

Slack has a global customer base, with millions of simultaneously connected users at peak times. Most of the communication between users involves sending lots of tiny messages to each other. For much of Slack’s history, we’ve used HAProxy as a load balancer for all incoming traffic. Today, we’ll talk about problems we faced with HAProxy, how we solved them with Envoy Proxy, the steps involved in the migration, and what the outcome was. Let’s dive in!
Websockets at Slack
To deliver messages instantly, we use a websocket connection, a bidirectional communications link which is responsible for you seeing “Several people are typing…” and then the thing they typed, nearly as fast as the speed of light permits. The websocket connections are ingested into a system called “wss” (WebSocket Service) and accessible from the internet using wss-primary.slack.com and wss-backup.slack.com (it’s not a website, you just get a HTTP 404 if you go there).
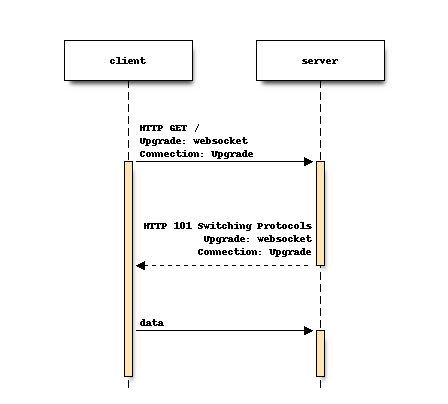
Websocket connections start out as regular HTTPS connections, and then the client issues a protocol switch request to upgrade the connection to a websocket. At Slack, we have different websocket services dedicated to messages, to presence (listing which contacts are online), and to other services. One of the websocket endpoints is specifically made for apps that need to interact with Slack (because apps want real-time communication too).
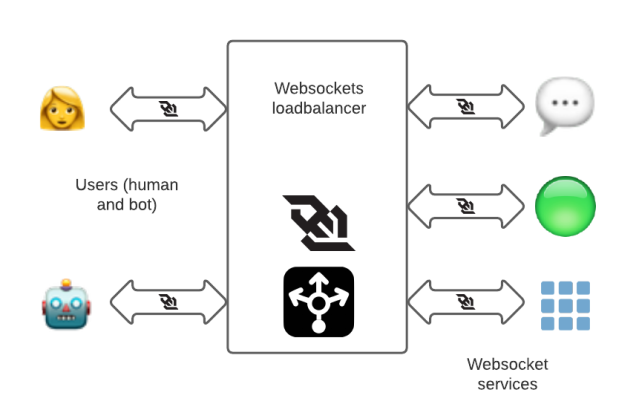
In the past, we had a set of HAProxy instances specifically dedicated to websockets in multiple AWS regions to terminate websocket connections close to the user and forward the request to corresponding backend services.
Motivation to migrate to Envoy Proxy
While we have been using HAproxy since the beginning of Slack and knew how to operate it at scale, there were some operational challenges that made us consider alternatives, like Envoy Proxy.
Hot Restarts
At Slack, it is a common event for backend service endpoint lists to change (due to instances being added or cycled away). HAProxy provides two ways to update its configuration to accommodate changes in endpoint lists. One is to use the HAProxy Runtime API. We used this approach with one of our sets of HAProxy instances, and our experience is described in another blog post — A Terrible, Horrible, No-Good, Very Bad Day at Slack. The other approach, which we used for the websockets load balancer (LB), is to render the backends into the HAProxy configuration file and reload HAProxy.
With every HAProxy reload, a new set of processes is created to handle the new incoming connections. We’d keep running the old process for many hours to allow long-lived websocket connections to drain and avoid frequent disconnections of users. However, we can’t have too many HAProxy processes each running with it’s own “at the time” copy of the configuration — we wanted instances to converge on the new version of the configuration faster. We had to periodically reap old HAProxy processes, and restrict how often HAProxy could reload in case there was a churn in underlying backends.
Whichever approach we used, it needed some extra infrastructure in place for managing HAProxy reloads.
Envoy allows us to use dynamically configured clusters and endpoints, which means it doesn’t need to be reloaded if the endpoint list changes. If code or configuration do change, Envoy has the ability to hot restart itself without dropping any connections. Envoy watches filesystem configurations with inotify for updates. Envoy also copies statistics from the parent process to the child process during a hot restart, so gauges and counters don’t get reset.
This all adds up to a significant reduction in operational overhead with Envoy, and no additional services needed to manage configuration changes or restarts.
Load Balancing Features
Envoy provides several advanced load-balancing features, such as:
- Built-in support for zone-aware routing
- Passive health checking via Outlier Detection
- Panic Routing – Envoy will generally route traffic only to healthy backends, but it can be configured to send traffic to all backends, healthy or unhealthy, if the percentage of healthy hosts drops below a threshold. This was very helpful during our January 4, 2021 outage, which was caused by a widespread network problem in our infrastructure.
Because of the above reasons, in 2019, we decided to migrate our ingress load balancing tier from HAproxy to Envoy Proxy, starting with the websockets stack. The major goals of the migration were improved operability, access to new features that Envoy provides, and more standardization. By moving from HAProxy to Envoy across all of Slack, we would eliminate the need for our team to know the quirks of two pieces of software, to maintain two different kinds of configuration, to manage two build and release pipelines, and so on. By then, we were already using Envoy Proxy as the data plane in our service mesh. We also have experienced Envoy developers in-house, so we have ready access to Envoy expertise.
Generating Envoy configuration
The first step in this migration was to review our existing websocket tier configuration and generate an equivalent Envoy configuration. Managing Envoy configuration was one of our biggest challenges during the migration. Envoy has a rich feature set, and its configurations are quite different to those of HAProxy. Envoy configuration deals with four main concepts:
- Listeners, which receive requests, aka TCP sockets, SSL sockets, or unix domain sockets
- Clusters, representing the internal services that we send requests to, like message servers and presence servers
- Routes, which glue listeners and clusters together
- Filters, which operate on requests
Configuration management at Slack is primarily done via Chef. When we started with Envoy, we deployed envoy configuration as a chef template file, but it became cumbersome and error-prone to manage. To solve this problem, we built chef libraries and custom resources for generating Envoy configurations. 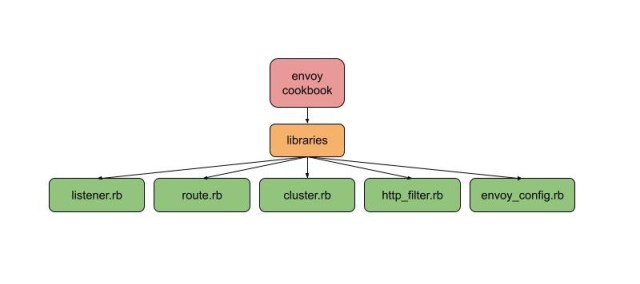 Inside Chef, the configuration is a Singleton, modelling the fact that there is only one Envoy configuration per host. All Chef resources operate on that singleton, adding the listeners, routes, or clusters. At the end of the chef run, the envoy.yaml gets generated, validated, and then installed — we never write intermediate configurations, because these could be invalid.
Inside Chef, the configuration is a Singleton, modelling the fact that there is only one Envoy configuration per host. All Chef resources operate on that singleton, adding the listeners, routes, or clusters. At the end of the chef run, the envoy.yaml gets generated, validated, and then installed — we never write intermediate configurations, because these could be invalid.
This example shows how we can create one HTTP listener with two routes that routes traffic to two dynamic clusters.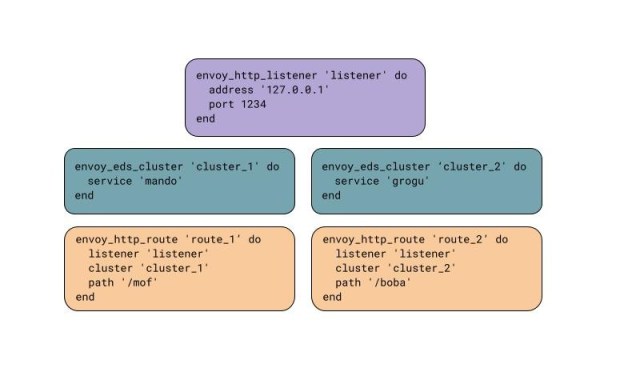
It took some effort to replicate our complicated HAProxy configuration in Envoy. Most of the features needed were already available in Envoy so it was just a matter of adding the support for it to the chef library and voila! We implemented a few missing Envoy features (some were contributed upstream and some are maintained in-house as extensions).
Testing and validation of our new configuration
Testing the new Envoy websockets tier was an iterative process. We often prototyped with hand-coded Envoy configurations and tested it locally on a development machine with one listener, route, and cluster each. Hand-coded changes, once they worked, would be moved into the chef libraries.
HTTP routing was tested with curl:
- Specific header- and cookie-based routing to specific backends
- Path-, prefix-, and query-param-based routing to specific backends
- SSL certificates
We used Envoy debug logging locally on the machine when things didn’t work as expected: Debug logging explains clearly why Envoy chose to route a specific request to a specific cluster. Envoy debug log is very helpful but also verbose and expensive (you really don’t want to enable that in your production environment). Debug logging can be enabled via Curl as shown below:
curl -X POST http://localhost:<envoy_admin_port>/logging?level=debug
The Envoy admin interface is also useful in initial debugging, particularly these endpoints:
- /clusters – Displays all configured clusters including information about all upstream hosts in each cluster along with per host statistics.
- /certs – Displays all loaded TLS certificates, including file name, serial number, subject alternate names and days until expiration in JSON format.
- /listeners – Displays all configured listeners along with their names and addresses.
Our Chef libraries run Envoy with the `–mode validate` command-line option as a validation step, in order to prevent installation of invalid configurations. This can also be done manually:
sudo /path/to/envoy/binary -c </path/to/envoy.yaml> --mode validate
Envoy provides JSON formatted listener logs. We ingest those logs into our logging pipeline (after sanitizing the logs for PII, of course) and this has often been helpful for debugging.
Once confident with config in our development environment, we were ready to do some more testing — in production!
Migration to production
In order to minimize risk during the migration, we built a new Envoy websocket stack with an equivalent configuration to the existing HAProxy tier. This meant that we could do a gradual, controlled shift of traffic to the new Envoy stack, and that we could quickly switch back to HAProxy if necessary. The downside was our AWS cost — we were using double the resources during the migration but we were willing to spend the time and resources to do this migration transparently for our customers.
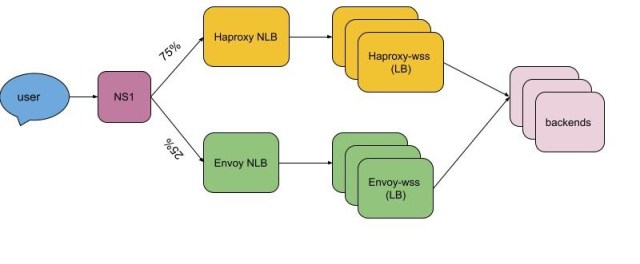
We manage our DNS records wss-primary.slack.com and wss-backup.slack.com via NS1. We used weighted routing to shift traffic from haproxy-wss to envoy-wss NLB DNS names. The first regions were rolled out individually in steps of 10%, 25%, 50%, 75%, and 100%. The final regions were done faster (25%, 50%, 75%, 100% in just two days compared to prior one region over the course of a week), as we had confidence in the new Envoy tier and in the rollout process.
Even though the migration was smooth and outage-free, there were a number of minor problems that cropped up, such as differences in timeout values and headers. We reverted, fixed, and rolled out again multiple times during the migration.
After a very long and exciting 6 months, the migration was complete and the entire HAProxy websocket stack was replaced with Envoy Proxy globally with zero customer impact.
What went well and what didn’t
The migration itself was relatively uneventful and boring. Boring is a good thing: exciting means things break, boring means things keep working.
We found that the old HAProxy config had grown organically over time. It was largely shaped by the model that HAProxy uses — one large configuration that includes all listeners. Envoy’s configuration model uses much more defined scopes than HAProxy’s model. Once a listener is entered, only the rules inside that listener apply to the requests. Once a route is entered, only rules on that route apply. This makes it much easier to associate rules with the relevant requests.
It took a lot of time to extract what was important in the old HAProxy configuration from what was effectively technical debt. It was often difficult to figure out why a certain rule was in place, what was intentional as opposed to unintentional, and what behavior other services relied on. For example, some services were supposed to only be under one of two virtual hosts (vhosts), but were actually available under both vhosts in HAProxy. We had to replicate this mistake, because existing code relied on that behavior.
We missed a few subtle things in the HAProxy stack. Sometimes these were important — we broke Slack’s Daily Active User (DAU) metric for a bit (oops!). There were a lot of minor issues to fix as well. Load balancer behavior is complex and there was no real way around this problem other than time and debugging.
We started the migration without a testing framework for the load balancer configurations. Instead of having automated tests that validated that test URLs routed to the correct endpoint and behaviors related to request and response headers we had… a HAProxy config. Tests are helpful during migrations because they can provide a lot of context about the reasons for expected behaviors. Because we lacked tests, we often had to check in with service owners instead to find out what behavior they relied on.
The Chef resources that we built intentionally supported only a subset of Envoy functionality. This kept our libraries simpler — we only had to consider the features we actually used. The drawback was that each time we wanted to use new Envoy features, we had to add support for them in our Chef libraries. For example, SNI (https) listeners were written part-way through development, when we decided it would be simpler than adding support to the existing listeners. However, when it came to vhost support, we had so much code developed and in-use already that refactoring resources that were in use elsewhere throughout the company would have taken a long time. The vhost support in our Chef library is a hack (and one day soon we will fix it).
To make it safer to change the Envoy resource Chef libraries — in other words, to ensure we didn’t break other teams that were using our libraries — we introduced a comprehensive set of tests that generated those teams’ entire configurations. This made it easy to tell exactly how all our generated Envoy configurations would (or wouldn’t) be impacted when we updated the Envoy Chef resources.
One of the key things in this migration (like any other) is communication. We worked hard to keep everyone informed and aligned with the changes we were making. Our Customer Experience (CE) team was a great partner — they were able to monitor incoming tickets for anything that might indicate users had been impacted as a result of this migration.
What’s next?
Despite occasional minor setbacks, the envoy websocket migration was a great success. We’ve followed up by migrating another critical Slack service, our software client metrics ingestion pipeline — which is isolated from our other ingress load balancers — to Envoy Proxy. We’re nearly done with migrating the internal load balancers for our web and API traffic to Envoy. The final part of this epic migration is to move our (regular, non-websocket) HTTP stack which terminates incoming traffic at our edge, from HAProxy to Envoy; this is also underway.
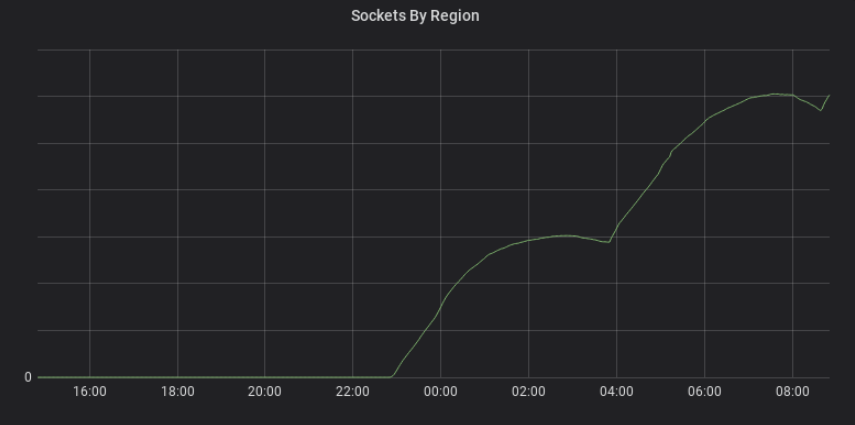
We are now within sight of our final goal of standardization on Envoy Proxy for both our ingress load balancers and our service mesh data plane, which will significantly reduce cognitive load and operational complexity for the team, as well as making Envoy’s advanced features available throughout our load balancing infrastructure. Since migrating to Envoy, we’ve exceeded our previous peak load significantly with no issues.
Huge shoutout to the team — Laura Nolan, Stephan Zuercher, Matthew Girard, David Stern, Mark McBride, John On, Cooper Bethea, V Brennan, Ann Paul, Pramila Singh, Rafael Elvira and Stuart Williams for all the support and contributions to the project.
Want to help Slack solve tough problems and join our growing team? Check out all our open positions and apply today.





