
Abstract
Agent-driven end-to-end (E2E) tests add a new exploratory layer to testing, but should they replace traditional deterministic tests? We ran more than 200 agentic E2E workflows using the Playwright MCP, Playwright CLI, and agent-generated Playwright tests in test workspaces using non-production data to find out how agentic testing could fit into both our and your testing stacks.
1. From Journeys to Goals
Traditional end-to-end tests validate a specific journey through the UI.
click → click → type → assert
Agent-driven tests instead validate whether a goal can be achieved, often expressed as an instruction (e.g. “send a thread message”):
goal → agent adapts → verify result
This difference can be summarized simply:
Tests enforce journeys. Agents verify goals.
Across our agentic test runs, the overall workflow remained consistent (e.g. login → search → result → clear), but the exact sequence of actions varied. In practice, agents took different paths to reach the same outcome:
- Different input methods (clicking a search suggestion vs pressing Enter)
- Different navigation patterns (reopening search vs reusing existing state)
- Additional or skipped steps (extra clicks, snapshots, or intermediate actions)
Agents can still validate intermediate steps when needed, but this flexibility comes with tradeoffs in reliability, cost, and execution time, which we explore in the next sections.
The Problem
Agent-driven E2E testing looks promising, but it raises a real question: can something that costs $15–30 per run and takes over 10 minutes actually fit into modern testing workflows?
At first glance, the answer seems like no. But in 200+ runs, we found they are fundamentally different from traditional tests. They can be highly reliable and have a clear place in the testing stack.
This is largely due to recent advances in large language models, which enable agents to write code, debug failures, and interact directly with user interfaces. These capabilities introduce a new execution model for testing, but where they fit in existing E2E workflows is not always clear.
2. Our Experiment
To understand how agent-driven tests can fit into E2E workflows, we ran 200+ automated executions across multiple configurations to measure reliability, execution speed, and cost.
Execution models
We evaluated three different approaches:
- Agent + Playwright MCP
The agent interacts with the browser through the Playwright MCP, using predefined browser actions (clicking elements, typing input, reading DOM state, etc…) with persistent context (DOM snapshots and logs) - Agent + Playwright CLI
The agent interacts with the browser by running Playwright CLI commands via the shell, executing one step at a time and deciding the next action based on the updated UI state - Generated Playwright Tests
An AI agent generates deterministic Playwright test code from a natural language description, executes it as a standard E2E test, and iteratively refines it until it passes
Experiment Setup
- Agent model (Playwright MCP / CLI): Claude Sonnet 4.5
- Model used for generated Playwright tests: Claude Opus 4.6
- Execution: non-interactive Claude Code (
claude -p) - Browser tooling:
- Playwright MCP
- Playwright CLI
- Environment setup:
- Slack Dev API MCP
- All experiments were conducted in test workspaces using non-production data
Test flows
We used two flows to cover different levels of complexity. These flows were kept consistent across all experiments to allow for direct comparison.
- Thread Reply (simple)
A shorter workflow (~15–20 steps) involving creating a channel, sending a message, replying in a thread, and verifying thread state - Search Discovery (medium complexity)
A longer workflow (~25–30 steps) involving entering search queries, navigating results, moving between views (search, channels, threads), and verifying expected outcomes
Input formats
For agent-driven approaches, we evaluated two input types:
- Natural language (NL)
Detailed, human-readable instructions describing the workflow and expected outcomes (e.g. “reply in a thread, and verify it appears in All Threads”), often written as step-by-step lists - Structured YAML
The same workflow expressed in a structured format, with explicit steps, actions, targets, and expected outcomes
The difference is not the level of detail, but how that detail is represented: natural language requires the agent to interpret and map instructions to actions, while YAML defines that mapping more explicitly.
Each configuration was run 20 times. The experiment matrix below shows the full setup:
Experiment Matrix
| Exp | Execution Model | Input Type | Tools | Thread Reply | Search Discovery |
| 1 | Agent (Playwright MCP) | NL | MCP | 20 | 20 |
| 2 | Agent (Playwright MCP) | YAML | MCP | 20 | 20 |
| 3 | Agent (Playwright CLI) | NL | CLI | 20 | 20 |
| 4 | Agent (Playwright CLI) | YAML | CLI | 20 | 20 |
| 5 | Agent (Generated Tests) | NL | Code | 20 | 20 |
3. What We Observed
Summary of Results
Before diving into individual metrics, here’s a quick look at how the different approaches performed overall across both natural language and YAML-based executions.
| Approach |
Failure rate (thread reply) |
Failure rate (search discovery) |
Avg runtime |
| Agent (Playwright MCP) | 0% | ~12% | ~5–8 min |
| Agent (Playwright CLI) | ~12% | ~20% | ~9–11 min |
| Generated Playwright Tests | ~8% | ~48% | ~3 min |
The following sections break down these results by individual metrics.
Reliability
One of the clearest patterns we saw was how reliability changed as flows became more complex.
Across the agentic Playwright flows, the Playwright MCP was the more reliable configuration, consistently achieving near‑zero failure rates on simple scenarios and remaining within 0–12% on more complex flows. In contrast, the Playwright CLI showed higher failure rates (roughly 12–20%), with many failures caused by execution issues such as authentication handling, navigation timing, and session instability rather than model reasoning.
Generated Playwright tests performed reasonably well on simple flows (~8% failure rate), but degraded significantly on more complex workflows (~48%). These tests were not entirely wrong, as they typically progressed through 70-80% of the flow before breaking on a final interaction or assertion. Failures were primarily caused by variability in UI state and abstraction mismatches. These tests were generated from loosely specified natural language flows and reused existing page object abstractions, which sometimes interfered with precise element targeting in more complex scenarios.
Overall, the reliability gap widened with increasing complexity, suggesting that the agent-native execution models like MCP provide more stable behavior as flows get harder. One likely reason is how each model handles state. MCP keeps a live, stable view of the app, while CLI rebuilds state from snapshots at each step. As flows get longer, small inconsistencies in how the UI is interpreted or timed can accumulate and lead to failures. Another likely factor is in-session context. In MCP-based runs, the agent appears to reuse successful interactions from earlier steps in the same flow, while CLI can feel more like starting from scratch at each step. We didn’t explicitly measure this, but it may also contribute to the gap.
Speed
When it came to speed, generated tests were consistently the fastest.
| Approach | Average Duration |
| Generated Playwright Tests | ~3 minutes |
| Agent (Playwright MCP) | ~5–8 minutes |
| Agent (Playwright CLI) | ~9–11 minutes |
For generated tests, the runtime includes both test generation and execution. Each test was generated once and executed five times, and the numbers above reflect the average duration per run. In practice, the raw execution was much faster: ~32 seconds for thread reply and ~45 seconds for search discovery. In CI environments where tests run repeatedly, the one-time generation cost becomes negligible, allowing deterministic tests to scale more efficiently.
Agent-driven workflows pay this cost on every run. Each step typically involves:
- Observing the UI state
- Reasoning about the next action
- Executing the action and validating the result
Adaptability
Another pattern we saw was how differently agents navigate the UI.
Only about 20% of runs followed the exact same sequence of actions. In most runs, the agent discovered different valid UI paths to reach the same goal.
For example, while still reaching the same final state, the agent might:
- Open menus in a different order
- Select slightly different UI elements
- Use alternate navigation flows
To measure this, we compared action signatures across runs. An action signature is the ordered list of tool calls and UI actions performed by the agent (e.g. API calls, browser clicks, form interactions). Action signatures were normalized before comparison: parameters, wait/snapshot actions, and equivalent tool variants (e.g. fill vs type) were collapsed so that only meaningful differences in the action sequence were counted.
Across runs, most action sequences differed even when the final outcome was correct. This highlights a key difference between approaches: traditional E2E tests enforce a single deterministic journey through the UI, while agents explore the interface and verify whether the goal state can still be reached.
Cost and Where It Comes From
Cost stood out in our experiments. Agent-driven runs were typically $15–30 per execution, compared to much cheaper traditional test runs.
To understand where this cost came from, we analyzed token usage across different execution models by running the same search discovery flow.
| Approach | Tokens |
| MCP (Opus 4.6) | ~3.8M |
| MCP (Sonnet 4.5) | ~3.5M |
| MCP (Haiku 4.5) | ~5.7M |
| CLI (Opus 4.6) | ~6M |
| Code Gen (Opus 4.6) | ~7M |
The first thing that stood out was that how the agent was executed mattered more than which model powered it. Haiku did use more tokens than Sonnet or Opus in our runs, but all of the MCP-based approaches still used fewer tokens overall than the CLI and Code Gen approaches for the same flow.
To understand why, we looked at how Claude Code executes agent sessions. The underlying API is stateless and every turn re-sends the full system prompt plus the entire conversation history. This means cost is not driven by model output, which is negligible, but by how quickly context accumulates and how many turns the agent takes to complete the flow.
| Approach | Turns |
| MCP (Opus 4.6) | ~40 |
| MCP (Sonnet 4.5) | ~40 |
| MCP (Haiku 4.5) | ~60 |
| CLI (Opus 4.6) | ~85 |
| Code Gen (Opus 4.6) | ~70 |
On average, CLI took 85 turns compared to MCP’s ~40-60 because each browser interaction was split across multiple commands, such as actions, waits, snapshots, reads, and element lookups. MCP combined interaction and state return into a single round trip. Each additional turn pays the full system prompt tax plus re-sends all prior conversation context.
What fills that context? For MCP and CLI approaches, browser snapshots are the primary payload. Playwright MCP returns accessibility tree snapshots as part of its browser interaction responses, and these accumulate in the conversation window across all subsequent turns. For Code Gen, the accumulated context comes from test runner output containing full error traces, assertion failures, and DOM state on each retry cycle.
In our analysis, the majority of the cost was retransmission of previously seen content. Only a small fraction of tokens represented new information per turn. The biggest factors affecting cost are turn count and context growth rate rather than model reasoning or output generation.
At this stage, we focused primarily on reliability and behavior, so token usage was not optimized. Opportunities to reduce cost include prompt caching, context compaction, and reducing snapshot frequency.
Due to the cost, agent-driven testing may currently be better suited for targeted debugging or exploratory testing than for high-frequency CI execution, although cost may improve with future models and tooling.
Infrastructure Matters (MCP vs CLI)
Another important takeaway was how much the execution environment affected reliability, not just the model itself.
| Approach | Failure rate |
| Agent (Playwright MCP) | 0–12% |
| Agent (Playwright CLI) | 12–20% |
Most failures in CLI-based runs came from authentication and navigation issues (sign-in errors, timeouts, and session instability), suggesting that many failures were caused by the execution layer rather than the agent’s reasoning.
The Playwright MCP provides structured browser primitives and tighter integration with the agent’s tool-calling workflow, while CLI-based execution introduces additional layers between the agent and the browser.
Parallelization also differed. MCP runs were easy to execute concurrently, while CLI-based runs were difficult to parallelize in our setup and were mostly executed sequentially.
These results suggest that reliability, speed, and cost depend not just on the model, but also on how stable and well-designed the execution environment is.
Execution Capability Boundaries
Our experiments focused on single-session UI workflows. More complex scenarios, such as cross-workspace flows or workflows that open multiple browser windows, introduce a different set of challenges where the choice of execution model may matter as much as the agent itself.
Both MCP and CLI-based approaches could support these workflows, but with different tradeoffs. MCP may run into cost issues as observation loops grow over longer flows, while CLI-based approaches may introduce additional coordination complexity when managing multiple browser sessions, on top of the higher token usage observed in our experiments. We did not explore these scenarios here, but they are an important consideration for teams evaluating agent-driven testing.
4. Where Agentic Testing Fits in the Testing Pyramid
So where does agent-driven testing actually fit?
Rather than replacing existing approaches, it adds a new capability on top of them.
Deterministic E2E Tests
Best suited for fast, repeatable regression checks in CI.
- Human-written or AI-generated tests
- Fast, repeatable, and CI-friendly
- Low operational cost
- Enforce a specific journey through the UI
Agentic Testing
Agent-driven workflows operate differently from deterministic tests. Instead of executing a predefined script, agents operate from a goal: they observe the UI, reason about the current state, and determine how to reach the desired outcome.
- Exploring complex UI behavior
- Debugging flaky workflows
- Reproducing production bugs
Testing Pyramid with Agentic Layer
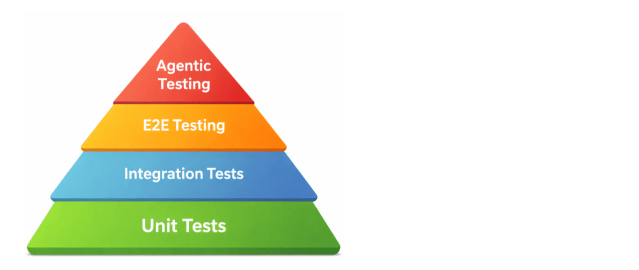
From a system perspective, agentic testing still operates at the same level as E2E tests, validating real user workflows through the UI. The difference is in how those workflows are executed.
For this reason, the most effective testing strategies of the future will combine both. Deterministic tests provide a stable foundation for CI, while agentic testing adds a distinct layer at the top of the testing pyramid for exploration, debugging, and validating complex behaviors.
5. Acknowledgements
Huge thanks to the DevXP AI team for building and supporting tools like Claude Code, as well as the metrics infrastructure that made these experiments possible. That foundation made it much easier to run, analyze, and iterate on hundreds of executions.
Special thanks to our managers, Dave Harrington and Vani Anantha, for supporting experiments at a scale that definitely kept the token counters busy, and briefly put us on our internal token usage leaderboard.
We also want to thank the Frontend Test Frameworks team for their help throughout the process, from early ideas to validation and feedback. Special thanks to Lucy Cheng, Natalie Stormann, Roopa Thanisraj, Ilaria Varriale, and Crescencio Zul for their thoughtful input and support along the way.
Interested in solving real problems, making developers’ lives easier, or just building some pretty cool tools? If this kind of work excites you, whether it’s pushing the boundaries of testing or building agent-driven systems and rethinking developer workflows, we’re hiring.
Apply now





