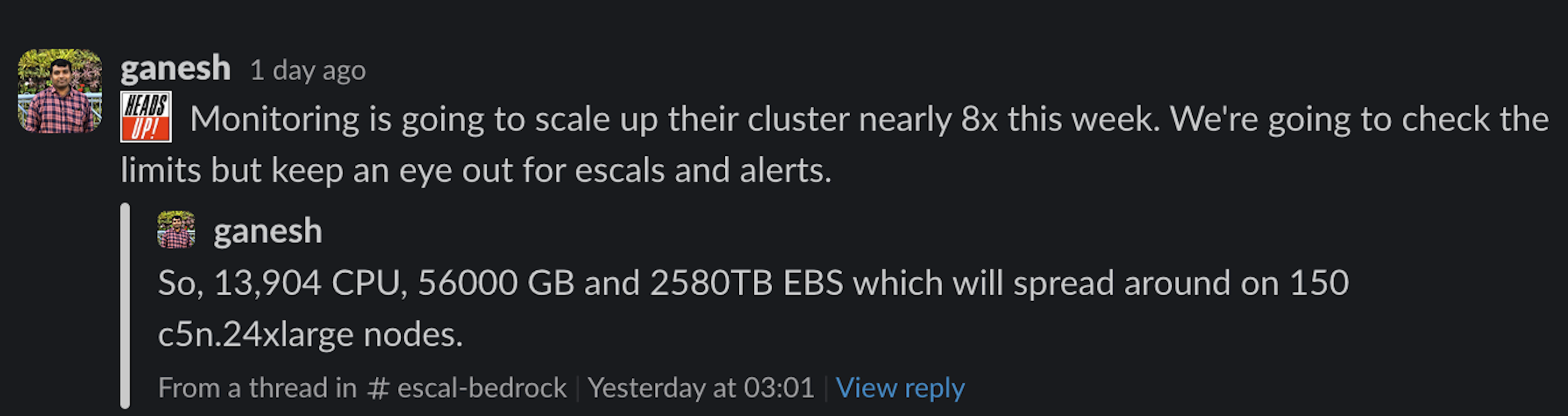
This gives an example of the scale we’re dealing with. Yet, we got surprised when we found that some of our StatefulSets spin up to 1,000 Pods which caused our Pod by Pod notifications to get rate limited as we were sending one Slack message per Pod, and rotating up to 100 Pods in parallel! This forced us to rewrite the notifications stack in the operator: we introduced pagination and moved to sending messages containing up to 50 Pods.
Version leak
Some of you might have picked up on a not-so-subtle detail related to the (ab-)use of the OnDelete strategy for StatefulSets: what we internally call the version leak issue. When a user decides to do a percent-based rollout, or pause an existing rollout, the StatefulSet is left with some Pods running the new version and some Pods running the previous version. But if a Pod running the previous version gets terminated for any other reason than being rolled out by the operator, it’ll get replaced by a Pod running the new version. Since we routinely terminate nodes for a number of reasons such as scaling clusters, rotating nodes for compliance as well as chaos engineering, a stopped rollout will, over time, tend to converge towards being fully rolled out. Fortunately, this is a well-understood limitation and Slack engineering teams deploy their services out to 100% in a timely manner before the version leak problem would arise.
What’s next?
We have found the Kubernetes operator model to be effective, so we have chosen to manage all Kubernetes deployments using this approach. This doesn’t necessarily involve extending our StatefulSet operator. Instead, for managing Deployment resources, we are exploring existing CNCF projects such as Argo Rollouts and OpenKruise.
Conclusion
Implementing custom rollout logic in a Kubernetes operator is not simple work, and incoming Kubernetes features like the maxUnavailable field for StatefulSet might, one day, let us pull out some of our custom code. Managing rollouts in an operator is a model that we’re happy with, since the operator allows us to easily send Slack notifications for the state of rollouts as well as integrate with some of our other internal systems like Consul. Since this pattern has worked well for us, we aim to expand the use of the operator in the future.
Love Kube and deploy systems? Come join us!
Apply now


